 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Human Behavior in a Strategic Network Game with Complex Group Dynamics
May 01, 2025Human networks greatly impact important societal outcomes, including wealth and health inequality, poverty, and bullying. As such, understanding human networks is critical to learning how to promote favorable societal outcomes. As a step toward better understanding human networks, we compare and contrast several methods for learning models of human behavior in a strategic network game called the Junior High Game (JHG). These modeling methods differ with respect to the assumptions they use to parameterize human behavior (behavior vs. community-aware behavior) and the statistical moments they model (mean vs. distribution). Results show that the highest-performing method models the population's distribution rather than the mean and assumes humans use community-aware behavior rather than behavior matching. When applied to small societies (6-11 individuals), this learned model, called hCAB, closely mirrors the population dynamics of human groups (with some differences). Additionally, a user study reveals that human participants were unable to distinguish hCAB agents from other humans, thus illustrating that individual hCAB behavior plausibly mirrors human behavior in this strategic network game.
Predicting Plans and Actions in Two-Player Repeated Games
Apr 26, 2020


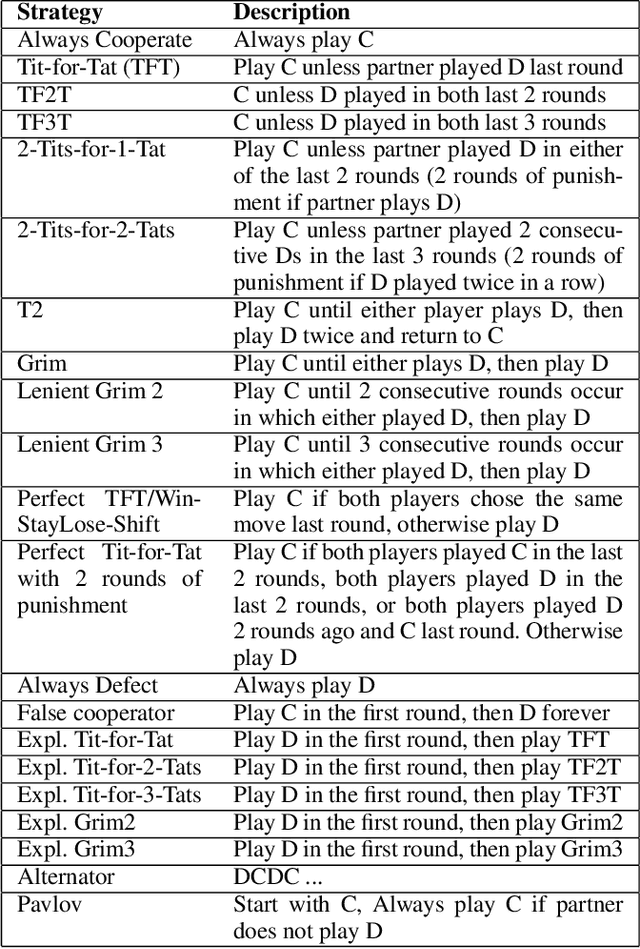
Artificial intelligence (AI) agents will need to interact with both other AI agents and humans. Creating models of associates help to predict the modeled agents' actions, plans, and intentions. This work introduces algorithms that predict actions, plans and intentions in repeated play games, with providing an exploration of algorithms. We form a generative Bayesian approach to model S#. S# is designed as a robust algorithm that learns to cooperate with its associate in 2 by 2 matrix games. The actions, plans and intentions associated with each S# expert are identified from the literature, grouping the S# experts accordingly, and thus predicting actions, plans, and intentions based on their state probabilities. Two prediction methods are explored for Prisoners Dilemma: the Maximum A Posteriori (MAP) and an Aggregation approach. MAP (~89% accuracy) performed the best for action prediction. Both methods predicted plans of S# with ~88% accuracy. Paired T-test shows that MAP performs significantly better than Aggregation for predicting S#'s actions without cheap talk. Intention is explored based on the goals of the S# experts; results show that goals are predicted precisely when modeling S#. The obtained results show that the proposed Bayesian approach is well suited for modeling agents in two-player repeated games.
E-HBA: Using Action Policies for Expert Advice and Agent Typification
Jul 23, 2019

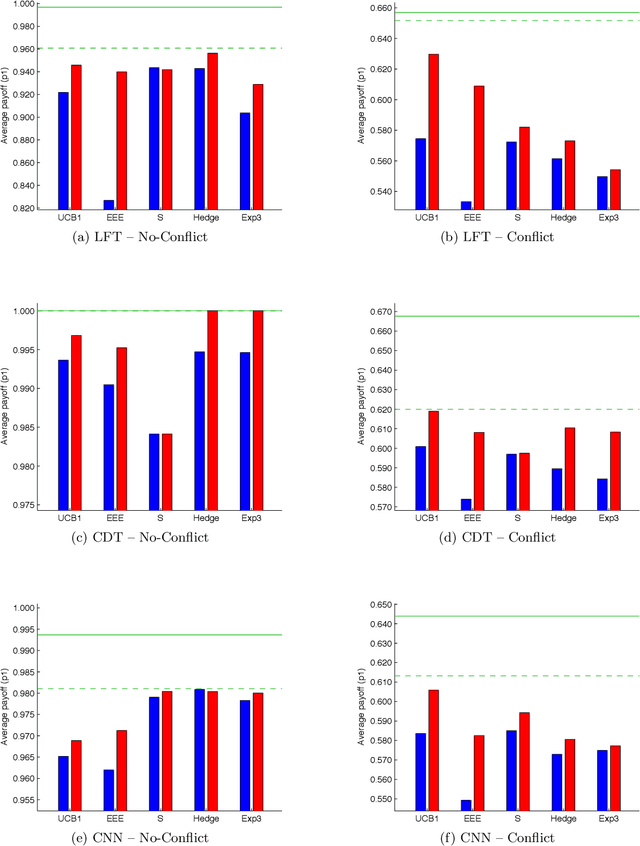

Past research has studied two approaches to utilise predefined policy sets in repeated interactions: as experts, to dictate our own actions, and as types, to characterise the behaviour of other agents. In this work, we bring these complementary views together in the form of a novel meta-algorithm, called Expert-HBA (E-HBA), which can be applied to any expert algorithm that considers the average (or total) payoff an expert has yielded in the past. E-HBA gradually mixes the past payoff with a predicted future payoff, which is computed using the type-based characterisation. We present results from a comprehensive set of repeated matrix games, comparing the performance of several well-known expert algorithms with and without the aid of E-HBA. Our results show that E-HBA has the potential to significantly improve the performance of expert algorithms.
An Empirical Study on the Practical Impact of Prior Beliefs over Policy Types
Jul 10, 2019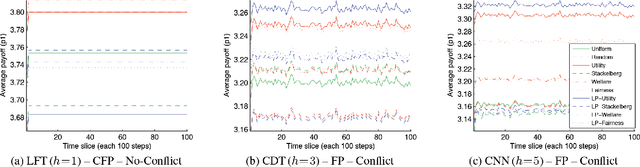

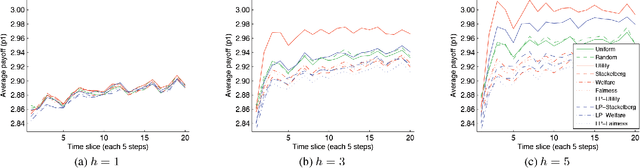

Many multiagent applications require an agent to learn quickly how to interact with previously unknown other agents. To address this problem, researchers have studied learning algorithms which compute posterior beliefs over a hypothesised set of policies, based on the observed actions of the other agents. The posterior belief is complemented by the prior belief, which specifies the subjective likelihood of policies before any actions are observed. In this paper, we present the first comprehensive empirical study on the practical impact of prior beliefs over policies in repeated interactions. We show that prior beliefs can have a significant impact on the long-term performance of such methods, and that the magnitude of the impact depends on the depth of the planning horizon. Moreover, our results demonstrate that automatic methods can be used to compute prior beliefs with consistent performance effects. This indicates that prior beliefs could be eliminated as a manual parameter and instead be computed automatically.
Information Design in Crowdfunding under Thresholding Policies
Mar 28, 2018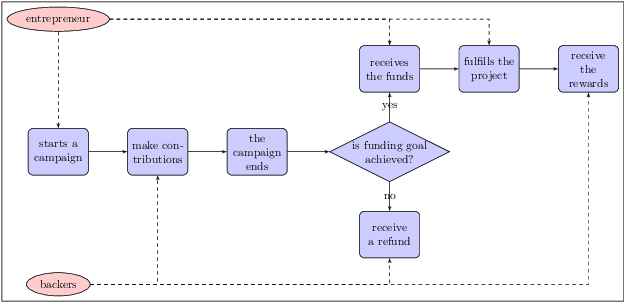
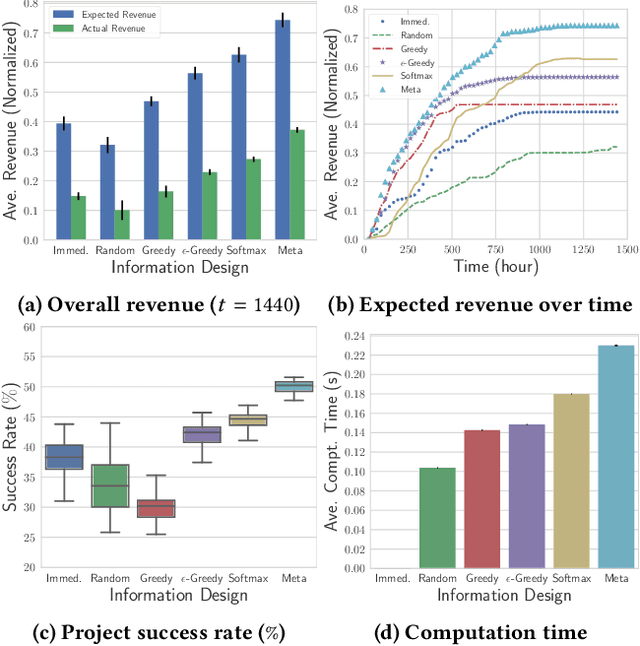
Crowdfunding has emerged as a prominent way for entrepreneurs to secure funding without sophisticated intermediation. In crowdfunding, an entrepreneur often has to decide how to disclose the campaign status in order to collect as many contributions as possible. Such decisions are difficult to make primarily due to incomplete information. We propose information design as a tool to help the entrepreneur to improve revenue by influencing backers' beliefs. We introduce a heuristic algorithm to dynamically compute information-disclosure policies for the entrepreneur, followed by an empirical evaluation to demonstrate its competitiveness over the widely-adopted immediate-disclosure policy. Our results demonstrate that the immediate-disclosure policy is not optimal when backers follow thresholding policies despite its ease of implementation. With appropriate heuristics, an entrepreneur can benefit from dynamic information disclosure. Our work sheds light on information design in a dynamic setting where agents make decisions using thresholding policies.
Cooperating with Machines
Feb 21, 2018



Since Alan Turing envisioned Artificial Intelligence (AI) [1], a major driving force behind technical progress has been competition with human cognition. Historical milestones have been frequently associated with computers matching or outperforming humans in difficult cognitive tasks (e.g. face recognition [2], personality classification [3], driving cars [4], or playing video games [5]), or defeating humans in strategic zero-sum encounters (e.g. Chess [6], Checkers [7], Jeopardy! [8], Poker [9], or Go [10]). In contrast, less attention has been given to developing autonomous machines that establish mutually cooperative relationships with people who may not share the machine's preferences. A main challenge has been that human cooperation does not require sheer computational power, but rather relies on intuition [11], cultural norms [12], emotions and signals [13, 14, 15, 16], and pre-evolved dispositions toward cooperation [17], common-sense mechanisms that are difficult to encode in machines for arbitrary contexts. Here, we combine a state-of-the-art machine-learning algorithm with novel mechanisms for generating and acting on signals to produce a new learning algorithm that cooperates with people and other machines at levels that rival human cooperation in a variety of two-player repeated stochastic games. This is the first general-purpose algorithm that is capable, given a description of a previously unseen game environment, of learning to cooperate with people within short timescales in scenarios previously unanticipated by algorithm designers. This is achieved without complex opponent modeling or higher-order theories of mind, thus showing that flexible, fast, and general human-machine cooperation is computationally achievable using a non-trivial, but ultimately simple, set of algorithmic mechanisms.
* An updated version of this paper was published in Nature Communications
Non-myopic learning in repeated stochastic games
Jan 19, 2018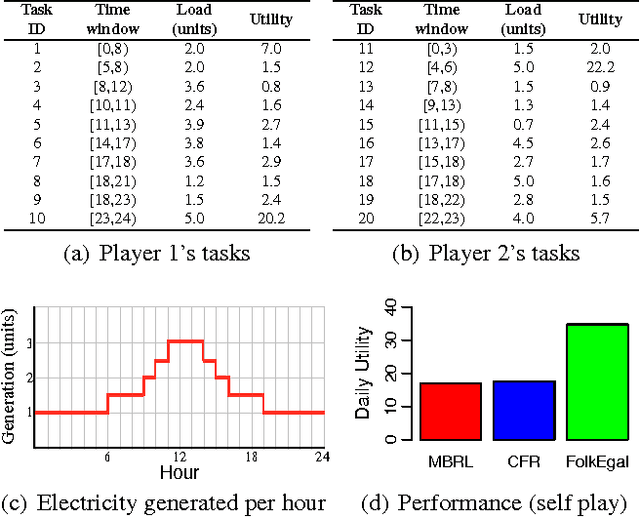
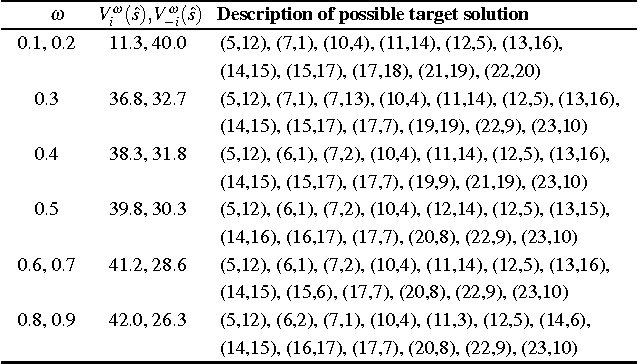


In repeated stochastic games (RSGs), an agent must quickly adapt to the behavior of previously unknown associates, who may themselves be learning. This machine-learning problem is particularly challenging due, in part, to the presence of multiple (even infinite) equilibria and inherently large strategy spaces. In this paper, we introduce a method to reduce the strategy space of two-player general-sum RSGs to a handful of expert strategies. This process, called Mega, effectually reduces an RSG to a bandit problem. We show that the resulting strategy space preserves several important properties of the original RSG, thus enabling a learner to produce robust strategies within a reasonably small number of interactions. To better establish strengths and weaknesses of this approach, we empirically evaluate the resulting learning system against other algorithms in three different RSGs.
Regulating Highly Automated Robot Ecologies: Insights from Three User Studies
Aug 07, 2017

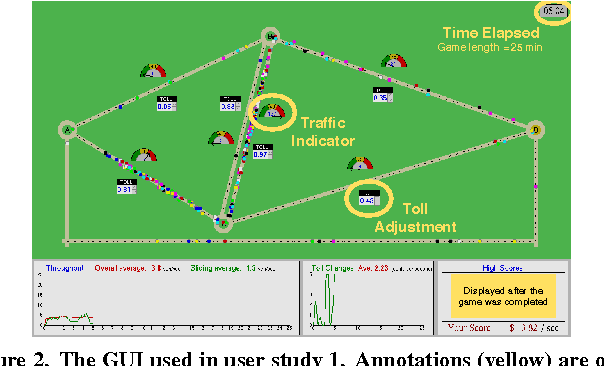
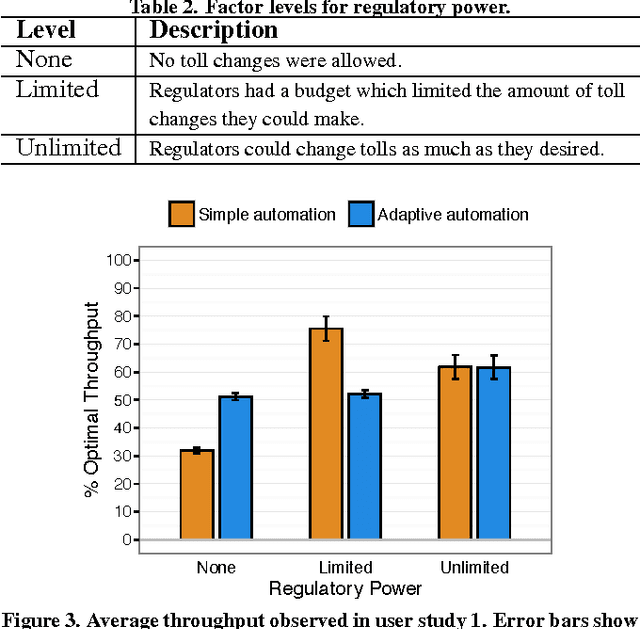
Highly automated robot ecologies (HARE), or societies of independent autonomous robots or agents, are rapidly becoming an important part of much of the world's critical infrastructure. As with human societies, regulation, wherein a governing body designs rules and processes for the society, plays an important role in ensuring that HARE meet societal objectives. However, to date, a careful study of interactions between a regulator and HARE is lacking. In this paper, we report on three user studies which give insights into how to design systems that allow people, acting as the regulatory authority, to effectively interact with HARE. As in the study of political systems in which governments regulate human societies, our studies analyze how interactions between HARE and regulators are impacted by regulatory power and individual (robot or agent) autonomy. Our results show that regulator power, decision support, and adaptive autonomy can each diminish the social welfare of HARE, and hint at how these seemingly desirable mechanisms can be designed so that they become part of successful HARE.
* 10 pages, 7 figures, to appear in the 5th International Conference on Human Agent Interaction (HAI-2017), Bielefeld, Germany
An Online Mechanism for Ridesharing in Autonomous Mobility-on-Demand Systems
Mar 02, 2017


With proper management, Autonomous Mobility-on-Demand (AMoD) systems have great potential to satisfy the transport demands of urban populations by providing safe, convenient, and affordable ridesharing services. Meanwhile, such systems can substantially decrease private car ownership and use, and thus significantly reduce traffic congestion, energy consumption, and carbon emissions. To achieve this objective, an AMoD system requires private information about the demand from passengers. However, due to self-interestedness, passengers are unlikely to cooperate with the service providers in this regard. Therefore, an online mechanism is desirable if it incentivizes passengers to truthfully report their actual demand. For the purpose of promoting ridesharing, we hereby introduce a posted-price, integrated online ridesharing mechanism (IORS) that satisfies desirable properties such as ex-post incentive compatibility, individual rationality, and budget-balance. Numerical results indicate the competitiveness of IORS compared with two benchmarks, namely the optimal assignment and an offline, auction-based mechanism.
Belief and Truth in Hypothesised Behaviours
Mar 02, 2016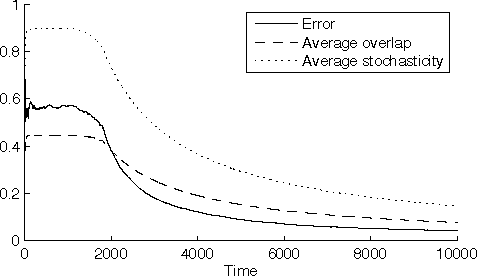
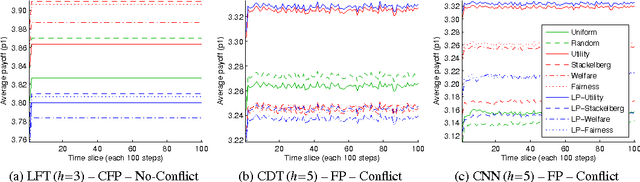

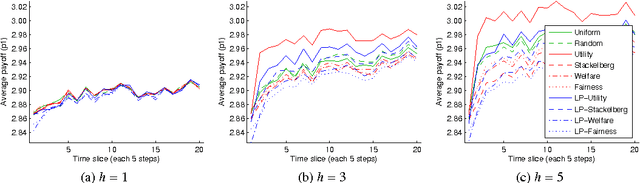
There is a long history in game theory on the topic of Bayesian or "rational" learning, in which each player maintains beliefs over a set of alternative behaviours, or types, for the other players. This idea has gained increasing interest in the artificial intelligence (AI) community, where it is used as a method to control a single agent in a system composed of multiple agents with unknown behaviours. The idea is to hypothesise a set of types, each specifying a possible behaviour for the other agents, and to plan our own actions with respect to those types which we believe are most likely, given the observed actions of the agents. The game theory literature studies this idea primarily in the context of equilibrium attainment. In contrast, many AI applications have a focus on task completion and payoff maximisation. With this perspective in mind, we identify and address a spectrum of questions pertaining to belief and truth in hypothesised types. We formulate three basic ways to incorporate evidence into posterior beliefs and show when the resulting beliefs are correct, and when they may fail to be correct. Moreover, we demonstrate that prior beliefs can have a significant impact on our ability to maximise payoffs in the long-term, and that they can be computed automatically with consistent performance effects. Furthermore, we analyse the conditions under which we are able complete our task optimally, despite inaccuracies in the hypothesised types. Finally, we show how the correctness of hypothesised types can be ascertained during the interaction via an automated statistical analysis.