 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIT++: Diverse Image-to-Image Translation via Disentangled Representations
Paper and Code

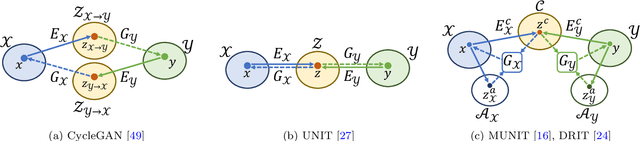
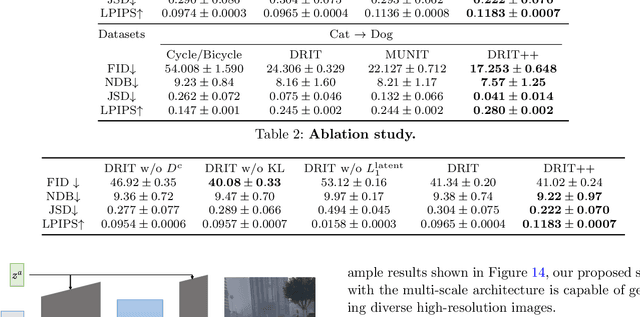
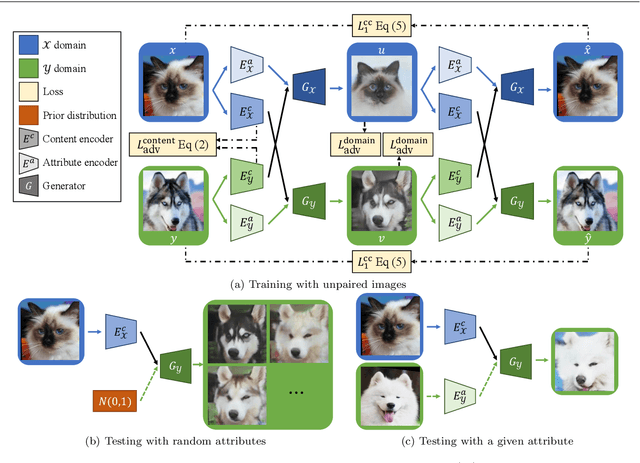
Image-to-image translation aims to learn the mapping between two visual domains. There are two main challenges for this task: 1) lack of aligned training pairs and 2) multiple possible outputs from a single input image. In this work, we present an approach based on disentangled representation for generating diverse outputs without paired training images. To synthesize diverse outputs, we propose to embed images onto two spaces: a domain-invariant content space capturing shared information across domains and a domain-specific attribute space. Our model takes the encoded content features extracted from a given input and attribute vectors sampled from the attribute space to synthesize diverse outputs at test time. To handle unpaired training data, we introduce a cross-cycle consistency loss based on disentangled representations. Qualitative results show that our model can generate diverse and realistic images on a wide range of tasks without paired training data. For quantitative evaluations, we measure realism with user study and Fr\'{e}chet inception distance, and measure diversity with the perceptual distance metric, Jensen-Shannon divergence, and number of statistically-different bins.