 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrUMAn: Trope Understanding in Movies and Animations
Aug 21, 2021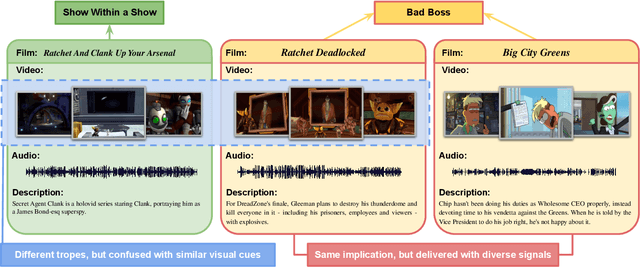
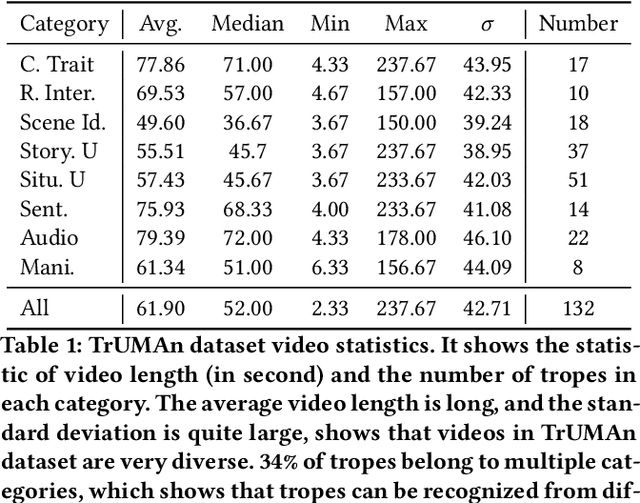

Understanding and comprehending video content is crucial for many real-world applications such as search and recommendation systems. While recent progress of deep learning has boosted performance on various tasks using visual cues, deep cognition to reason intentions, motivation, or causality remains challenging. Existing datasets that aim to examine video reasoning capability focus on visual signals such as actions, objects, relations, or could be answered utilizing text bias. Observing this, we propose a novel task, along with a new dataset: Trope Understanding in Movies and Animations (TrUMAn), with 2423 videos associated with 132 tropes, intending to evaluate and develop learning systems beyond visual signals. Tropes are frequently used storytelling devices for creative works. By coping with the trope understanding task and enabling the deep cognition skills of machines, data mining applications and algorithms could be taken to the next level. To tackle the challenging TrUMAn dataset, we present a Trope Understanding and Storytelling (TrUSt) with a new Conceptual Storyteller module, which guides the video encoder by performing video storytelling on a latent space. Experimental results demonstrate that state-of-the-art learning systems on existing tasks reach only 12.01% of accuracy with raw input signals. Also, even in the oracle case with human-annotated descriptions, BERT contextual embedding achieves at most 28% of accuracy. Our proposed TrUSt boosts the model performance and reaches 13.94% performance. We also provide detailed analysis to pave the way for future research. TrUMAn is publicly available at:https://www.cmlab.csie.ntu.edu.tw/project/trope
Situation and Behavior Understanding by Trope Detection on Films
Jan 19, 2021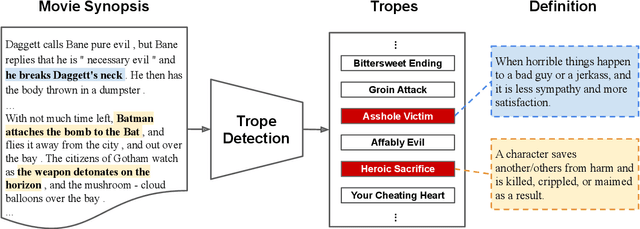
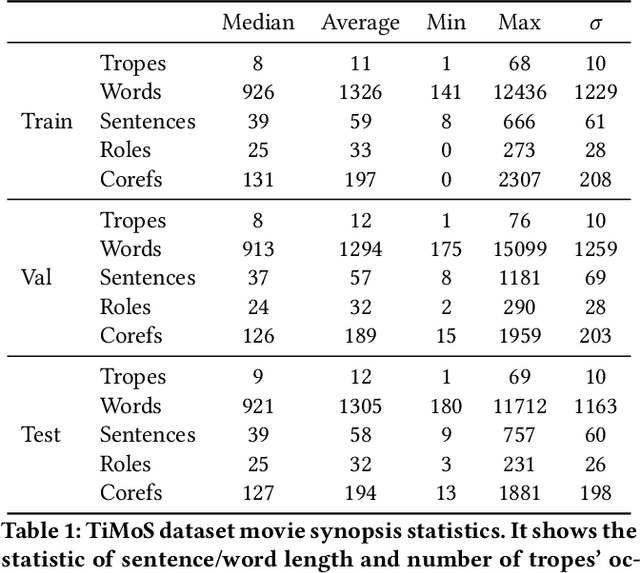
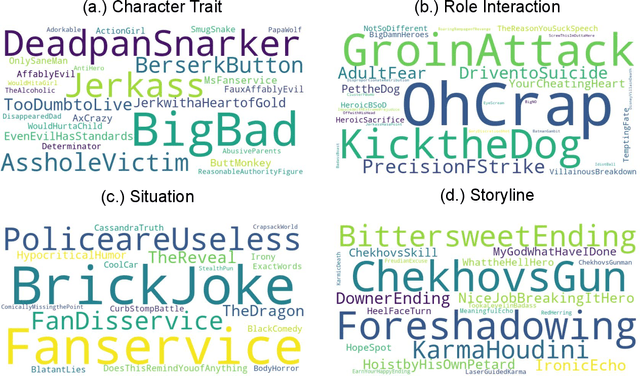
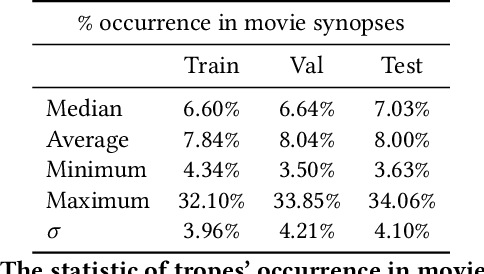
The human ability of deep cognitive skills are crucial for the development of various real-world applications that process diverse and abundant user generated input. While recent progress of deep learning and natural language processing have enabled learning system to reach human performance on some benchmarks requiring shallow semantics, such human ability still remains challenging for even modern contextual embedding models, as pointed out by many recent studies. Existing machine comprehension datasets assume sentence-level input, lack of casual or motivational inferences, or could be answered with question-answer bias. Here, we present a challenging novel task, trope detection on films, in an effort to create a situation and behavior understanding for machines. Tropes are storytelling devices that are frequently used as ingredients in recipes for creative works. Comparing to existing movie tag prediction tasks, tropes are more sophisticated as they can vary widely, from a moral concept to a series of circumstances, and embedded with motivations and cause-and-effects. We introduce a new dataset, Tropes in Movie Synopses (TiMoS), with 5623 movie synopses and 95 different tropes collecting from a Wikipedia-style database, TVTropes. We present a multi-stream comprehension network (MulCom) leveraging multi-level attention of words, sentences, and role relations. Experimental result demonstrates that modern models including BERT contextual embedding, movie tag prediction systems, and relational networks, perform at most 37% of human performance (23.97/64.87) in terms of F1 score. Our MulCom outperforms all modern baselines, by 1.5 to 5.0 F1 score and 1.5 to 3.0 mean of average precision (mAP) score. We also provide a detailed analysis and human evaluation to pave ways for future research.
Image Inspired Poetry Generation in XiaoIce
Aug 09, 2018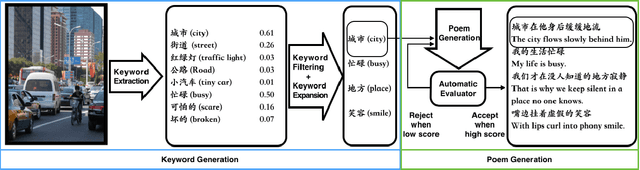
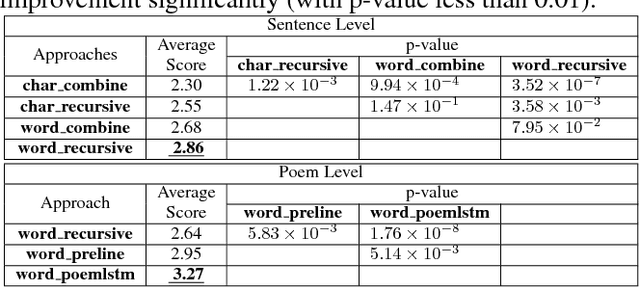
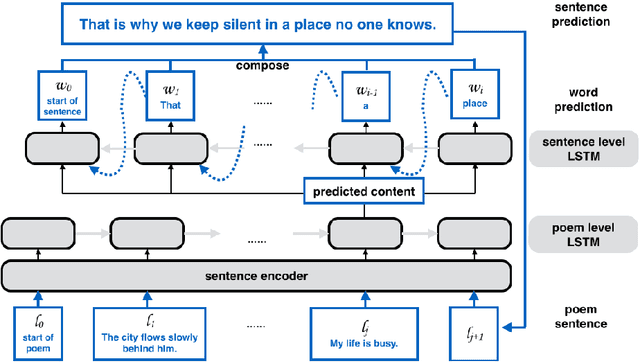
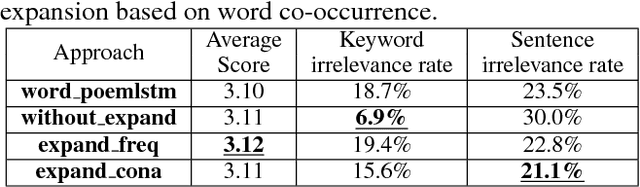
Vision is a common source of inspiration for poetry. The objects and the sentimental imprints that one perceives from an image may lead to various feelings depending on the reader. In this paper, we present a system of poetry generation from images to mimic the process. Given an image, we first extract a few keywords representing objects and sentiments perceived from the image. These keywords are then expanded to related ones based on their associations in human written poems. Finally, verses are generated gradually from the keywords using recurrent neural networks trained on existing poems. Our approach is evaluated by human assessors and compared to other generation baselines. The results show that our method can generate poems that are more artistic than the baseline methods. This is one of the few attempts to generate poetry from images. By deploying our proposed approach, XiaoIce has already generated more than 12 million poems for users since its release in July 2017. A book of its poems has been published by Cheers Publishing, which claimed that the book is the first-ever poetry collection written by an AI in human history.