 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-myopic learning in repeated stochastic games
Paper and Code
Jan 19, 2018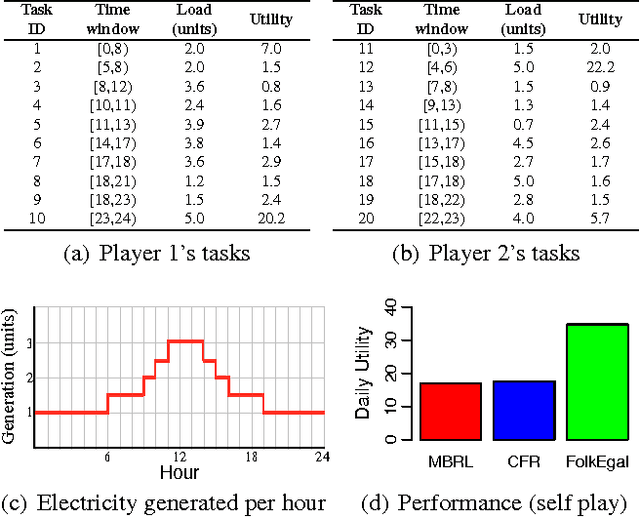
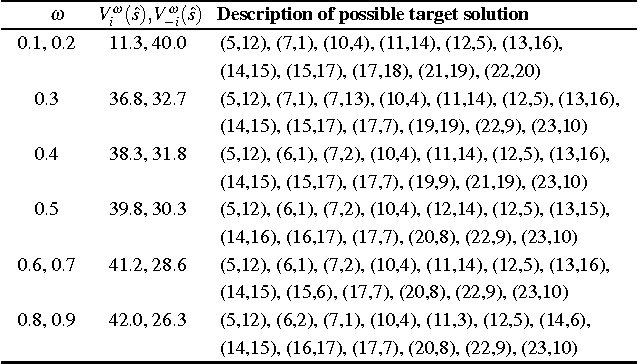


In repeated stochastic games (RSGs), an agent must quickly adapt to the behavior of previously unknown associates, who may themselves be learning. This machine-learning problem is particularly challenging due, in part, to the presence of multiple (even infinite) equilibria and inherently large strategy spaces. In this paper, we introduce a method to reduce the strategy space of two-player general-sum RSGs to a handful of expert strategies. This process, called Mega, effectually reduces an RSG to a bandit problem. We show that the resulting strategy space preserves several important properties of the original RSG, thus enabling a learner to produce robust strategies within a reasonably small number of interactions. To better establish strengths and weaknesses of this approach, we empirically evaluate the resulting learning system against other algorithms in three different RSGs.