 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClear Minds Think Alike: What Makes LLM Fine-tuning Robust? A Study of Token Perplexity
Jan 24, 2025



Maintaining consistent model performance across domains is a fundamental challenge in machine learning. While recent work has explored using LLM-generated data for fine-tuning, its impact on cross-domain generalization remains poorly understood. In this paper, we present a systematic analysis revealing that fine-tuning with LLM-generated data not only improves target task performance but also reduces out-of-domain (OOD) degradation compared to fine-tuning with ground truth data. Through analyzing the data sequence in tasks of various domains, we demonstrate that this enhanced OOD robustness stems from a reduced prevalence of high perplexity tokens in LLM-generated sequences. Following this hypothesis we showed that masking high perplexity tokens in ground truth training data also achieves similar OOD preservation comparable to using LLM-generated data. Extensive experiments across diverse model architectures and scales, including Gemma2-2B, Mistral-7B and Llama3-8B, corroborate the consistency of our findings. To the best of our knowledge, this work provides the first mechanistic explanation for the superior OOD robustness conferred by LLM-generated training data, offering valuable insights for developing more robust fine-tuning strategies.
I Need Help! Evaluating LLM's Ability to Ask for Users' Support: A Case Study on Text-to-SQL Generation
Jul 20, 2024In this study, we explore the proactive ability of LLMs to seek user support, using text-to-SQL generation as a case study. We propose metrics to evaluate the trade-off between performance improvements and user burden, and investigate whether LLMs can determine when to request help and examine their performance with varying levels of information availability. Our experiments reveal that without external feedback, many LLMs struggle to recognize their need for additional support. Our findings highlight the importance of external signals and provide insights for future research on improving support-seeking strategies.
Image Inspired Poetry Generation in XiaoIce
Aug 09, 2018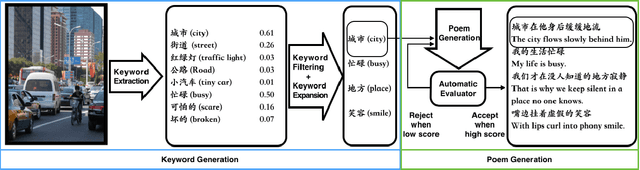
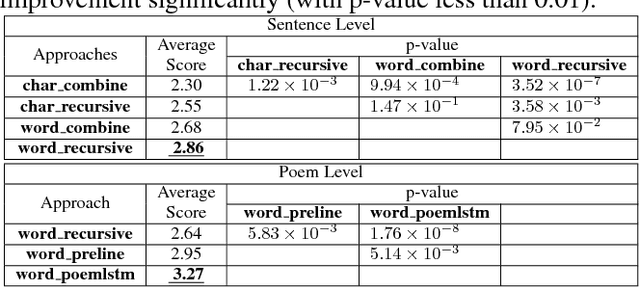
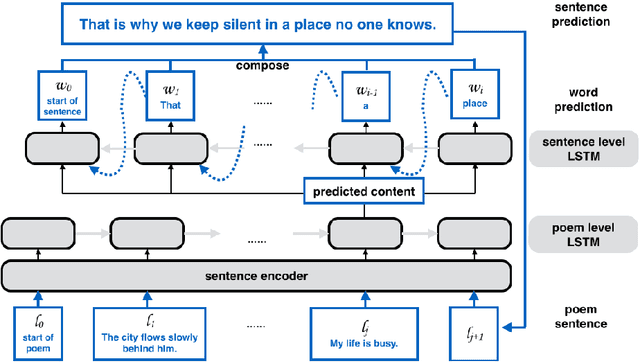
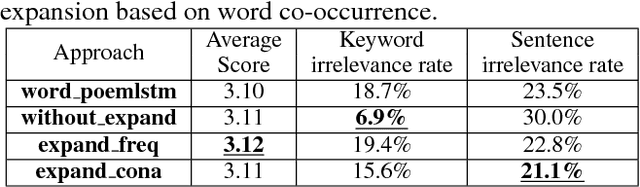
Vision is a common source of inspiration for poetry. The objects and the sentimental imprints that one perceives from an image may lead to various feelings depending on the reader. In this paper, we present a system of poetry generation from images to mimic the process. Given an image, we first extract a few keywords representing objects and sentiments perceived from the image. These keywords are then expanded to related ones based on their associations in human written poems. Finally, verses are generated gradually from the keywords using recurrent neural networks trained on existing poems. Our approach is evaluated by human assessors and compared to other generation baselines. The results show that our method can generate poems that are more artistic than the baseline methods. This is one of the few attempts to generate poetry from images. By deploying our proposed approach, XiaoIce has already generated more than 12 million poems for users since its release in July 2017. A book of its poems has been published by Cheers Publishing, which claimed that the book is the first-ever poetry collection written by an AI in human history.
Audio Word2Vec: Unsupervised Learning of Audio Segment Representations using Sequence-to-sequence Autoencoder
Jun 11, 2016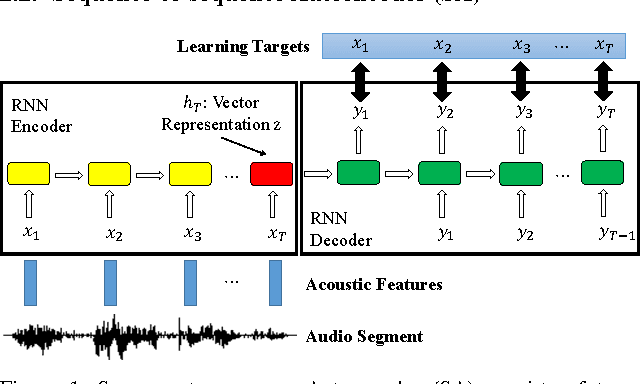
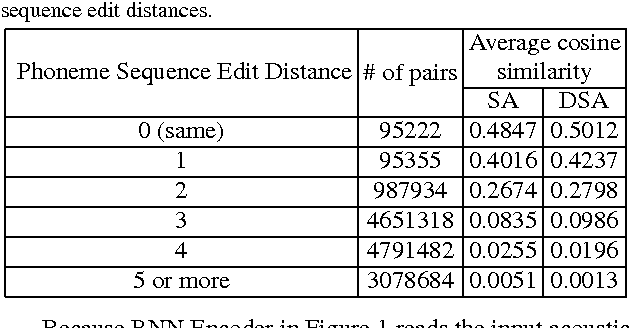
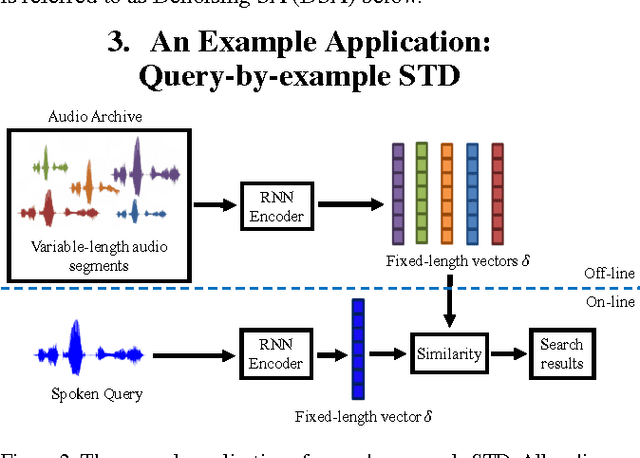
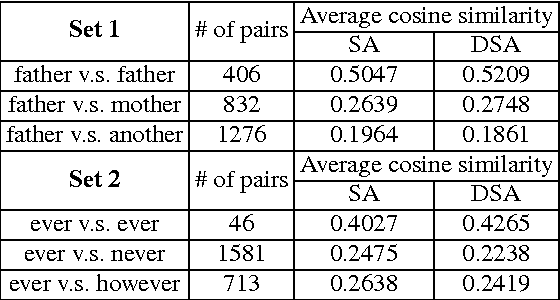
The vector representations of fixed dimensionality for words (in text) offered by Word2Vec have been shown to be very useful in many application scenarios, in particular due to the semantic information they carry. This paper proposes a parallel version, the Audio Word2Vec. It offers the vector representations of fixed dimensionality for variable-length audio segments. These vector representations are shown to describe the sequential phonetic structures of the audio segments to a good degree, with very attractive real world applications such as query-by-example Spoken Term Detection (STD). In this STD application, the proposed approach significantly outperformed the conventional Dynamic Time Warping (DTW) based approaches at significantly lower computation requirements. We propose unsupervised learning of Audio Word2Vec from audio data without human annotation using Sequence-to-sequence Audoencoder (SA). SA consists of two RNNs equipped with Long Short-Term Memory (LSTM) units: the first RNN (encoder) maps the input audio sequence into a vector representation of fixed dimensionality, and the second RNN (decoder) maps the representation back to the input audio sequence. The two RNNs are jointly trained by minimizing the reconstruction error. Denoising Sequence-to-sequence Autoencoder (DSA) is furthered proposed offering more robust learning.