 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual and Cross-Domain Crisis Classification for Low-Resource Scenarios
Sep 05, 2022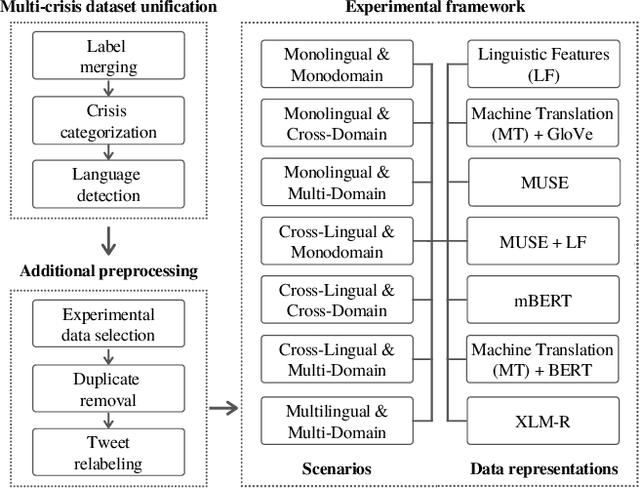
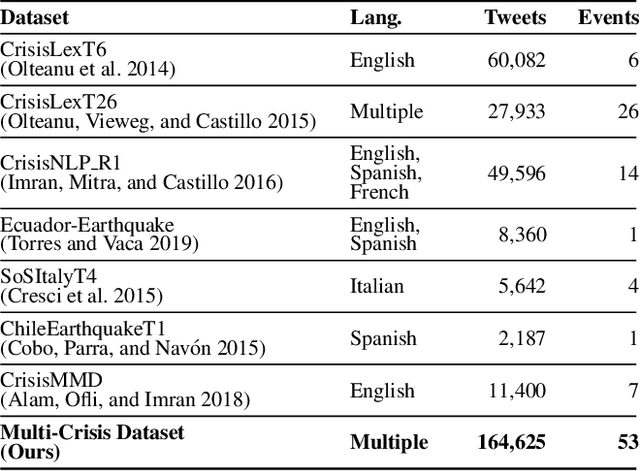
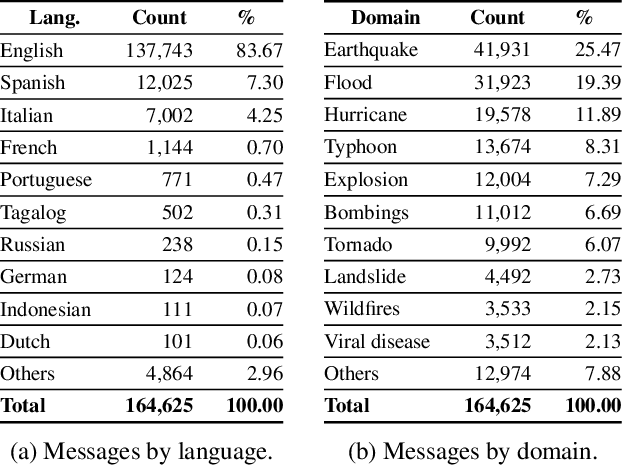
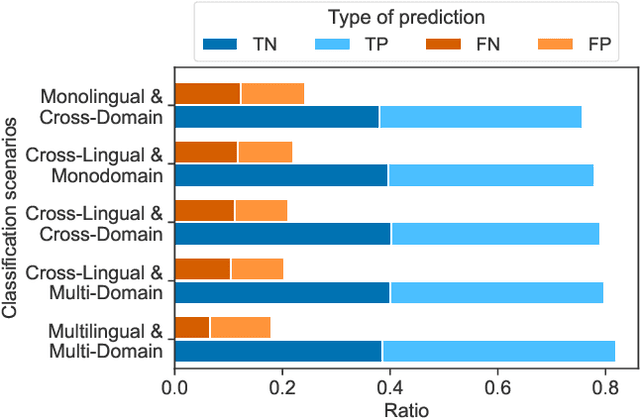
Social media data has emerged as a useful source of timely information about real-world crisis events. One of the main tasks related to the use of social media for disaster management is the automatic identification of crisis-related messages. Most of the studies on this topic have focused on the analysis of data for a particular type of event in a specific language. This limits the possibility of generalizing existing approaches because models cannot be directly applied to new types of events or other languages. In this work, we study the task of automatically classifying messages that are related to crisis events by leveraging cross-language and cross-domain labeled data. Our goal is to make use of labeled data from high-resource languages to classify messages from other (low-resource) languages and/or of new (previously unseen) types of crisis situations. For our study we consolidated from the literature a large unified dataset containing multiple crisis events and languages. Our empirical findings show that it is indeed possible to leverage data from crisis events in English to classify the same type of event in other languages, such as Spanish and Italian (80.0% F1-score). Furthermore, we achieve good performance for the cross-domain task (80.0% F1-score) in a cross-lingual setting. Overall, our work contributes to improving the data scarcity problem that is so important for multilingual crisis classification. In particular, mitigating cold-start situations in emergency events, when time is of essence.
Cross-lingual hate speech detection based on multilingual domain-specific word embeddings
Apr 30, 2021

Automatic hate speech detection in online social networks is an important open problem in Natural Language Processing (NLP). Hate speech is a multidimensional issue, strongly dependant on language and cultural factors. Despite its relevance, research on this topic has been almost exclusively devoted to English. Most supervised learning resources, such as labeled datasets and NLP tools, have been created for this same language. Considering that a large portion of users worldwide speak in languages other than English, there is an important need for creating efficient approaches for multilingual hate speech detection. In this work we propose to address the problem of multilingual hate speech detection from the perspective of transfer learning. Our goal is to determine if knowledge from one particular language can be used to classify other language, and to determine effective ways to achieve this. We propose a hate specific data representation and evaluate its effectiveness against general-purpose universal representations most of which, unlike our proposed model, have been trained on massive amounts of data. We focus on a cross-lingual setting, in which one needs to classify hate speech in one language without having access to any labeled data for that language. We show that the use of our simple yet specific multilingual hate representations improves classification results. We explain this with a qualitative analysis showing that our specific representation is able to capture some common patterns in how hate speech presents itself in different languages. Our proposal constitutes, to the best of our knowledge, the first attempt for constructing multilingual specific-task representations. Despite its simplicity, our model outperformed the previous approaches for most of the experimental setups. Our findings can orient future solutions toward the use of domain-specific representations.