 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Heterogeneous Data Handling for Robust Vehicular Object Detection
May 02, 2024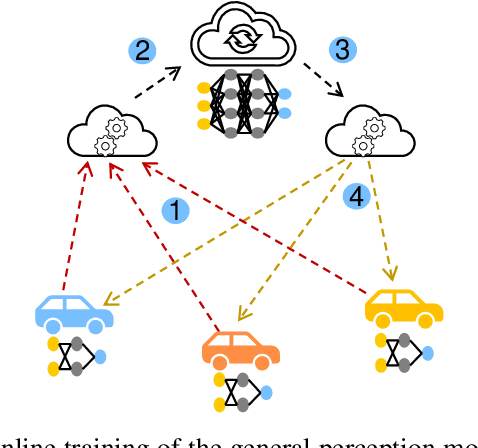
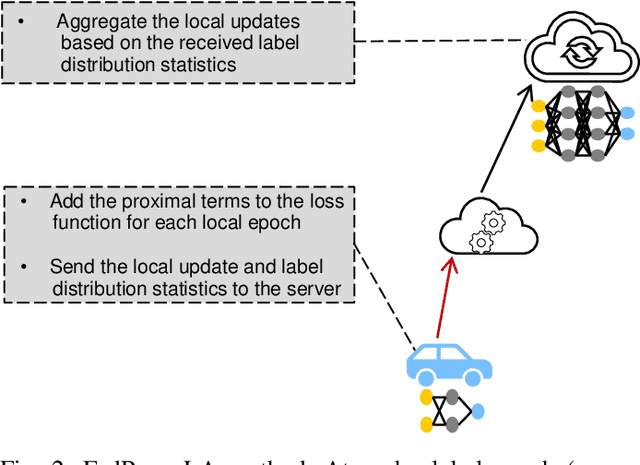
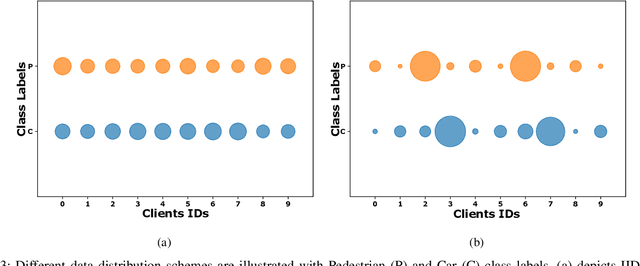
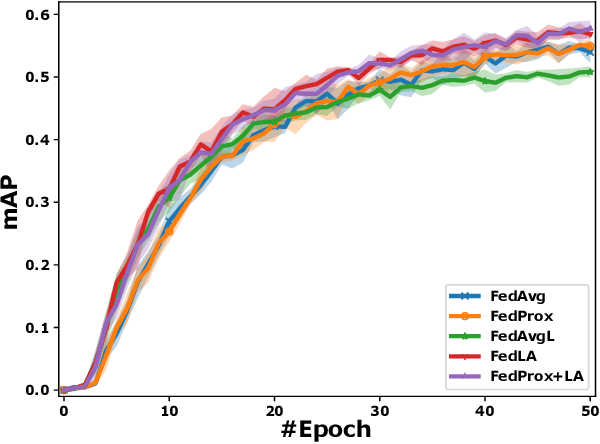
In the pursuit of refining precise perception models for fully autonomous driving, continual online model training becomes essential. Federated Learning (FL) within vehicular networks offers an efficient mechanism for model training while preserving raw sensory data integrity. Yet, FL struggles with non-identically distributed data (e.g., quantity skew), leading to suboptimal convergence rates during model training. In previous work, we introduced FedLA, an innovative Label-Aware aggregation method addressing data heterogeneity in FL for generic scenarios. In this paper, we introduce FedProx+LA, a novel FL method building upon the state-of-the-art FedProx and FedLA to tackle data heterogeneity, which is specifically tailored for vehicular networks. We evaluate the efficacy of FedProx+LA in continuous online object detection model training. Through a comparative analysis against conventional and state-of-the-art methods, our findings reveal the superior convergence rate of FedProx+LA. Notably, if the label distribution is very heterogeneous, our FedProx+LA approach shows substantial improvements in detection performance compared to baseline methods, also outperforming our previous FedLA approach. Moreover, both FedLA and FedProx+LA increase convergence speed by 30% compared to baseline methods.
A Novel Hyperparameter-free Approach to Decision Tree Construction that Avoids Overfitting by Design
Jun 04, 2019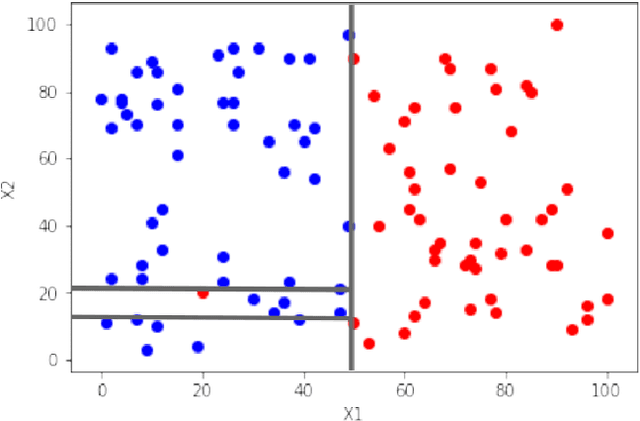
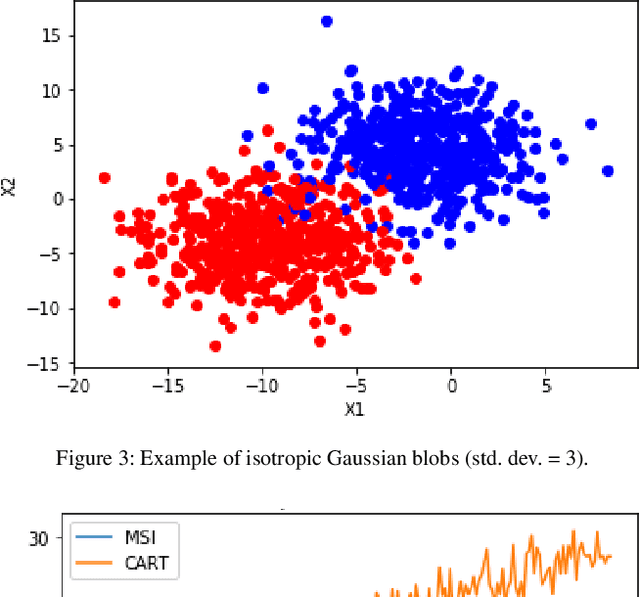
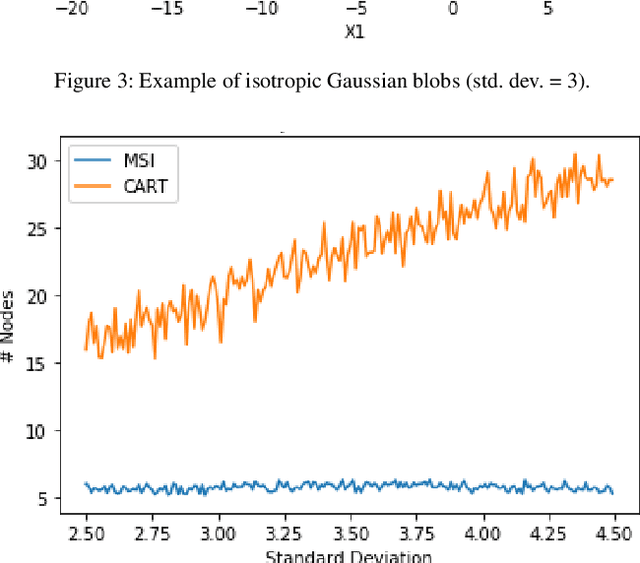
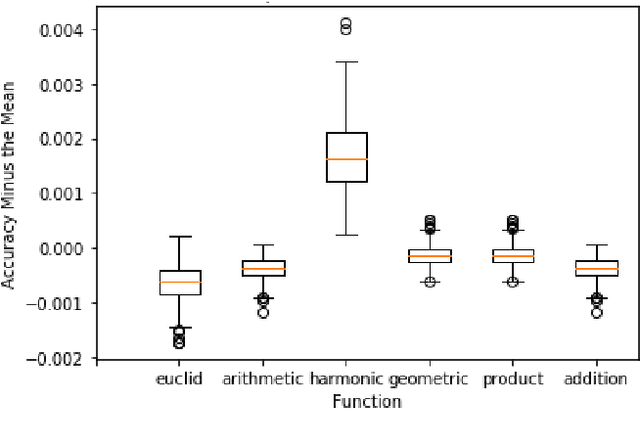
Decision trees are an extremely popular machine learning technique. Unfortunately, overfitting in decision trees still remains an open issue that sometimes prevents achieving good performance. In this work, we present a novel approach for the construction of decision trees that avoids the overfitting by design, without losing accuracy. A distinctive feature of our algorithm is that it requires neither the optimization of any hyperparameters, nor the use of regularization techniques, thus significantly reducing the decision tree training time. Moreover, our algorithm produces much smaller and shallower trees than traditional algorithms, facilitating the interpretability of the resulting models.
Superintelligence cannot be contained: Lessons from Computability Theory
Jul 04, 2016



Superintelligence is a hypothetical agent that possesses intelligence far surpassing that of the brightest and most gifted human minds. In light of recent advances in machine intelligence, a number of scientists, philosophers and technologists have revived the discussion about the potential catastrophic risks entailed by such an entity. In this article, we trace the origins and development of the neo-fear of superintelligence, and some of the major proposals for its containment. We argue that such containment is, in principle, impossible, due to fundamental limits inherent to computing itself. Assuming that a superintelligence will contain a program that includes all the programs that can be executed by a universal Turing machine on input potentially as complex as the state of the world, strict containment requires simulations of such a program, something theoretically (and practically) infeasible.