Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Audio Spatialization with Correspondence Classifier
Paper and Code
May 14, 2019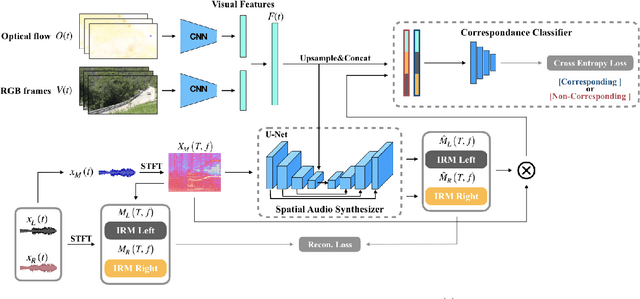


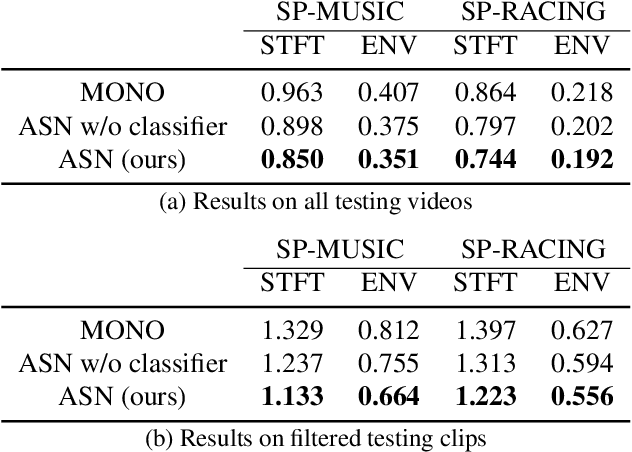
Spatial audio is an essential medium to audiences for 3D visual and auditory experience. However, the recording devices and techniques are expensive or inaccessible to the general public. In this work, we propose a self-supervised audio spatialization network that can generate spatial audio given the corresponding video and monaural audio. To enhance spatialization performance, we use an auxiliary classifier to classify ground-truth videos and those with audio where the left and right channels are swapped. We collect a large-scale video dataset with spatial audio to validate the proposed method. Experimental results demonstrate the effectiveness of the proposed model on the audio spatialization task.
* ICIP 2019
View paper on