 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossDTR: Cross-view and Depth-guided Transformers for 3D Object Detection
Oct 12, 2022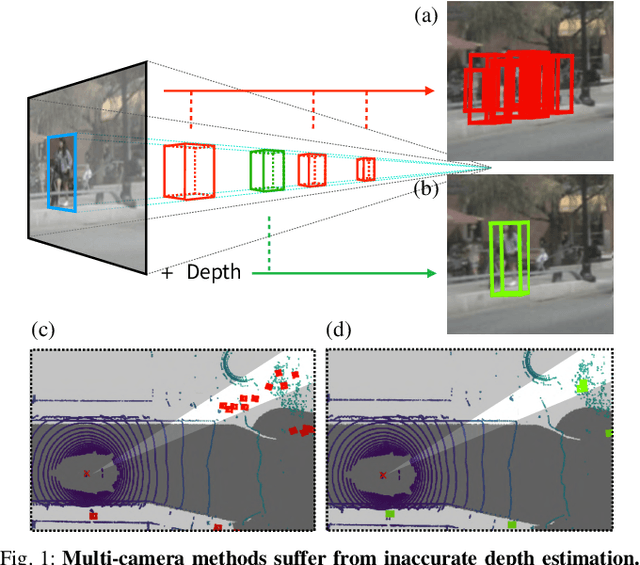
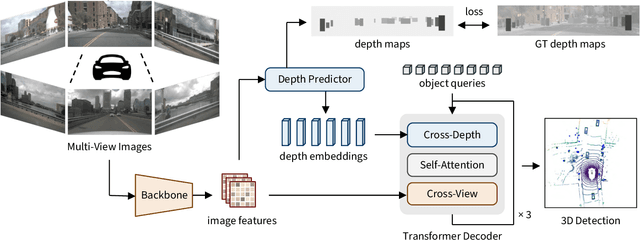
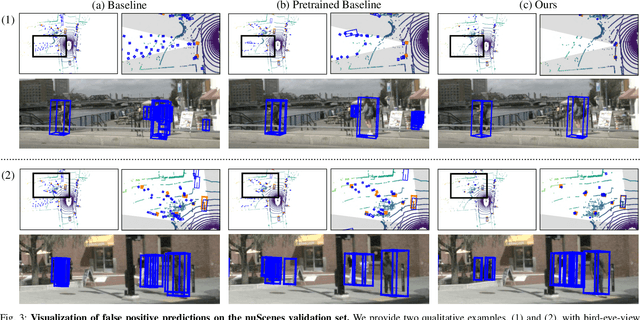
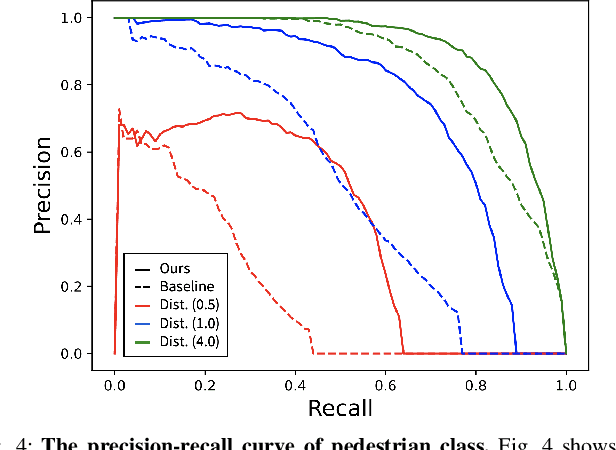
To achieve accurate 3D object detection at a low cost for autonomous driving, many multi-camera methods have been proposed and solved the occlusion problem of monocular approaches. However, due to the lack of accurate estimated depth, existing multi-camera methods often generate multiple bounding boxes along a ray of depth direction for difficult small objects such as pedestrians, resulting in an extremely low recall. Furthermore, directly applying depth prediction modules to existing multi-camera methods, generally composed of large network architectures, cannot meet the real-time requirements of self-driving applications. To address these issues, we propose Cross-view and Depth-guided Transformers for 3D Object Detection, CrossDTR. First, our lightweight depth predictor is designed to produce precise object-wise sparse depth maps and low-dimensional depth embeddings without extra depth datasets during supervision. Second, a cross-view depth-guided transformer is developed to fuse the depth embeddings as well as image features from cameras of different views and generate 3D bounding boxes. Extensive experiments demonstrated that our method hugely surpassed existing multi-camera methods by 10 percent in pedestrian detection and about 3 percent in overall mAP and NDS metrics. Also, computational analyses showed that our method is 5 times faster than prior approaches. Our codes will be made publicly available at https://github.com/sty61010/CrossDTR.
3rd Place Solution for NeurIPS 2021 Shifts Challenge: Vehicle Motion Prediction
Dec 02, 2021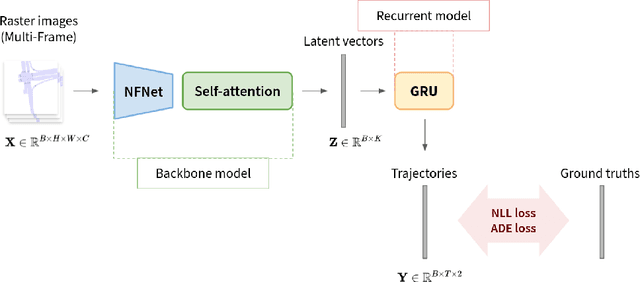
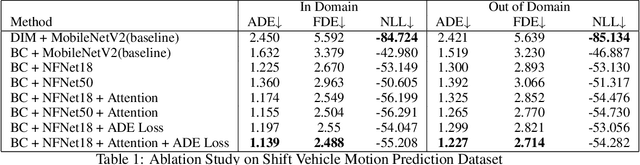
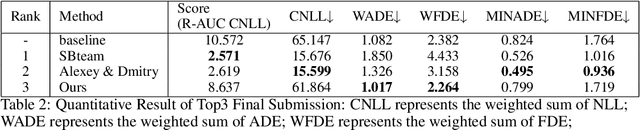
Shifts Challenge: Robustness and Uncertainty under Real-World Distributional Shift is a competition held by NeurIPS 2021. The objective of this competition is to search for methods to solve the motion prediction problem in cross-domain. In the real world dataset, It exists variance between input data distribution and ground-true data distribution, which is called the domain shift problem. In this report, we propose a new architecture inspired by state of the art papers. The main contribution is the backbone architecture with self-attention mechanism and predominant loss function. Subsequently, we won 3rd place as shown on the leaderboard.
Learning from 2D: Pixel-to-Point Knowledge Transfer for 3D Pretraining
Apr 10, 2021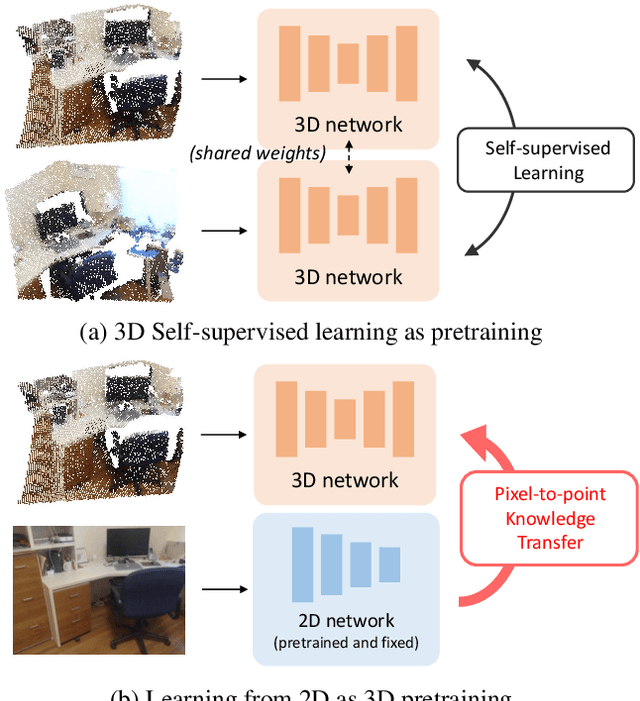
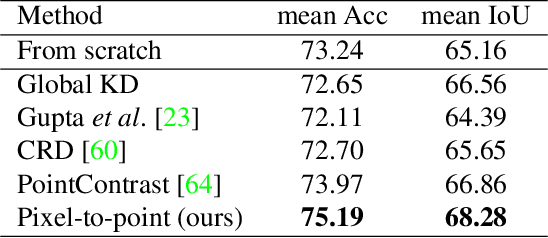
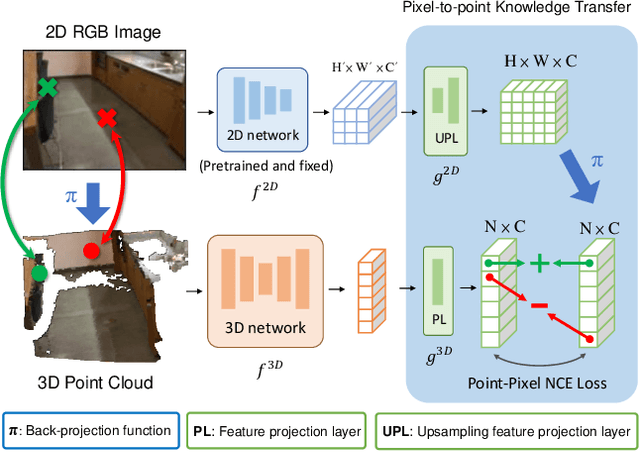
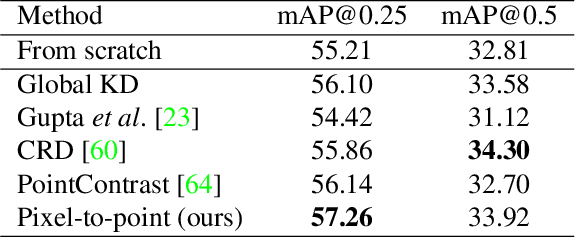
Most of the 3D networks are trained from scratch owning to the lack of large-scale labeled datasets. In this paper, we present a novel 3D pretraining method by leveraging 2D networks learned from rich 2D datasets. We propose the pixel-to-point knowledge transfer to effectively utilize the 2D information by mapping the pixel-level and point-level features into the same embedding space. Due to the heterogeneous nature between 2D and 3D networks, we introduce the back-projection function to align the features between 2D and 3D to make the transfer possible. Additionally, we devise an upsampling feature projection layer to increase the spatial resolution of high-level 2D feature maps, which helps learning fine-grained 3D representations. With a pretrained 2D network, the proposed pretraining process requires no additional 2D or 3D labeled data, further alleviating the expansive 3D data annotation cost. To the best of our knowledge, we are the first to exploit existing 2D trained weights to pretrain 3D deep neural networks. Our intensive experiments show that the 3D models pretrained with 2D knowledge boost the performances across various real-world 3D downstream tasks.