 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVORNet: Spatio-temporally Consistent Video Inpainting for Object Removal
Paper and Code
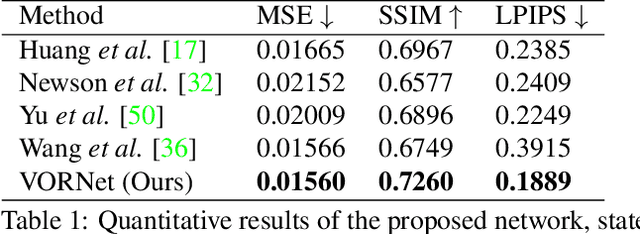
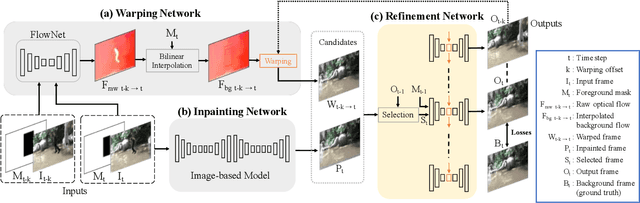
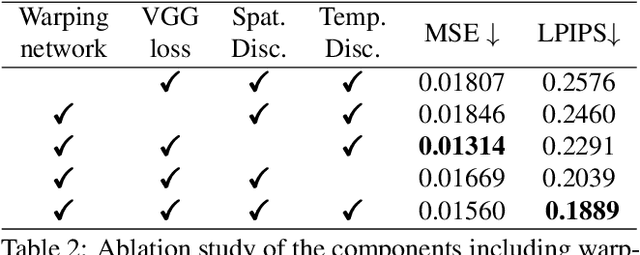
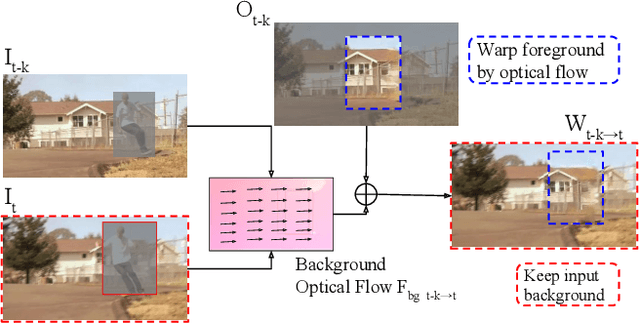
Video object removal is a challenging task in video processing that often requires massive human efforts. Given the mask of the foreground object in each frame, the goal is to complete (inpaint) the object region and generate a video without the target object. While recently deep learning based methods have achieved great success on the image inpainting task, they often lead to inconsistent results between frames when applied to videos. In this work, we propose a novel learning-based Video Object Removal Network (VORNet) to solve the video object removal task in a spatio-temporally consistent manner, by combining the optical flow warping and image-based inpainting model. Experiments are done on our Synthesized Video Object Removal (SVOR) dataset based on the YouTube-VOS video segmentation dataset, and both the objective and subjective evaluation demonstrate that our VORNet generates more spatially and temporally consistent videos compared with existing methods.