 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of deep learning techniques in non-contrast computed tomography pulmonary angiogram for pulmonary embolism diagnosis
Jan 01, 2026Pulmonary embolism is a life-threatening disease, early detection and treatment can significantly reduce mortality. In recent years, many studies have been using deep learning in the diagnosis of pulmonary embolism with contrast medium computed tomography pulmonary angiography, but the contrast medium is likely to cause acute kidney injury in patients with pulmonary embolism and chronic kidney disease, and the contrast medium takes time to work, patients with acute pulmonary embolism may miss the golden treatment time. This study aims to use deep learning techniques to automatically classify pulmonary embolism in CT images without contrast medium by using a 3D convolutional neural network model. The deep learning model used in this study had a significant impact on the pulmonary embolism classification of computed tomography images without contrast with 85\% accuracy and 0.84 AUC, which confirms the feasibility of the model in the diagnosis of pulmonary embolism.
MenTeR: A fully-automated Multi-agenT workflow for end-to-end RF/Analog Circuits Netlist Design
May 29, 2025RF/Analog design is essential for bridging digital technologies with real-world signals, ensuring the functionality and reliability of a wide range of electronic systems. However, analog design procedures are often intricate, time-consuming and reliant on expert intuition, and hinder the time and cost efficiency of circuit development. To overcome the limitations of the manual circuit design, we introduce MenTeR - a multiagent workflow integrated into an end-to-end analog design framework. By employing multiple specialized AI agents that collaboratively address different aspects of the design process, such as specification understanding, circuit optimization, and test bench validation, MenTeR reduces the dependency on frequent trial-and-error-style intervention. MenTeR not only accelerates the design cycle time but also facilitates a broader exploration of the design space, demonstrating robust capabilities in handling real-world analog systems. We believe that MenTeR lays the groundwork for future "RF/Analog Copilots" that can collaborate seamlessly with human designers.
Retrieval-Augmented Language Model for Extreme Multi-Label Knowledge Graph Link Prediction
May 21, 2024



Extrapolation in Large language models (LLMs) for open-ended inquiry encounters two pivotal issues: (1) hallucination and (2) expensive training costs. These issues present challenges for LLMs in specialized domains and personalized data, requiring truthful responses and low fine-tuning costs. Existing works attempt to tackle the problem by augmenting the input of a smaller language model with information from a knowledge graph (KG). However, they have two limitations: (1) failing to extract relevant information from a large one-hop neighborhood in KG and (2) applying the same augmentation strategy for KGs with different characteristics that may result in low performance. Moreover, open-ended inquiry typically yields multiple responses, further complicating extrapolation. We propose a new task, the extreme multi-label KG link prediction task, to enable a model to perform extrapolation with multiple responses using structured real-world knowledge. Our retriever identifies relevant one-hop neighbors by considering entity, relation, and textual data together. Our experiments demonstrate that (1) KGs with different characteristics require different augmenting strategies, and (2) augmenting the language model's input with textual data improves task performance significantly. By incorporating the retrieval-augmented framework with KG, our framework, with a small parameter size, is able to extrapolate based on a given KG. The code can be obtained on GitHub: https://github.com/exiled1143/Retrieval-Augmented-Language-Model-for-Multi-Label-Knowledge-Graph-Link-Prediction.git
Screentone-Aware Manga Super-Resolution Using DeepLearning
May 15, 2023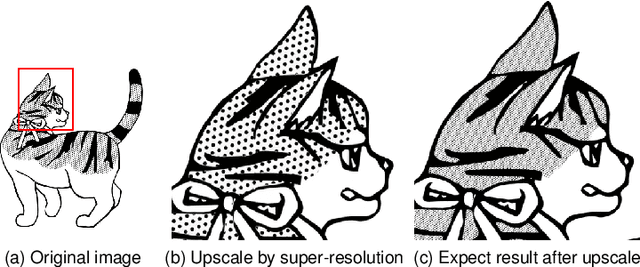
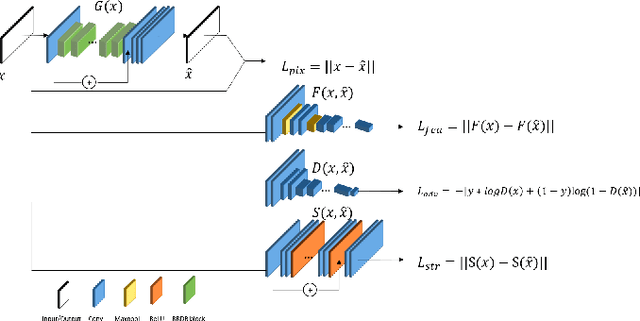
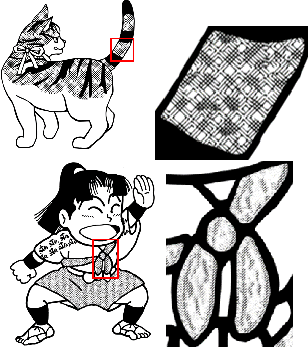

Manga, as a widely beloved form of entertainment around the world, have shifted from paper to electronic screens with the proliferation of handheld devices. However, as the demand for image quality increases with screen development, high-quality images can hinder transmission and affect the viewing experience. Traditional vectorization methods require a significant amount of manual parameter adjustment to process screentone. Using deep learning, lines and screentone can be automatically extracted and image resolution can be enhanced. Super-resolution can convert low-resolution images to high-resolution images while maintaining low transmission rates and providing high-quality results. However, traditional Super Resolution methods for improving manga resolution do not consider the meaning of screentone density, resulting in changes to screentone density and loss of meaning. In this paper, we aims to address this issue by first classifying the regions and lines of different screentone in the manga using deep learning algorithm, then using corresponding super-resolution models for quality enhancement based on the different classifications of each block, and finally combining them to obtain images that maintain the meaning of screentone and lines in the manga while improving image resolution.
GenISP: Neural ISP for Low-Light Machine Cognition
May 07, 2022
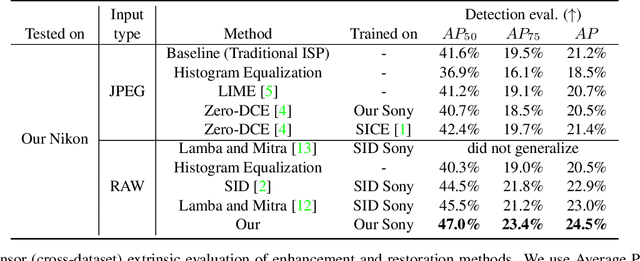


Object detection in low-light conditions remains a challenging but important problem with many practical implications. Some recent works show that, in low-light conditions, object detectors using raw image data are more robust than detectors using image data processed by a traditional ISP pipeline. To improve detection performance in low-light conditions, one can fine-tune the detector to use raw image data or use a dedicated low-light neural pipeline trained with paired low- and normal-light data to restore and enhance the image. However, different camera sensors have different spectral sensitivity and learning-based models using raw images process data in the sensor-specific color space. Thus, once trained, they do not guarantee generalization to other camera sensors. We propose to improve generalization to unseen camera sensors by implementing a minimal neural ISP pipeline for machine cognition, named GenISP, that explicitly incorporates Color Space Transformation to a device-independent color space. We also propose a two-stage color processing implemented by two image-to-parameter modules that take down-sized image as input and regress global color correction parameters. Moreover, we propose to train our proposed GenISP under the guidance of a pre-trained object detector and avoid making assumptions about perceptual quality of the image, but rather optimize the image representation for machine cognition. At the inference stage, GenISP can be paired with any object detector. We perform extensive experiments to compare our method to other low-light image restoration and enhancement methods in an extrinsic task-based evaluation and validate that GenISP can generalize to unseen sensors and object detectors. Finally, we contribute a low-light dataset of 7K raw images annotated with 46K bounding boxes for task-based benchmarking of future low-light image restoration and object detection.
NOD: Taking a Closer Look at Detection under Extreme Low-Light Conditions with Night Object Detection Dataset
Oct 20, 2021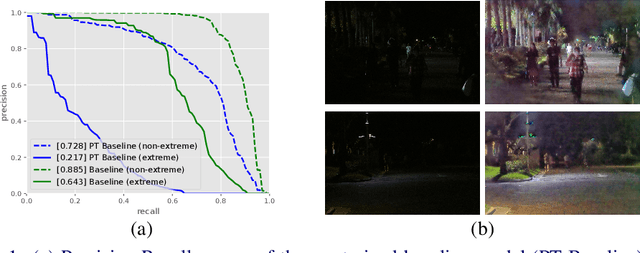
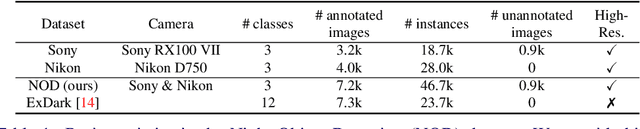
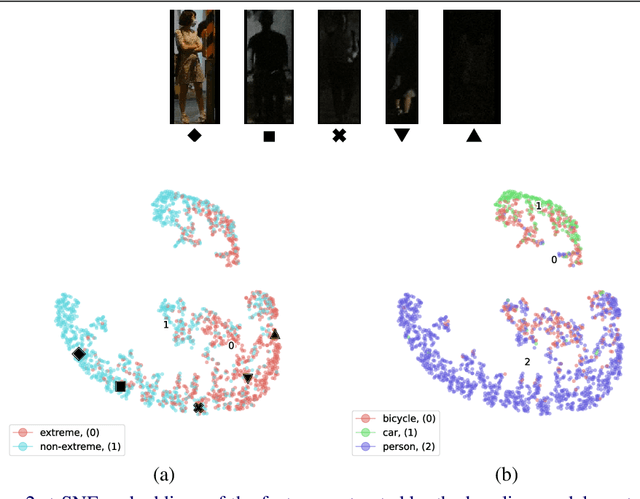
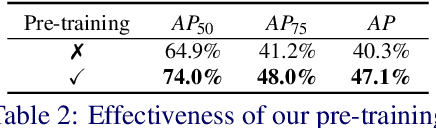
Recent work indicates that, besides being a challenge in producing perceptually pleasing images, low light proves more difficult for machine cognition than previously thought. In our work, we take a closer look at object detection in low light. First, to support the development and evaluation of new methods in this domain, we present a high-quality large-scale Night Object Detection (NOD) dataset showing dynamic scenes captured on the streets at night. Next, we directly link the lighting conditions to perceptual difficulty and identify what makes low light problematic for machine cognition. Accordingly, we provide instance-level annotation for a subset of the dataset for an in-depth evaluation of future methods. We also present an analysis of the baseline model performance to highlight opportunities for future research and show that low light is a non-trivial problem that requires special attention from the researchers. Further, to address the issues caused by low light, we propose to incorporate an image enhancement module into the object detection framework and two novel data augmentation techniques. Our image enhancement module is trained under the guidance of the object detector to learn image representation optimal for machine cognition rather than for the human visual system. Finally, experimental results confirm that the proposed method shows consistent improvement of the performance on low-light datasets.
GrateTile: Efficient Sparse Tensor Tiling for CNN Processing
Sep 18, 2020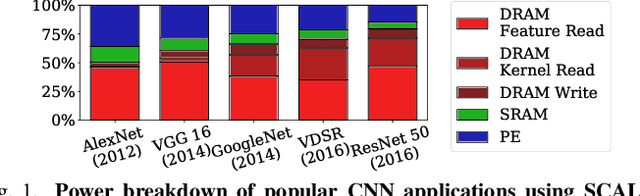
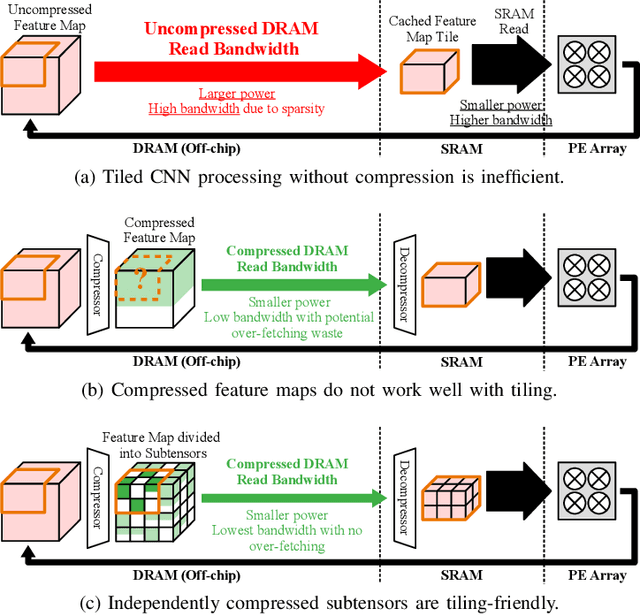
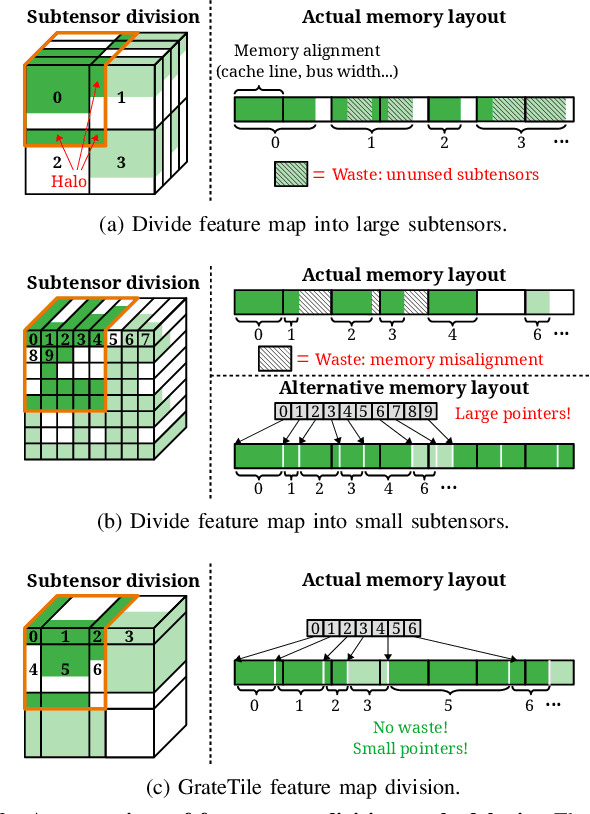
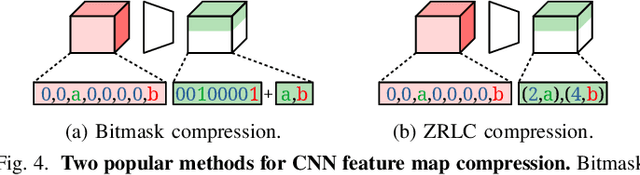
We propose GrateTile, an efficient, hardwarefriendly data storage scheme for sparse CNN feature maps (activations). It divides data into uneven-sized subtensors and, with small indexing overhead, stores them in a compressed yet randomly accessible format. This design enables modern CNN accelerators to fetch and decompressed sub-tensors on-the-fly in a tiled processing manner. GrateTile is suitable for architectures that favor aligned, coalesced data access, and only requires minimal changes to the overall architectural design. We simulate GrateTile with state-of-the-art CNNs and show an average of 55% DRAM bandwidth reduction while using only 0.6% of feature map size for indexing storage.
xCos: An Explainable Cosine Metric for Face Verification Task
Mar 11, 2020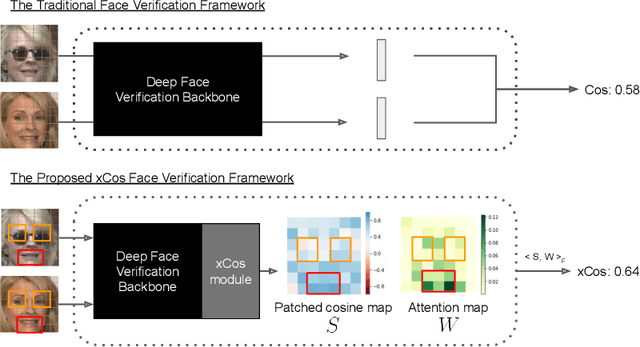
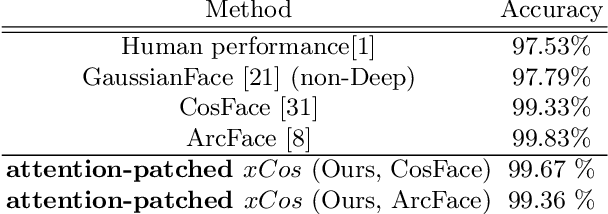
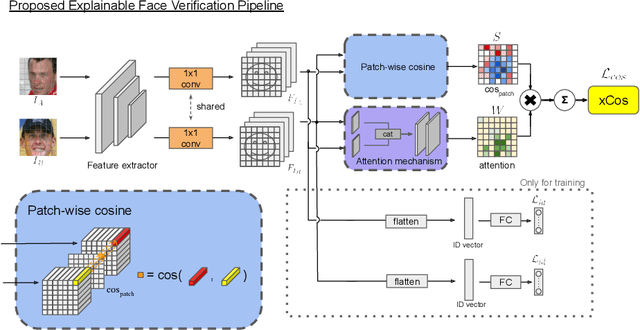
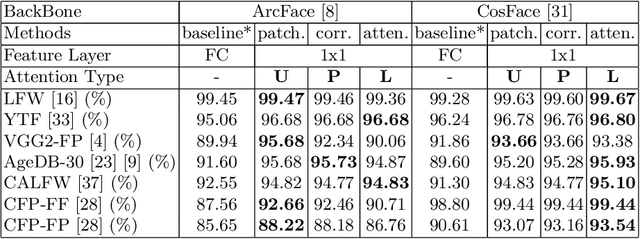
We study the XAI (explainable AI) on the face recognition task, particularly the face verification here. Face verification is a crucial task in recent days and it has been deployed to plenty of applications, such as access control, surveillance, and automatic personal log-on for mobile devices. With the increasing amount of data, deep convolutional neural networks can achieve very high accuracy for the face verification task. Beyond exceptional performances, deep face verification models need more interpretability so that we can trust the results they generate. In this paper, we propose a novel similarity metric, called explainable cosine ($xCos$), that comes with a learnable module that can be plugged into most of the verification models to provide meaningful explanations. With the help of $xCos$, we can see which parts of the 2 input faces are similar, where the model pays its attention to, and how the local similarities are weighted to form the output $xCos$ score. We demonstrate the effectiveness of our proposed method on LFW and various competitive benchmarks, resulting in not only providing novel and desiring model interpretability for face verification but also ensuring the accuracy as plugging into existing face recognition models.
Computation-Performance Optimization of Convolutional Neural Networks with Redundant Kernel Removal
Apr 10, 2018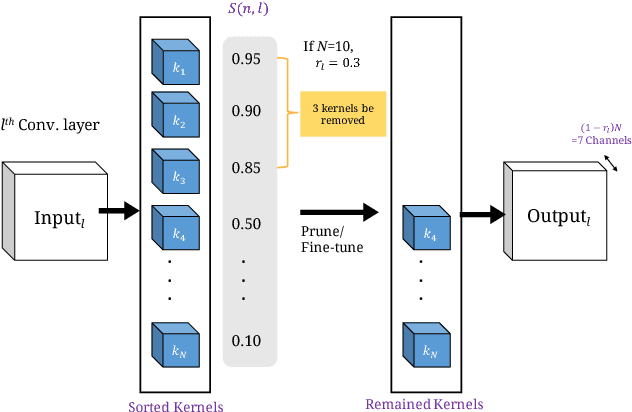
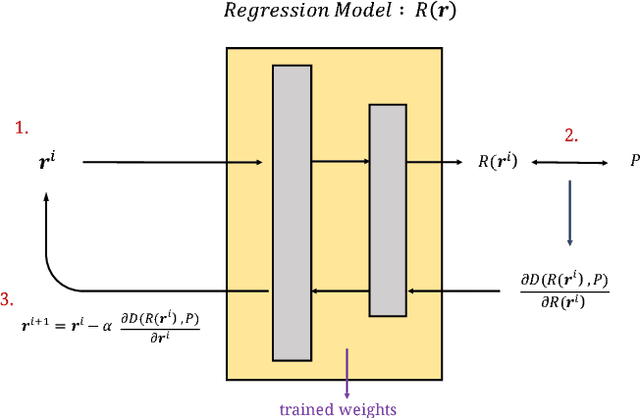
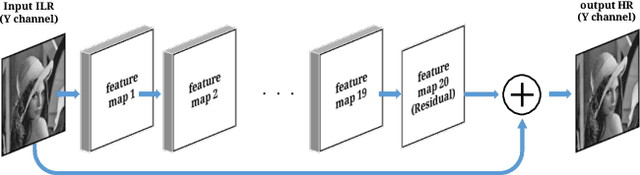
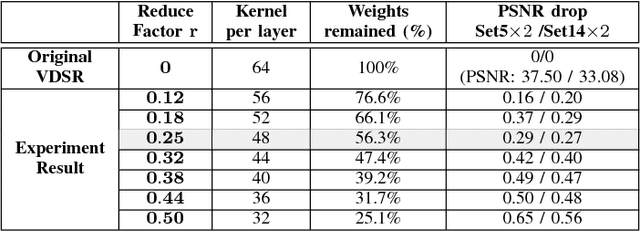
Deep Convolutional Neural Networks (CNNs) are widely employed in modern computer vision algorithms, where the input image is convolved iteratively by many kernels to extract the knowledge behind it. However, with the depth of convolutional layers getting deeper and deeper in recent years, the enormous computational complexity makes it difficult to be deployed on embedded systems with limited hardware resources. In this paper, we propose two computation-performance optimization methods to reduce the redundant convolution kernels of a CNN with performance and architecture constraints, and apply it to a network for super resolution (SR). Using PSNR drop compared to the original network as the performance criterion, our method can get the optimal PSNR under a certain computation budget constraint. On the other hand, our method is also capable of minimizing the computation required under a given PSNR drop.