 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResNetVLLM-2: Addressing ResNetVLLM's Multi-Modal Hallucinations
Apr 20, 2025Large Language Models (LLMs) have transformed natural language processing (NLP) tasks, but they suffer from hallucination, generating plausible yet factually incorrect content. This issue extends to Video-Language Models (VideoLLMs), where textual descriptions may inaccurately represent visual content, resulting in multi-modal hallucinations. In this paper, we address hallucination in ResNetVLLM, a video-language model combining ResNet visual encoders with LLMs. We introduce a two-step protocol: (1) a faithfulness detection strategy that uses a modified Lynx model to assess semantic alignment between generated captions and ground-truth video references, and (2) a hallucination mitigation strategy using Retrieval-Augmented Generation (RAG) with an ad-hoc knowledge base dynamically constructed during inference. Our enhanced model, ResNetVLLM-2, reduces multi-modal hallucinations by cross-verifying generated content against external knowledge, improving factual consistency. Evaluation on the ActivityNet-QA benchmark demonstrates a substantial accuracy increase from 54.8% to 65.3%, highlighting the effectiveness of our hallucination detection and mitigation strategies in enhancing video-language model reliability.
ResNetVLLM -- Multi-modal Vision LLM for the Video Understanding Task
Apr 20, 2025In this paper, we introduce ResNetVLLM (ResNet Vision LLM), a novel cross-modal framework for zero-shot video understanding that integrates a ResNet-based visual encoder with a Large Language Model (LLM. ResNetVLLM addresses the challenges associated with zero-shot video models by avoiding reliance on pre-trained video understanding models and instead employing a non-pretrained ResNet to extract visual features. This design ensures the model learns visual and semantic representations within a unified architecture, enhancing its ability to generate accurate and contextually relevant textual descriptions from video inputs. Our experimental results demonstrate that ResNetVLLM achieves state-of-the-art performance in zero-shot video understanding (ZSVU) on several benchmarks, including MSRVTT-QA, MSVD-QA, TGIF-QA FrameQA, and ActivityNet-QA.
Federated Learning with Heterogeneous Data Handling for Robust Vehicular Object Detection
May 02, 2024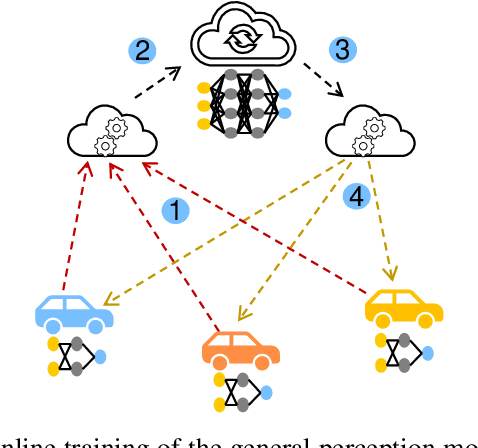
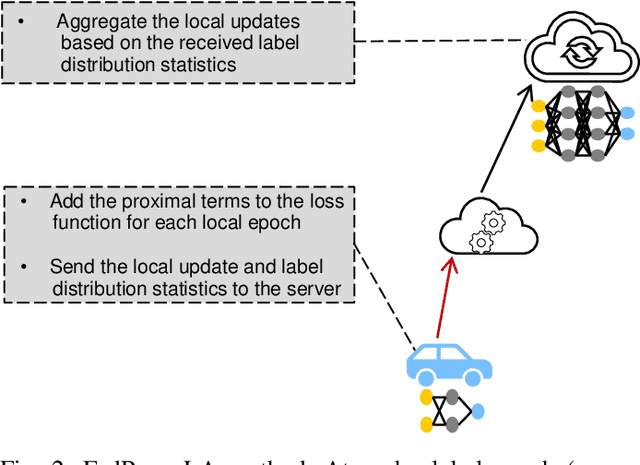
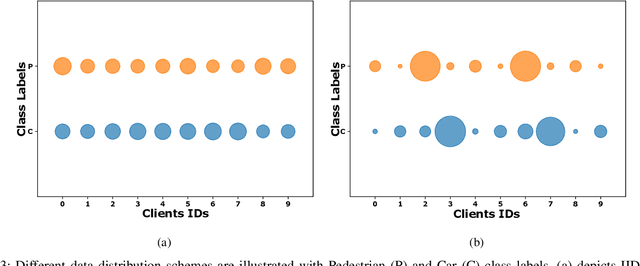
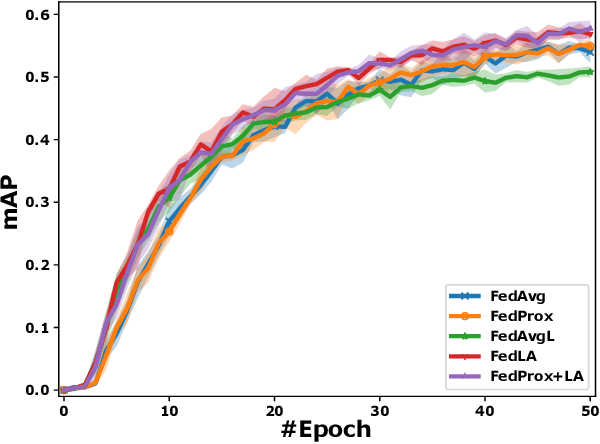
In the pursuit of refining precise perception models for fully autonomous driving, continual online model training becomes essential. Federated Learning (FL) within vehicular networks offers an efficient mechanism for model training while preserving raw sensory data integrity. Yet, FL struggles with non-identically distributed data (e.g., quantity skew), leading to suboptimal convergence rates during model training. In previous work, we introduced FedLA, an innovative Label-Aware aggregation method addressing data heterogeneity in FL for generic scenarios. In this paper, we introduce FedProx+LA, a novel FL method building upon the state-of-the-art FedProx and FedLA to tackle data heterogeneity, which is specifically tailored for vehicular networks. We evaluate the efficacy of FedProx+LA in continuous online object detection model training. Through a comparative analysis against conventional and state-of-the-art methods, our findings reveal the superior convergence rate of FedProx+LA. Notably, if the label distribution is very heterogeneous, our FedProx+LA approach shows substantial improvements in detection performance compared to baseline methods, also outperforming our previous FedLA approach. Moreover, both FedLA and FedProx+LA increase convergence speed by 30% compared to baseline methods.
A Comprehensive Study of Vision Transformers in Image Classification Tasks
Dec 05, 2023Image Classification is a fundamental task in the field of computer vision that frequently serves as a benchmark for gauging advancements in Computer Vision. Over the past few years, significant progress has been made in image classification due to the emergence of deep learning. However, challenges still exist, such as modeling fine-grained visual information, high computation costs, the parallelism of the model, and inconsistent evaluation protocols across datasets. In this paper, we conduct a comprehensive survey of existing papers on Vision Transformers for image classification. We first introduce the popular image classification datasets that influenced the design of models. Then, we present Vision Transformers models in chronological order, starting with early attempts at adapting attention mechanism to vision tasks followed by the adoption of vision transformers, as they have demonstrated success in capturing intricate patterns and long-range dependencies within images. Finally, we discuss open problems and shed light on opportunities for image classification to facilitate new research ideas.