 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow cyborg propaganda reshapes collective action
Feb 13, 2026The distinction between genuine grassroots activism and automated influence operations is collapsing. While policy debates focus on bot farms, a distinct threat to democracy is emerging via partisan coordination apps and artificial intelligence-what we term 'cyborg propaganda.' This architecture combines large numbers of verified humans with adaptive algorithmic automation, enabling a closed-loop system. AI tools monitor online sentiment to optimize directives and generate personalized content for users to post online. Cyborg propaganda thereby exploits a critical legal shield: by relying on verified citizens to ratify and disseminate messages, these campaigns operate in a regulatory gray zone, evading liability frameworks designed for automated botnets. We explore the collective action paradox of this technology: does it democratize power by 'unionizing' influence (pooling the reach of dispersed citizens to overcome the algorithmic invisibility of isolated voices), or does it reduce citizens to 'cognitive proxies' of a central directive? We argue that cyborg propaganda fundamentally alters the digital public square, shifting political discourse from a democratic contest of individual ideas to a battle of algorithmic campaigns. We outline a research agenda to distinguish organic from coordinated information diffusion and propose governance frameworks to address the regulatory challenges of AI-assisted collective expression.
Understanding Opportunities and Risks of Synthetic Relationships: Leveraging the Power of Longitudinal Research with Customised AI Tools
Dec 12, 2024This position paper discusses the benefits of longitudinal behavioural research with customised AI tools for exploring the opportunities and risks of synthetic relationships. Synthetic relationships are defined as "continuing associations between humans and AI tools that interact with one another wherein the AI tool(s) influence(s) humans' thoughts, feelings, and/or actions." (Starke et al., 2024). These relationships can potentially improve health, education, and the workplace, but they also bring the risk of subtle manipulation and privacy and autonomy concerns. To harness the opportunities of synthetic relationships and mitigate their risks, we outline a methodological approach that complements existing findings. We propose longitudinal research designs with self-assembled AI agents that enable the integration of detailed behavioural and self-reported data.
* This is a "Position paper accepted for CONVERSATIONS 2024 - the 8th International Workshop on Chatbots and Human-Centred AI, hosted by CERTH, Thessaloniki, Greece, December 4-5, 2024." The original publication is available on the workshop website: https://2024.conversations.ws/papers/ . This document is identical to the original and is mainly available here for accessibility and discoverability
Artificial Intelligence can facilitate selfish decisions by altering the appearance of interaction partners
Jun 07, 2023



The increasing prevalence of image-altering filters on social media and video conferencing technologies has raised concerns about the ethical and psychological implications of using Artificial Intelligence (AI) to manipulate our perception of others. In this study, we specifically investigate the potential impact of blur filters, a type of appearance-altering technology, on individuals' behavior towards others. Our findings consistently demonstrate a significant increase in selfish behavior directed towards individuals whose appearance is blurred, suggesting that blur filters can facilitate moral disengagement through depersonalization. These results emphasize the need for broader ethical discussions surrounding AI technologies that modify our perception of others, including issues of transparency, consent, and the awareness of being subject to appearance manipulation by others. We also emphasize the importance of anticipatory experiments in informing the development of responsible guidelines and policies prior to the widespread adoption of such technologies.
Fears about AI-mediated communication are grounded in different expectations for one's own versus others' use
May 02, 2023
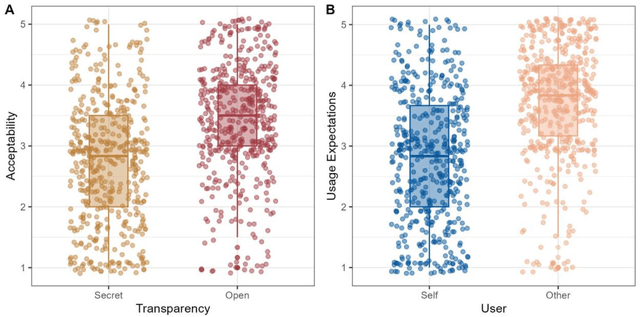

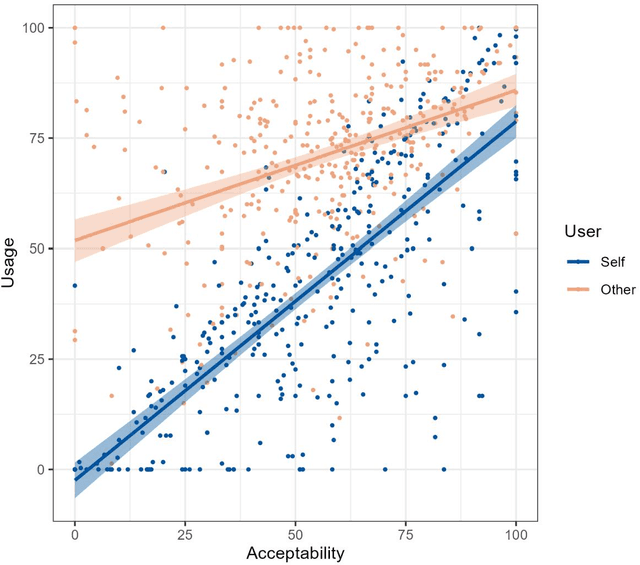
The rapid development of AI-mediated communication technologies (AICTs), which are digital tools that use AI to augment interpersonal messages, has raised concerns about the future of interpersonal trust and prompted discussions about disclosure and uptake. This paper contributes to this discussion by assessing perceptions about the acceptability and use of open and secret AICTs for oneself and others. In two studies with representative samples (UK: N=477, US: N=765), we found that secret AICT use is deemed less acceptable than open AICT use, people tend to overestimate others' AICT use, and people expect others to use AICTs irresponsibly. Thus, we raise concerns about the potential for misperceptions and different expectations for others to drive self-fulfilling pessimistic outlooks about AI-mediated communication.
Lie detection algorithms attract few users but vastly increase accusation rates
Dec 08, 2022



People are not very good at detecting lies, which may explain why they refrain from accusing others of lying, given the social costs attached to false accusations - both for the accuser and the accused. Here we consider how this social balance might be disrupted by the availability of lie-detection algorithms powered by Artificial Intelligence. Will people elect to use lie detection algorithms that perform better than humans, and if so, will they show less restraint in their accusations? We built a machine learning classifier whose accuracy (67\%) was significantly better than human accuracy (50\%) in a lie-detection task and conducted an incentivized lie-detection experiment in which we measured participants' propensity to use the algorithm, as well as the impact of that use on accusation rates. We find that the few people (33\%) who elect to use the algorithm drastically increase their accusation rates (from 25\% in the baseline condition up to 86% when the algorithm flags a statement as a lie). They make more false accusations (18pp increase), but at the same time, the probability of a lie remaining undetected is much lower in this group (36pp decrease). We consider individual motivations for using lie detection algorithms and the social implications of these algorithms.
Artificial Intelligence as an Anti-Corruption Tool (AI-ACT) -- Potentials and Pitfalls for Top-down and Bottom-up Approaches
Feb 23, 2021Corruption continues to be one of the biggest societal challenges of our time. New hope is placed in Artificial Intelligence (AI) to serve as an unbiased anti-corruption agent. Ever more available (open) government data paired with unprecedented performance of such algorithms render AI the next frontier in anti-corruption. Summarizing existing efforts to use AI-based anti-corruption tools (AI-ACT), we introduce a conceptual framework to advance research and policy. It outlines why AI presents a unique tool for top-down and bottom-up anti-corruption approaches. For both approaches, we outline in detail how AI-ACT present different potentials and pitfalls for (a) input data, (b) algorithmic design, and (c) institutional implementation. Finally, we venture a look into the future and flesh out key questions that need to be addressed to develop AI-ACT while considering citizens' views, hence putting "society in the loop".
Creative Artificial Intelligence -- Algorithms vs. humans in an incentivized writing competition
May 20, 2020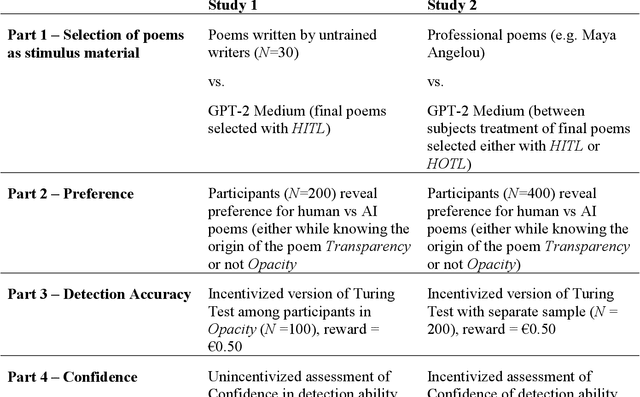
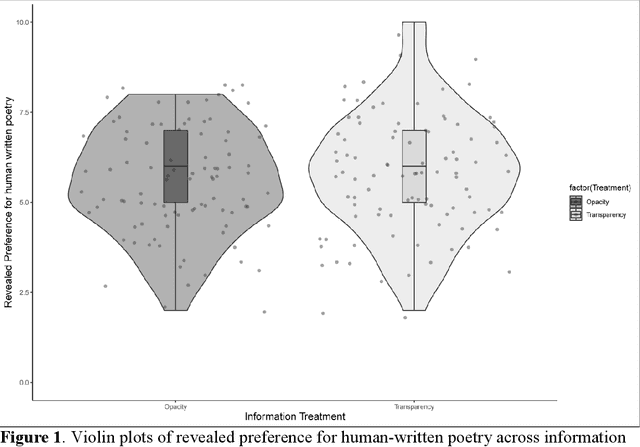
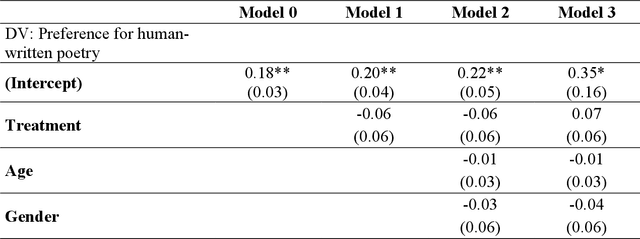
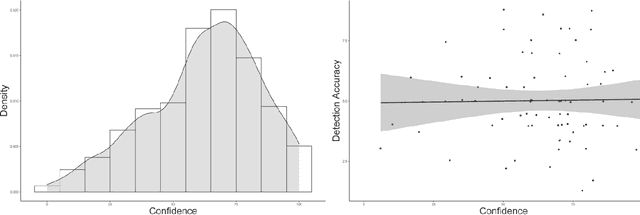
The release of openly available, robust text generation algorithms has spurred much public attention and debate, due to algorithm's purported ability to generate human-like text across various domains. Yet, empirical evidence using incentivized tasks to assess human behavioral reactions to such algorithms is lacking. We conducted two experiments assessing behavioral reactions to the state-of-the-art Natural Language Generation algorithm GPT-2 (Ntotal = 830). Using the identical starting lines of human poems, GPT-2 produced samples of multiple algorithmically-generated poems. From these samples, either a random poem was chosen (Human-out-of-the-loop) or the best one was selected (Human-in-the-loop) and in turn matched with a human written poem. Taking part in a new incentivized version of the Turing Test, participants failed to reliably detect the algorithmically-generated poems in the human-in-the-loop treatment, yet succeeded in the Human-out-of-the-loop treatment. Further, the results reveal a general aversion towards algorithmic poetry, independent on whether participants were informed about the algorithmic origin of the poem (Transparency) or not (Opacity). We discuss what these results convey about the performance of NLG algorithms to produce human-like text and propose methodologies to study such learning algorithms in experimental settings.