 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Are Combinations of Humans and AI Useful?
May 09, 2024Inspired by the increasing use of AI to augment humans, researchers have studied human-AI systems involving different tasks, systems, and populations. Despite such a large body of work, we lack a broad conceptual understanding of when combinations of humans and AI are better than either alone. Here, we addressed this question by conducting a meta-analysis of over 100 recent experimental studies reporting over 300 effect sizes. First, we found that, on average, human-AI combinations performed significantly worse than the best of humans or AI alone. Second, we found performance losses in tasks that involved making decisions and significantly greater gains in tasks that involved creating content. Finally, when humans outperformed AI alone, we found performance gains in the combination, but when the AI outperformed humans alone we found losses. These findings highlight the heterogeneity of the effects of human-AI collaboration and point to promising avenues for improving human-AI systems.
Experimental Assessment of Aggregation Principles in Argumentation-enabled Collective Intelligence
Feb 12, 2017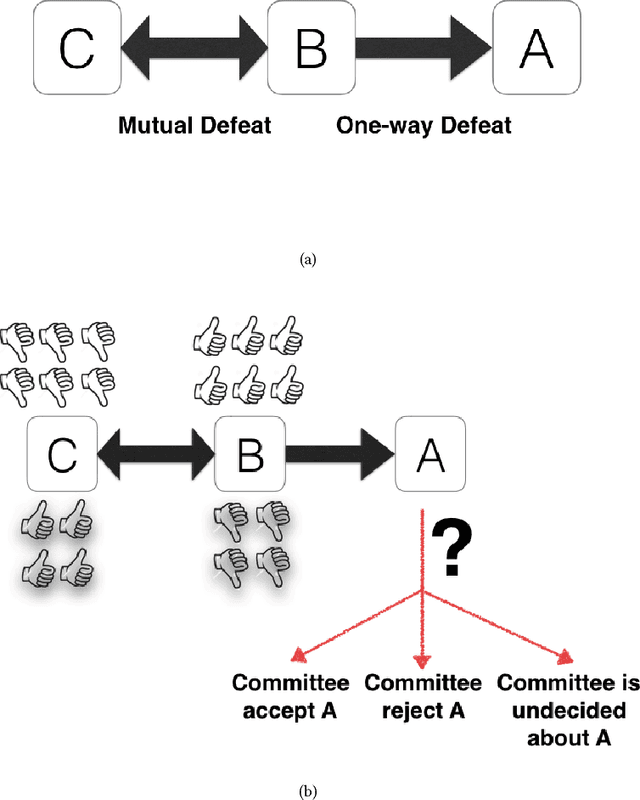

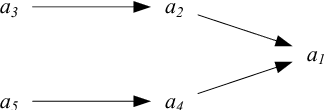
On the Web, there is always a need to aggregate opinions from the crowd (as in posts, social networks, forums, etc.). Different mechanisms have been implemented to capture these opinions such as "Like" in Facebook, "Favorite" in Twitter, thumbs-up/down, flagging, and so on. However, in more contested domains (e.g. Wikipedia, political discussion, and climate change discussion) these mechanisms are not sufficient since they only deal with each issue independently without considering the relationships between different claims. We can view a set of conflicting arguments as a graph in which the nodes represent arguments and the arcs between these nodes represent the defeat relation. A group of people can then collectively evaluate such graphs. To do this, the group must use a rule to aggregate their individual opinions about the entire argument graph. Here, we present the first experimental evaluation of different principles commonly employed by aggregation rules presented in the literature. We use randomized controlled experiments to investigate which principles people consider better at aggregating opinions under different conditions. Our analysis reveals a number of factors, not captured by traditional formal models, that play an important role in determining the efficacy of aggregation. These results help bring formal models of argumentation closer to real-world application.