 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Evolving Swarm Behaviors Using Grammatical Evolution With PPA-style Behavior Trees
Paper and Code
Mar 29, 2022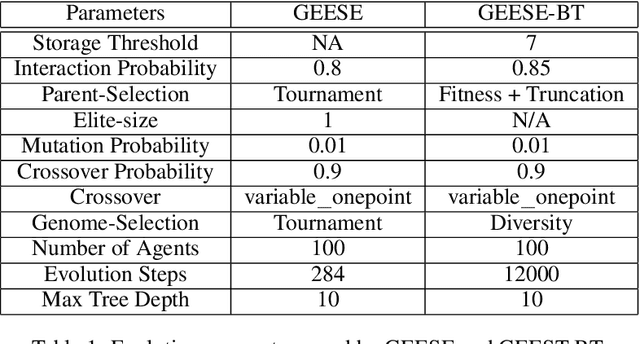
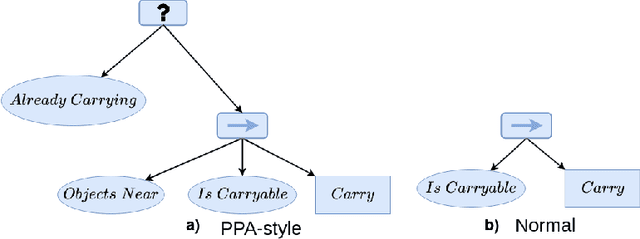
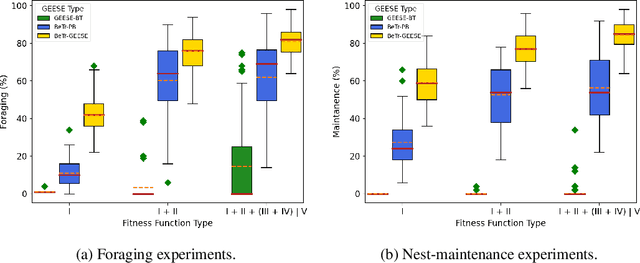
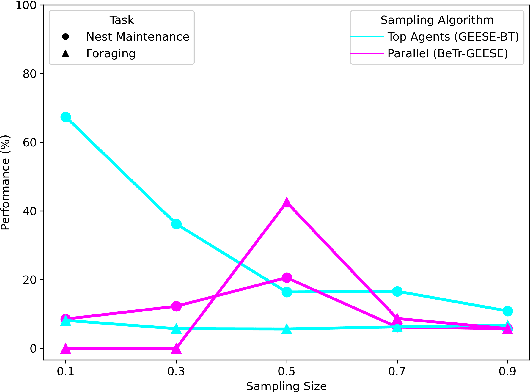
Evolving swarm behaviors with artificial agents is computationally expensive and challenging. Because reward structures are often sparse in swarm problems, only a few simulations among hundreds evolve successful swarm behaviors. Additionally, swarm evolutionary algorithms typically rely on ad hoc fitness structures, and novel fitness functions need to be designed for each swarm task. This paper evolves swarm behaviors by systematically combining Postcondition-Precondition-Action (PPA) canonical Behavior Trees (BT) with a Grammatical Evolution. The PPA structure replaces ad hoc reward structures with systematic postcondition checks, which allows a common grammar to learn solutions to different tasks using only environmental cues and BT feedback. The static performance of learned behaviors is poor because no agent learns all necessary subtasks, but performance while evolving is excellent because agents can quickly change behaviors in new contexts. The evolving algorithm succeeded in 75\% of learning trials for both foraging and nest maintenance tasks, an eight-fold improvement over prior work.