 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of Appropriateness That Accounts for Norms of Rationality
Mar 14, 2026We propose a society-first theory of normative appropriateness where individuals, modeled as pre-trained actors with cognitive architectures analogous to Large Language Models (LLMs), generate behavior via predictive pattern completion. Our theory posits that individuals act by completing distributed symbolic patterns based on context, answering questions such as "What does a person such as I do in a situation such as this?". This sense-making mechanism provides a parsimonious account of the key features of human norms: their context-dependence, arbitrariness, automaticity, dynamism, and their support from social sanctioning. It challenges rational-choice theories of social norms by accounting for their key features without needing to exogenously posit scalar rewards or preference relations. By distinguishing between explicit norms, which we associate with in-context adaptation, and implicit norms, which we associate with long-term memory, the theory reconceptualizes several foundational ideas in cognitive science. In particular, it gives an alternative account to the data traditionally seen as supporting dual-process models, and it flips the role of rationality, allowing us to construe it as adherence to culturally-contingent justification standards.
Group Selection as a Safeguard Against AI Substitution
Feb 03, 2026Reliance on generative AI can reduce cultural variance and diversity, especially in creative work. This reduction in variance has already led to problems in model performance, including model collapse and hallucination. In this paper, we examine the long-term consequences of AI use for human cultural evolution and the conditions under which widespread AI use may lead to "cultural collapse", a process in which reliance on AI-generated content reduces human variation and innovation and slows cumulative cultural evolution. Using an agent-based model and evolutionary game theory, we compare two types of AI use: complement and substitute. AI-complement users seek suggestions and guidance while remaining the main producers of the final output, whereas AI-substitute users provide minimal input, and rely on AI to produce most of the output. We then study how these use strategies compete and spread under evolutionary dynamics. We find that AI-substitute users prevail under individual-level selection despite the stronger reduction in cultural variance. By contrast, AI-complement users can benefit their groups by maintaining the variance needed for exploration, and can therefore be favored under cultural group selection when group boundaries are strong. Overall, our findings shed light on the long-term, population-level effects of AI adoption and inform policy and organizational strategies to mitigate these risks.
The Role of Social Learning and Collective Norm Formation in Fostering Cooperation in LLM Multi-Agent Systems
Oct 16, 2025A growing body of multi-agent studies with Large Language Models (LLMs) explores how norms and cooperation emerge in mixed-motive scenarios, where pursuing individual gain can undermine the collective good. While prior work has explored these dynamics in both richly contextualized simulations and simplified game-theoretic environments, most LLM systems featuring common-pool resource (CPR) games provide agents with explicit reward functions directly tied to their actions. In contrast, human cooperation often emerges without full visibility into payoffs and population, relying instead on heuristics, communication, and punishment. We introduce a CPR simulation framework that removes explicit reward signals and embeds cultural-evolutionary mechanisms: social learning (adopting strategies and beliefs from successful peers) and norm-based punishment, grounded in Ostrom's principles of resource governance. Agents also individually learn from the consequences of harvesting, monitoring, and punishing via environmental feedback, enabling norms to emerge endogenously. We establish the validity of our simulation by reproducing key findings from existing studies on human behavior. Building on this, we examine norm evolution across a $2\times2$ grid of environmental and social initialisations (resource-rich vs. resource-scarce; altruistic vs. selfish) and benchmark how agentic societies comprised of different LLMs perform under these conditions. Our results reveal systematic model differences in sustaining cooperation and norm formation, positioning the framework as a rigorous testbed for studying emergent norms in mixed-motive LLM societies. Such analysis can inform the design of AI systems deployed in social and organizational contexts, where alignment with cooperative norms is critical for stability, fairness, and effective governance of AI-mediated environments.
Humans learn to prefer trustworthy AI over human partners
Jul 17, 2025Partner selection is crucial for cooperation and hinges on communication. As artificial agents, especially those powered by large language models (LLMs), become more autonomous, intelligent, and persuasive, they compete with humans for partnerships. Yet little is known about how humans select between human and AI partners and adapt under AI-induced competition pressure. We constructed a communication-based partner selection game and examined the dynamics in hybrid mini-societies of humans and bots powered by a state-of-the-art LLM. Through three experiments (N = 975), we found that bots, though more prosocial than humans and linguistically distinguishable, were not selected preferentially when their identity was hidden. Instead, humans misattributed bots' behaviour to humans and vice versa. Disclosing bots' identity induced a dual effect: it reduced bots' initial chances of being selected but allowed them to gradually outcompete humans by facilitating human learning about the behaviour of each partner type. These findings show how AI can reshape social interaction in mixed societies and inform the design of more effective and cooperative hybrid systems.
Dynamics of Algorithmic Content Amplification on TikTok
Mar 26, 2025Intelligent algorithms increasingly shape the content we encounter and engage with online. TikTok's For You feed exemplifies extreme algorithm-driven curation, tailoring the stream of video content almost exclusively based on users' explicit and implicit interactions with the platform. Despite growing attention, the dynamics of content amplification on TikTok remain largely unquantified. How quickly, and to what extent, does TikTok's algorithm amplify content aligned with users' interests? To address these questions, we conduct a sock-puppet audit, deploying bots with different interests to engage with TikTok's "For You" feed. Our findings reveal that content aligned with the bots' interests undergoes strong amplification, with rapid reinforcement typically occurring within the first 200 videos watched. While amplification is consistently observed across all interests, its intensity varies by interest, indicating the emergence of topic-specific biases. Time series analyses and Markov models uncover distinct phases of recommendation dynamics, including persistent content reinforcement and a gradual decline in content diversity over time. Although TikTok's algorithm preserves some content diversity, we find a strong negative correlation between amplification and exploration: as the amplification of interest-aligned content increases, engagement with unseen hashtags declines. These findings contribute to discussions on socio-algorithmic feedback loops in the digital age and the trade-offs between personalization and content diversity.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Expertise elevates AI usage: experimental evidence comparing laypeople and professional artists
Jan 21, 2025



Novel capacities of generative AI to analyze and generate cultural artifacts raise inevitable questions about the nature and value of artistic education and human expertise. Has AI already leveled the playing field between professional artists and laypeople, or do trained artistic expressive capacity, curation skills and experience instead enhance the ability to use these new tools? In this pre-registered study, we conduct experimental comparisons between 50 active artists and a demographically matched sample of laypeople. We designed two tasks to approximate artistic practice for testing their capabilities in both faithful and creative image creation: replicating a reference image, and moving as far away as possible from it. We developed a bespoke platform where participants used a modern text-to-image model to complete both tasks. We also collected and compared participants' sentiments towards AI. On average, artists produced more faithful and creative outputs than their lay counterparts, although only by a small margin. While AI may ease content creation, professional expertise is still valuable - even within the confined space of generative AI itself. Finally, we also explored how well an exemplary vision-capable large language model (GPT-4o) would complete the same tasks, if given the role of an image generation agent, and found it performed on par in copying but outperformed even artists in the creative task. The very best results were still produced by humans in both tasks. These outcomes highlight the importance of integrating artistic skills with AI training to prepare artists and other visual professionals for a technologically evolving landscape. We see a potential in collaborative synergy with generative AI, which could reshape creative industries and education in the arts.
A theory of appropriateness with applications to generative artificial intelligence
Dec 26, 2024

What is appropriateness? Humans navigate a multi-scale mosaic of interlocking notions of what is appropriate for different situations. We act one way with our friends, another with our family, and yet another in the office. Likewise for AI, appropriate behavior for a comedy-writing assistant is not the same as appropriate behavior for a customer-service representative. What determines which actions are appropriate in which contexts? And what causes these standards to change over time? Since all judgments of AI appropriateness are ultimately made by humans, we need to understand how appropriateness guides human decision making in order to properly evaluate AI decision making and improve it. This paper presents a theory of appropriateness: how it functions in human society, how it may be implemented in the brain, and what it means for responsible deployment of generative AI technology.
Alien Recombination: Exploring Concept Blends Beyond Human Cognitive Availability in Visual Art
Nov 18, 2024
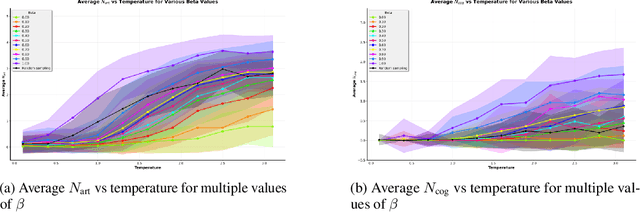
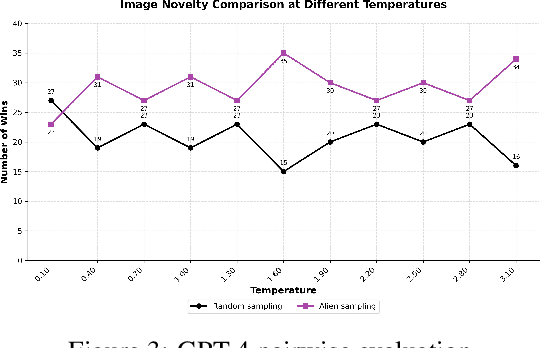
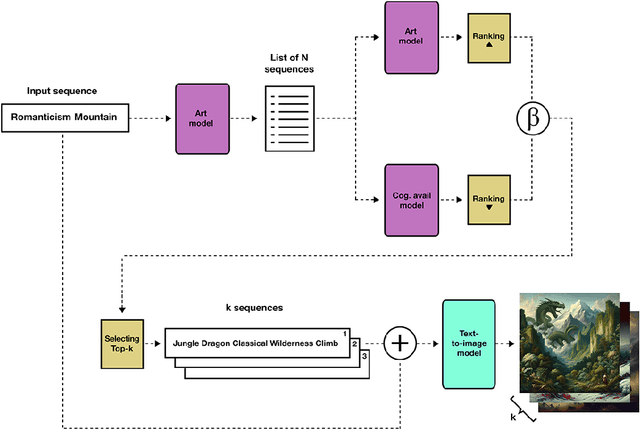
While AI models have demonstrated remarkable capabilities in constrained domains like game strategy, their potential for genuine creativity in open-ended domains like art remains debated. We explore this question by examining how AI can transcend human cognitive limitations in visual art creation. Our research hypothesizes that visual art contains a vast unexplored space of conceptual combinations, constrained not by inherent incompatibility, but by cognitive limitations imposed by artists' cultural, temporal, geographical and social contexts. To test this hypothesis, we present the Alien Recombination method, a novel approach utilizing fine-tuned large language models to identify and generate concept combinations that lie beyond human cognitive availability. The system models and deliberately counteracts human availability bias, the tendency to rely on immediately accessible examples, to discover novel artistic combinations. This system not only produces combinations that have never been attempted before within our dataset but also identifies and generates combinations that are cognitively unavailable to all artists in the domain. Furthermore, we translate these combinations into visual representations, enabling the exploration of subjective perceptions of novelty. Our findings suggest that cognitive unavailability is a promising metric for optimizing artistic novelty, outperforming merely temperature scaling without additional evaluation criteria. This approach uses generative models to connect previously unconnected ideas, providing new insight into the potential of framing AI-driven creativity as a combinatorial problem.
Imagining and building wise machines: The centrality of AI metacognition
Nov 04, 2024


Recent advances in artificial intelligence (AI) have produced systems capable of increasingly sophisticated performance on cognitive tasks. However, AI systems still struggle in critical ways: unpredictable and novel environments (robustness), lack of transparency in their reasoning (explainability), challenges in communication and commitment (cooperation), and risks due to potential harmful actions (safety). We argue that these shortcomings stem from one overarching failure: AI systems lack wisdom. Drawing from cognitive and social sciences, we define wisdom as the ability to navigate intractable problems - those that are ambiguous, radically uncertain, novel, chaotic, or computationally explosive - through effective task-level and metacognitive strategies. While AI research has focused on task-level strategies, metacognition - the ability to reflect on and regulate one's thought processes - is underdeveloped in AI systems. In humans, metacognitive strategies such as recognizing the limits of one's knowledge, considering diverse perspectives, and adapting to context are essential for wise decision-making. We propose that integrating metacognitive capabilities into AI systems is crucial for enhancing their robustness, explainability, cooperation, and safety. By focusing on developing wise AI, we suggest an alternative to aligning AI with specific human values - a task fraught with conceptual and practical difficulties. Instead, wise AI systems can thoughtfully navigate complex situations, account for diverse human values, and avoid harmful actions. We discuss potential approaches to building wise AI, including benchmarking metacognitive abilities and training AI systems to employ wise reasoning. Prioritizing metacognition in AI research will lead to systems that act not only intelligently but also wisely in complex, real-world situations.