 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Unplanned Readmissions with Highly Unstructured Data
Paper and Code
Apr 05, 2020
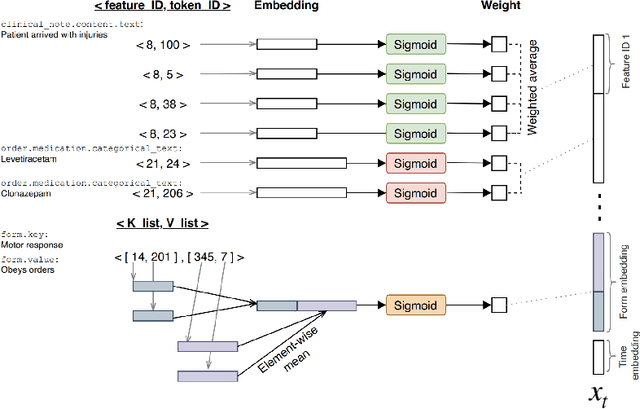
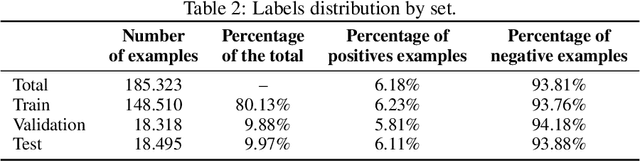

Deep learning techniques have been successfully applied to predict unplanned readmissions of patients in medical centers. The training data for these models is usually based on historical medical records that contain a significant amount of free-text from admission reports, referrals, exam notes, etc. Most of the models proposed so far are tailored to English text data and assume that electronic medical records follow standards common in developed countries. These two characteristics make them difficult to apply in developing countries that do not necessarily follow international standards for registering patient information, or that store text information in languages other than English. In this paper we propose a deep learning architecture for predicting unplanned readmissions that consumes data that is significantly less structured compared with previous models in the literature. We use it to present the first results for this task in a large clinical dataset that mainly contains Spanish text data. The dataset is composed of almost 10 years of records in a Chilean medical center. On this dataset, our model achieves results that are comparable to some of the most recent results obtained in US medical centers for the same task (0.76 AUROC).