 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-HBA: Using Action Policies for Expert Advice and Agent Typification
Paper and Code
Jul 23, 2019

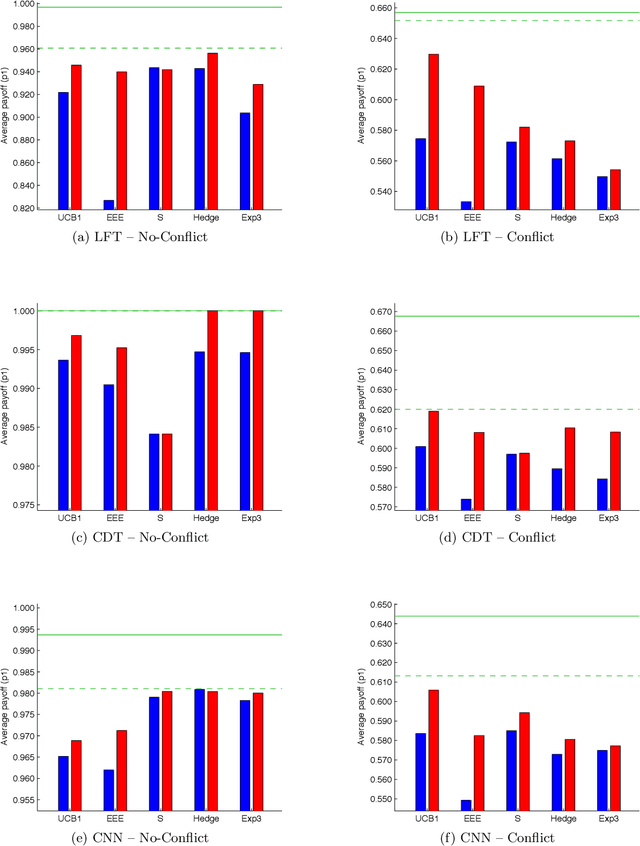

Past research has studied two approaches to utilise predefined policy sets in repeated interactions: as experts, to dictate our own actions, and as types, to characterise the behaviour of other agents. In this work, we bring these complementary views together in the form of a novel meta-algorithm, called Expert-HBA (E-HBA), which can be applied to any expert algorithm that considers the average (or total) payoff an expert has yielded in the past. E-HBA gradually mixes the past payoff with a predicted future payoff, which is computed using the type-based characterisation. We present results from a comprehensive set of repeated matrix games, comparing the performance of several well-known expert algorithms with and without the aid of E-HBA. Our results show that E-HBA has the potential to significantly improve the performance of expert algorithms.