 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Behavior Trees from Goal-Oriented LTLf Formulas
Jul 12, 2023Temporal logic can be used to formally specify autonomous agent goals, but synthesizing planners that guarantee goal satisfaction can be computationally prohibitive. This paper shows how to turn goals specified using a subset of finite trace Linear Temporal Logic (LTL) into a behavior tree (BT) that guarantees that successful traces satisfy the LTL goal. Useful LTL formulas for achievement goals can be derived using achievement-oriented task mission grammars, leading to missions made up of tasks combined using LTL operators. Constructing BTs from LTL formulas leads to a relaxed behavior synthesis problem in which a wide range of planners can implement the action nodes in the BT. Importantly, any successful trace induced by the planners satisfies the corresponding LTL formula. The usefulness of the approach is demonstrated in two ways: a) exploring the alignment between two planners and LTL goals, and b) solving a sequential key-door problem for a Fetch robot.
Efficiently Evolving Swarm Behaviors Using Grammatical Evolution With PPA-style Behavior Trees
Mar 29, 2022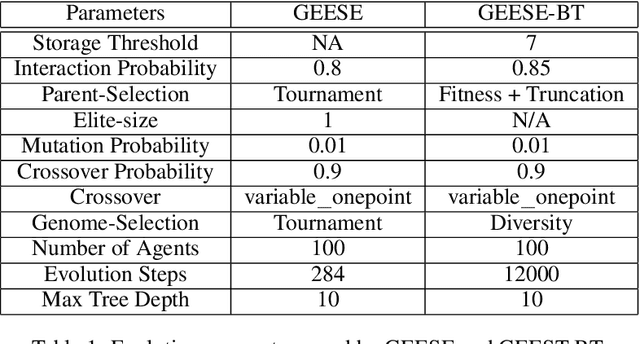
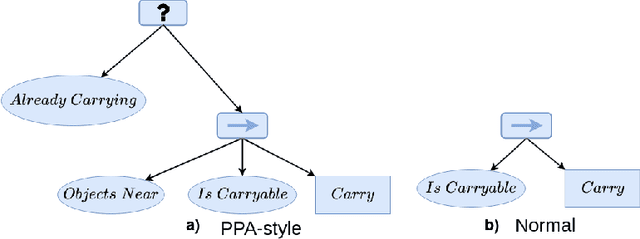
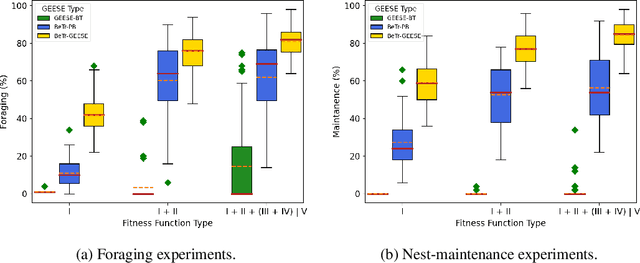
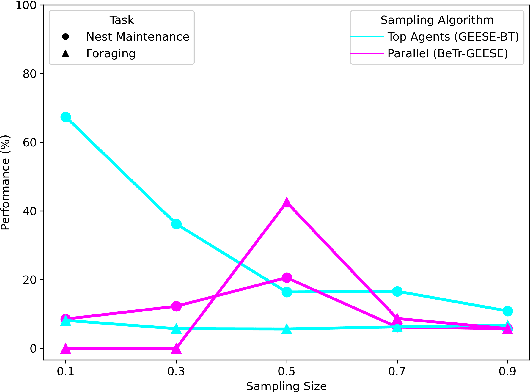
Evolving swarm behaviors with artificial agents is computationally expensive and challenging. Because reward structures are often sparse in swarm problems, only a few simulations among hundreds evolve successful swarm behaviors. Additionally, swarm evolutionary algorithms typically rely on ad hoc fitness structures, and novel fitness functions need to be designed for each swarm task. This paper evolves swarm behaviors by systematically combining Postcondition-Precondition-Action (PPA) canonical Behavior Trees (BT) with a Grammatical Evolution. The PPA structure replaces ad hoc reward structures with systematic postcondition checks, which allows a common grammar to learn solutions to different tasks using only environmental cues and BT feedback. The static performance of learned behaviors is poor because no agent learns all necessary subtasks, but performance while evolving is excellent because agents can quickly change behaviors in new contexts. The evolving algorithm succeeded in 75\% of learning trials for both foraging and nest maintenance tasks, an eight-fold improvement over prior work.
Predicting Plans and Actions in Two-Player Repeated Games
Apr 26, 2020


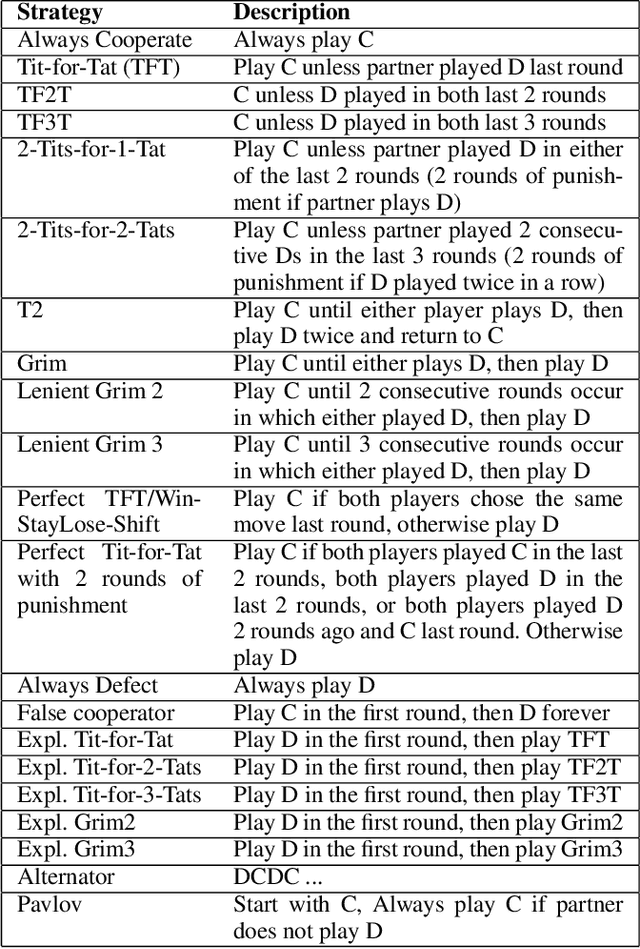
Artificial intelligence (AI) agents will need to interact with both other AI agents and humans. Creating models of associates help to predict the modeled agents' actions, plans, and intentions. This work introduces algorithms that predict actions, plans and intentions in repeated play games, with providing an exploration of algorithms. We form a generative Bayesian approach to model S#. S# is designed as a robust algorithm that learns to cooperate with its associate in 2 by 2 matrix games. The actions, plans and intentions associated with each S# expert are identified from the literature, grouping the S# experts accordingly, and thus predicting actions, plans, and intentions based on their state probabilities. Two prediction methods are explored for Prisoners Dilemma: the Maximum A Posteriori (MAP) and an Aggregation approach. MAP (~89% accuracy) performed the best for action prediction. Both methods predicted plans of S# with ~88% accuracy. Paired T-test shows that MAP performs significantly better than Aggregation for predicting S#'s actions without cheap talk. Intention is explored based on the goals of the S# experts; results show that goals are predicted precisely when modeling S#. The obtained results show that the proposed Bayesian approach is well suited for modeling agents in two-player repeated games.
Cooperating with Machines
Feb 21, 2018



Since Alan Turing envisioned Artificial Intelligence (AI) [1], a major driving force behind technical progress has been competition with human cognition. Historical milestones have been frequently associated with computers matching or outperforming humans in difficult cognitive tasks (e.g. face recognition [2], personality classification [3], driving cars [4], or playing video games [5]), or defeating humans in strategic zero-sum encounters (e.g. Chess [6], Checkers [7], Jeopardy! [8], Poker [9], or Go [10]). In contrast, less attention has been given to developing autonomous machines that establish mutually cooperative relationships with people who may not share the machine's preferences. A main challenge has been that human cooperation does not require sheer computational power, but rather relies on intuition [11], cultural norms [12], emotions and signals [13, 14, 15, 16], and pre-evolved dispositions toward cooperation [17], common-sense mechanisms that are difficult to encode in machines for arbitrary contexts. Here, we combine a state-of-the-art machine-learning algorithm with novel mechanisms for generating and acting on signals to produce a new learning algorithm that cooperates with people and other machines at levels that rival human cooperation in a variety of two-player repeated stochastic games. This is the first general-purpose algorithm that is capable, given a description of a previously unseen game environment, of learning to cooperate with people within short timescales in scenarios previously unanticipated by algorithm designers. This is achieved without complex opponent modeling or higher-order theories of mind, thus showing that flexible, fast, and general human-machine cooperation is computationally achievable using a non-trivial, but ultimately simple, set of algorithmic mechanisms.
* An updated version of this paper was published in Nature Communications