 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumans learn to prefer trustworthy AI over human partners
Jul 17, 2025Partner selection is crucial for cooperation and hinges on communication. As artificial agents, especially those powered by large language models (LLMs), become more autonomous, intelligent, and persuasive, they compete with humans for partnerships. Yet little is known about how humans select between human and AI partners and adapt under AI-induced competition pressure. We constructed a communication-based partner selection game and examined the dynamics in hybrid mini-societies of humans and bots powered by a state-of-the-art LLM. Through three experiments (N = 975), we found that bots, though more prosocial than humans and linguistically distinguishable, were not selected preferentially when their identity was hidden. Instead, humans misattributed bots' behaviour to humans and vice versa. Disclosing bots' identity induced a dual effect: it reduced bots' initial chances of being selected but allowed them to gradually outcompete humans by facilitating human learning about the behaviour of each partner type. These findings show how AI can reshape social interaction in mixed societies and inform the design of more effective and cooperative hybrid systems.
Lie detection algorithms attract few users but vastly increase accusation rates
Dec 08, 2022



People are not very good at detecting lies, which may explain why they refrain from accusing others of lying, given the social costs attached to false accusations - both for the accuser and the accused. Here we consider how this social balance might be disrupted by the availability of lie-detection algorithms powered by Artificial Intelligence. Will people elect to use lie detection algorithms that perform better than humans, and if so, will they show less restraint in their accusations? We built a machine learning classifier whose accuracy (67\%) was significantly better than human accuracy (50\%) in a lie-detection task and conducted an incentivized lie-detection experiment in which we measured participants' propensity to use the algorithm, as well as the impact of that use on accusation rates. We find that the few people (33\%) who elect to use the algorithm drastically increase their accusation rates (from 25\% in the baseline condition up to 86% when the algorithm flags a statement as a lie). They make more false accusations (18pp increase), but at the same time, the probability of a lie remaining undetected is much lower in this group (36pp decrease). We consider individual motivations for using lie detection algorithms and the social implications of these algorithms.
Blaming humans in autonomous vehicle accidents: Shared responsibility across levels of automation
Mar 21, 2018
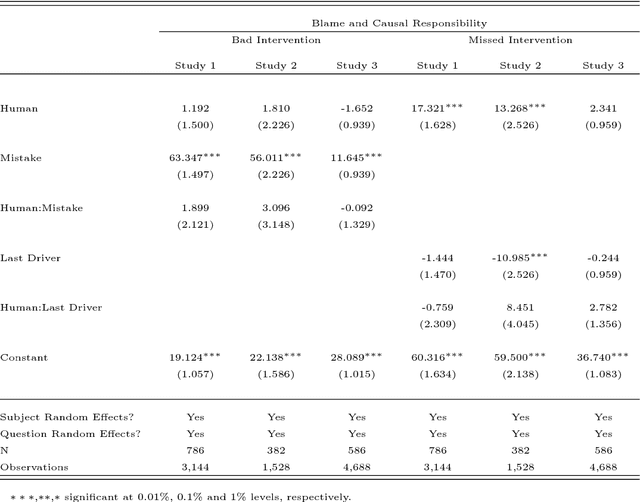
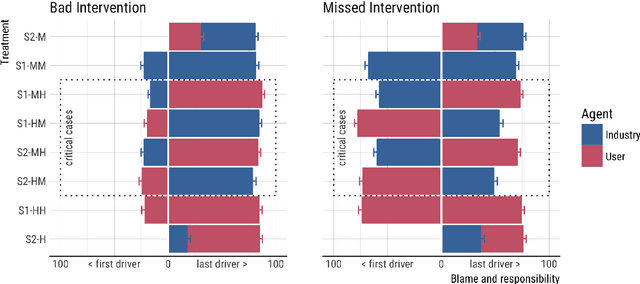
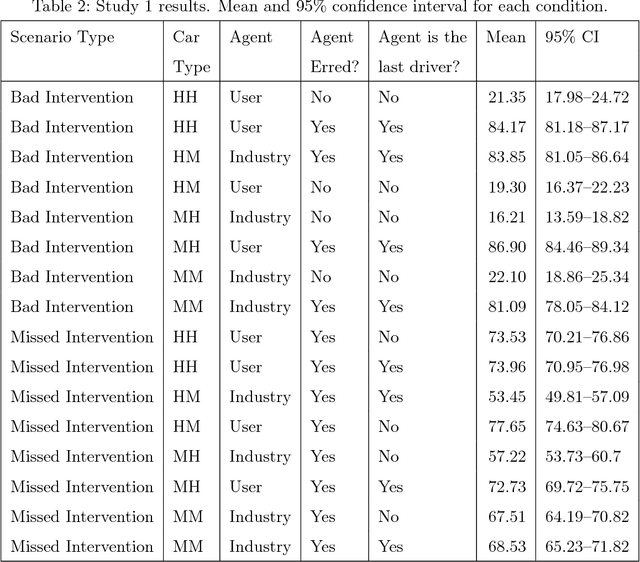
When a semi-autonomous car crashes and harms someone, how are blame and causal responsibility distributed across the human and machine drivers? In this article, we consider cases in which a pedestrian was hit and killed by a car being operated under shared control of a primary and a secondary driver. We find that when only one driver makes an error, that driver receives the blame and is considered causally responsible for the harm, regardless of whether that driver is a machine or a human. However, when both drivers make errors in cases of shared control between a human and a machine, the blame and responsibility attributed to the machine is reduced. This finding portends a public under-reaction to the malfunctioning AI components of semi-autonomous cars and therefore has a direct policy implication: a bottom-up regulatory scheme (which operates through tort law that is adjudicated through the jury system) could fail to properly regulate the safety of shared-control vehicles; instead, a top-down scheme (enacted through federal laws) may be called for.
Cooperating with Machines
Feb 21, 2018



Since Alan Turing envisioned Artificial Intelligence (AI) [1], a major driving force behind technical progress has been competition with human cognition. Historical milestones have been frequently associated with computers matching or outperforming humans in difficult cognitive tasks (e.g. face recognition [2], personality classification [3], driving cars [4], or playing video games [5]), or defeating humans in strategic zero-sum encounters (e.g. Chess [6], Checkers [7], Jeopardy! [8], Poker [9], or Go [10]). In contrast, less attention has been given to developing autonomous machines that establish mutually cooperative relationships with people who may not share the machine's preferences. A main challenge has been that human cooperation does not require sheer computational power, but rather relies on intuition [11], cultural norms [12], emotions and signals [13, 14, 15, 16], and pre-evolved dispositions toward cooperation [17], common-sense mechanisms that are difficult to encode in machines for arbitrary contexts. Here, we combine a state-of-the-art machine-learning algorithm with novel mechanisms for generating and acting on signals to produce a new learning algorithm that cooperates with people and other machines at levels that rival human cooperation in a variety of two-player repeated stochastic games. This is the first general-purpose algorithm that is capable, given a description of a previously unseen game environment, of learning to cooperate with people within short timescales in scenarios previously unanticipated by algorithm designers. This is achieved without complex opponent modeling or higher-order theories of mind, thus showing that flexible, fast, and general human-machine cooperation is computationally achievable using a non-trivial, but ultimately simple, set of algorithmic mechanisms.
* An updated version of this paper was published in Nature Communications
Experimental Assessment of Aggregation Principles in Argumentation-enabled Collective Intelligence
Feb 12, 2017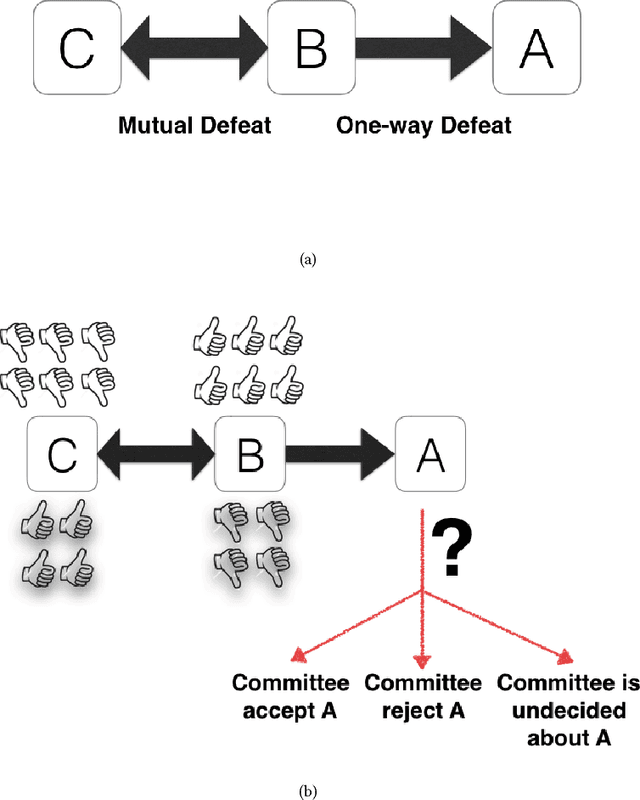

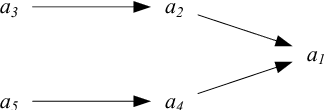
On the Web, there is always a need to aggregate opinions from the crowd (as in posts, social networks, forums, etc.). Different mechanisms have been implemented to capture these opinions such as "Like" in Facebook, "Favorite" in Twitter, thumbs-up/down, flagging, and so on. However, in more contested domains (e.g. Wikipedia, political discussion, and climate change discussion) these mechanisms are not sufficient since they only deal with each issue independently without considering the relationships between different claims. We can view a set of conflicting arguments as a graph in which the nodes represent arguments and the arcs between these nodes represent the defeat relation. A group of people can then collectively evaluate such graphs. To do this, the group must use a rule to aggregate their individual opinions about the entire argument graph. Here, we present the first experimental evaluation of different principles commonly employed by aggregation rules presented in the literature. We use randomized controlled experiments to investigate which principles people consider better at aggregating opinions under different conditions. Our analysis reveals a number of factors, not captured by traditional formal models, that play an important role in determining the efficacy of aggregation. These results help bring formal models of argumentation closer to real-world application.
On the Qualitative Comparison of Decisions Having Positive and Negative Features
Jan 15, 2014Making a decision is often a matter of listing and comparing positive and negative arguments. In such cases, the evaluation scale for decisions should be considered bipolar, that is, negative and positive values should be explicitly distinguished. That is what is done, for example, in Cumulative Prospect Theory. However, contraryto the latter framework that presupposes genuine numerical assessments, human agents often decide on the basis of an ordinal ranking of the pros and the cons, and by focusing on the most salient arguments. In other terms, the decision process is qualitative as well as bipolar. In this article, based on a bipolar extension of possibility theory, we define and axiomatically characterize several decision rules tailored for the joint handling of positive and negative arguments in an ordinal setting. The simplest rules can be viewed as extensions of the maximin and maximax criteria to the bipolar case, and consequently suffer from poor decisive power. More decisive rules that refine the former are also proposed. These refinements agree both with principles of efficiency and with the spirit of order-of-magnitude reasoning, that prevails in qualitative decision theory. The most refined decision rule uses leximin rankings of the pros and the cons, and the ideas of counting arguments of equal strength and cancelling pros by cons. It is shown to come down to a special case of Cumulative Prospect Theory, and to subsume the Take the Best heuristic studied by cognitive psychologists.