 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Interpretability through the Lens of Computational Complexity
Paper and Code
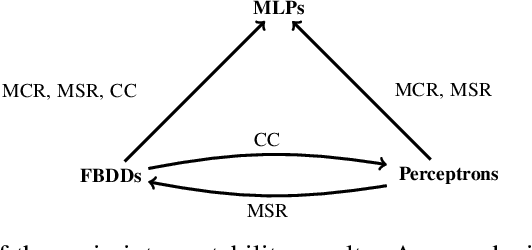

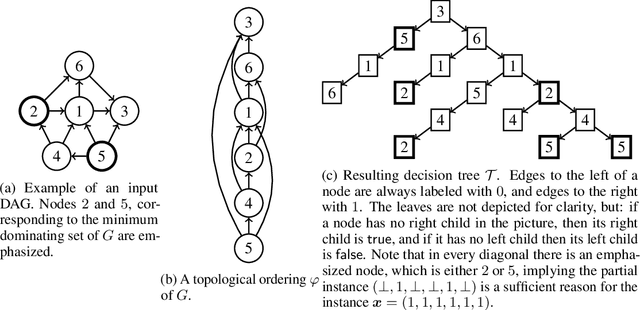
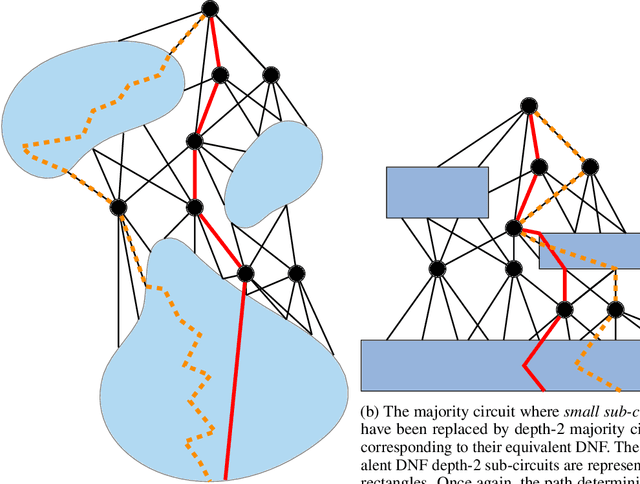
In spite of several claims stating that some models are more interpretable than others -- e.g., "linear models are more interpretable than deep neural networks" -- we still lack a principled notion of interpretability to formally compare among different classes of models. We make a step towards such a notion by studying whether folklore interpretability claims have a correlate in terms of computational complexity theory. We focus on local post-hoc explainability queries that, intuitively, attempt to answer why individual inputs are classified in a certain way by a given model. In a nutshell, we say that a class $\mathcal{C}_1$ of models is more interpretable than another class $\mathcal{C}_2$, if the computational complexity of answering post-hoc queries for models in $\mathcal{C}_2$ is higher than for those in $\mathcal{C}_1$. We prove that this notion provides a good theoretical counterpart to current beliefs on the interpretability of models; in particular, we show that under our definition and assuming standard complexity-theoretical assumptions (such as P$\neq$NP), both linear and tree-based models are strictly more interpretable than neural networks. Our complexity analysis, however, does not provide a clear-cut difference between linear and tree-based models, as we obtain different results depending on the particular post-hoc explanations considered. Finally, by applying a finer complexity analysis based on parameterized complexity, we are able to prove a theoretical result suggesting that shallow neural networks are more interpretable than deeper ones.