 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Language Model Logits Calibrated?
Oct 21, 2024Some information is factual (e.g., "Paris is in France"), whereas other information is probabilistic (e.g., "the coin flip will be a [Heads/Tails]."). We believe that good Language Models (LMs) should understand and reflect this nuance. Our work investigates this by testing if LMs' output probabilities are calibrated to their textual contexts. We define model "calibration" as the degree to which the output probabilities of candidate tokens are aligned with the relative likelihood that should be inferred from the given context. For example, if the context concerns two equally likely options (e.g., heads or tails for a fair coin), the output probabilities should reflect this. Likewise, context that concerns non-uniformly likely events (e.g., rolling a six with a die) should also be appropriately captured with proportionate output probabilities. We find that even in simple settings the best LMs (1) are poorly calibrated, and (2) have systematic biases (e.g., preferred colors and sensitivities to word orderings). For example, gpt-4o-mini often picks the first of two options presented in the prompt regardless of the options' implied likelihood, whereas Llama-3.1-8B picks the second. Our other consistent finding is mode-collapse: Instruction-tuned models often over-allocate probability mass on a single option. These systematic biases introduce non-intuitive model behavior, making models harder for users to understand.
Distributionally Robust Optimization and Invariant Representation Learning for Addressing Subgroup Underrepresentation: Mechanisms and Limitations
Aug 12, 2023Spurious correlation caused by subgroup underrepresentation has received increasing attention as a source of bias that can be perpetuated by deep neural networks (DNNs). Distributionally robust optimization has shown success in addressing this bias, although the underlying working mechanism mostly relies on upweighting under-performing samples as surrogates for those underrepresented in data. At the same time, while invariant representation learning has been a powerful choice for removing nuisance-sensitive features, it has been little considered in settings where spurious correlations are caused by significant underrepresentation of subgroups. In this paper, we take the first step to better understand and improve the mechanisms for debiasing spurious correlation due to subgroup underrepresentation in medical image classification. Through a comprehensive evaluation study, we first show that 1) generalized reweighting of under-performing samples can be problematic when bias is not the only cause for poor performance, while 2) naive invariant representation learning suffers from spurious correlations itself. We then present a novel approach that leverages robust optimization to facilitate the learning of invariant representations at the presence of spurious correlations. Finetuned classifiers utilizing such representation demonstrated improved abilities to reduce subgroup performance disparity, while maintaining high average and worst-group performance.
Learning Transferable Object-Centric Diffeomorphic Transformations for Data Augmentation in Medical Image Segmentation
Jul 25, 2023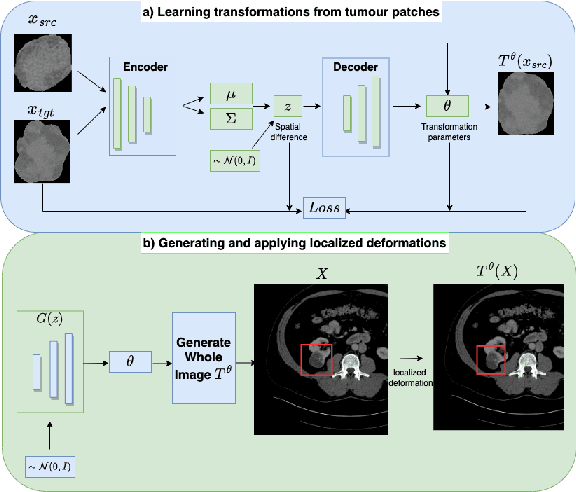
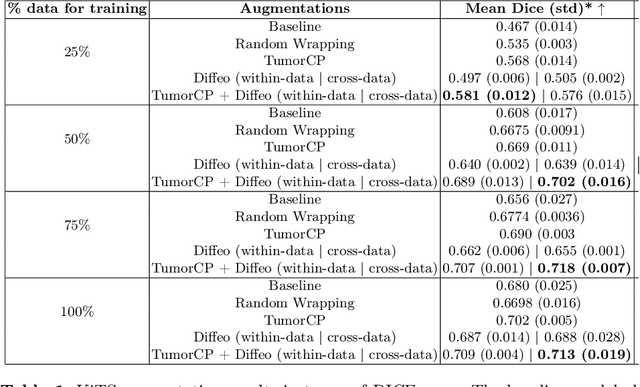

Obtaining labelled data in medical image segmentation is challenging due to the need for pixel-level annotations by experts. Recent works have shown that augmenting the object of interest with deformable transformations can help mitigate this challenge. However, these transformations have been learned globally for the image, limiting their transferability across datasets or applicability in problems where image alignment is difficult. While object-centric augmentations provide a great opportunity to overcome these issues, existing works are only focused on position and random transformations without considering shape variations of the objects. To this end, we propose a novel object-centric data augmentation model that is able to learn the shape variations for the objects of interest and augment the object in place without modifying the rest of the image. We demonstrated its effectiveness in improving kidney tumour segmentation when leveraging shape variations learned both from within the same dataset and transferred from external datasets.
Interpretable Modeling and Reduction of Unknown Errors in Mechanistic Operators
Nov 02, 2022Prior knowledge about the imaging physics provides a mechanistic forward operator that plays an important role in image reconstruction, although myriad sources of possible errors in the operator could negatively impact the reconstruction solutions. In this work, we propose to embed the traditional mechanistic forward operator inside a neural function, and focus on modeling and correcting its unknown errors in an interpretable manner. This is achieved by a conditional generative model that transforms a given mechanistic operator with unknown errors, arising from a latent space of self-organizing clusters of potential sources of error generation. Once learned, the generative model can be used in place of a fixed forward operator in any traditional optimization-based reconstruction process where, together with the inverse solution, the error in prior mechanistic forward operator can be minimized and the potential source of error uncovered. We apply the presented method to the reconstruction of heart electrical potential from body surface potential. In controlled simulation experiments and in-vivo real data experiments, we demonstrate that the presented method allowed reduction of errors in the physics-based forward operator and thereby delivered inverse reconstruction of heart-surface potential with increased accuracy.
* 11 pages, Conference: Medical Image Computing and Computer Assisted Intervention