 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Social Learning and Collective Norm Formation in Fostering Cooperation in LLM Multi-Agent Systems
Oct 16, 2025A growing body of multi-agent studies with Large Language Models (LLMs) explores how norms and cooperation emerge in mixed-motive scenarios, where pursuing individual gain can undermine the collective good. While prior work has explored these dynamics in both richly contextualized simulations and simplified game-theoretic environments, most LLM systems featuring common-pool resource (CPR) games provide agents with explicit reward functions directly tied to their actions. In contrast, human cooperation often emerges without full visibility into payoffs and population, relying instead on heuristics, communication, and punishment. We introduce a CPR simulation framework that removes explicit reward signals and embeds cultural-evolutionary mechanisms: social learning (adopting strategies and beliefs from successful peers) and norm-based punishment, grounded in Ostrom's principles of resource governance. Agents also individually learn from the consequences of harvesting, monitoring, and punishing via environmental feedback, enabling norms to emerge endogenously. We establish the validity of our simulation by reproducing key findings from existing studies on human behavior. Building on this, we examine norm evolution across a $2\times2$ grid of environmental and social initialisations (resource-rich vs. resource-scarce; altruistic vs. selfish) and benchmark how agentic societies comprised of different LLMs perform under these conditions. Our results reveal systematic model differences in sustaining cooperation and norm formation, positioning the framework as a rigorous testbed for studying emergent norms in mixed-motive LLM societies. Such analysis can inform the design of AI systems deployed in social and organizational contexts, where alignment with cooperative norms is critical for stability, fairness, and effective governance of AI-mediated environments.
Alien Recombination: Exploring Concept Blends Beyond Human Cognitive Availability in Visual Art
Nov 18, 2024
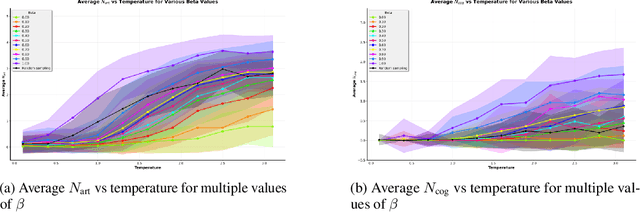
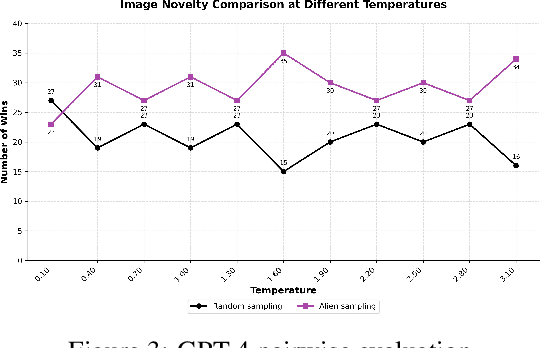
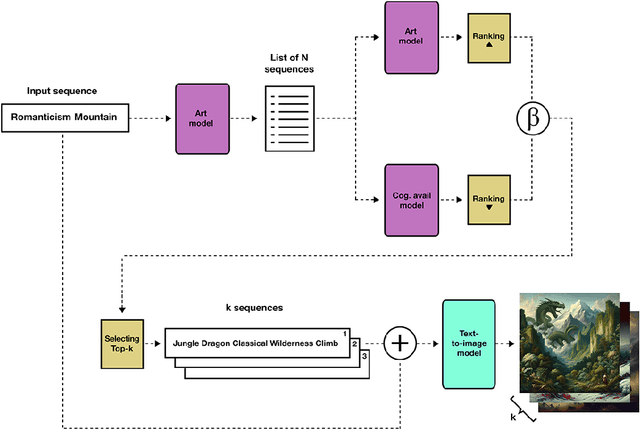
While AI models have demonstrated remarkable capabilities in constrained domains like game strategy, their potential for genuine creativity in open-ended domains like art remains debated. We explore this question by examining how AI can transcend human cognitive limitations in visual art creation. Our research hypothesizes that visual art contains a vast unexplored space of conceptual combinations, constrained not by inherent incompatibility, but by cognitive limitations imposed by artists' cultural, temporal, geographical and social contexts. To test this hypothesis, we present the Alien Recombination method, a novel approach utilizing fine-tuned large language models to identify and generate concept combinations that lie beyond human cognitive availability. The system models and deliberately counteracts human availability bias, the tendency to rely on immediately accessible examples, to discover novel artistic combinations. This system not only produces combinations that have never been attempted before within our dataset but also identifies and generates combinations that are cognitively unavailable to all artists in the domain. Furthermore, we translate these combinations into visual representations, enabling the exploration of subjective perceptions of novelty. Our findings suggest that cognitive unavailability is a promising metric for optimizing artistic novelty, outperforming merely temperature scaling without additional evaluation criteria. This approach uses generative models to connect previously unconnected ideas, providing new insight into the potential of framing AI-driven creativity as a combinatorial problem.
Empirical evidence of Large Language Model's influence on human spoken communication
Sep 03, 2024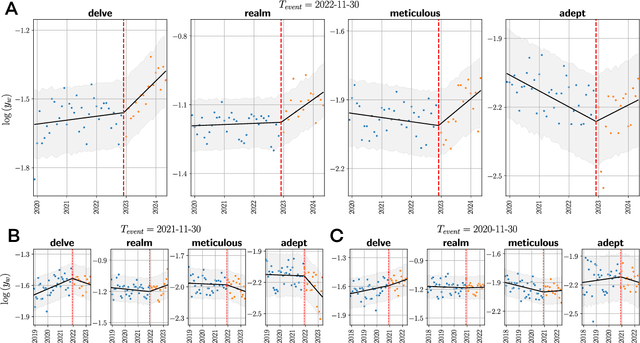
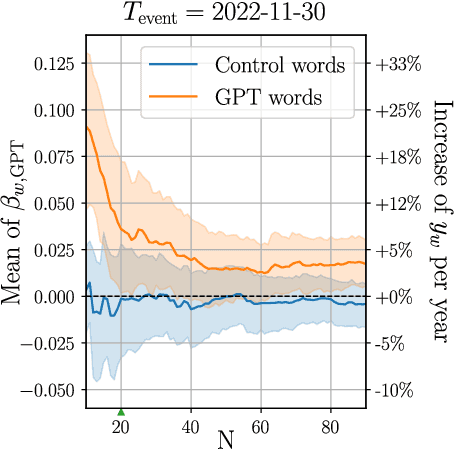
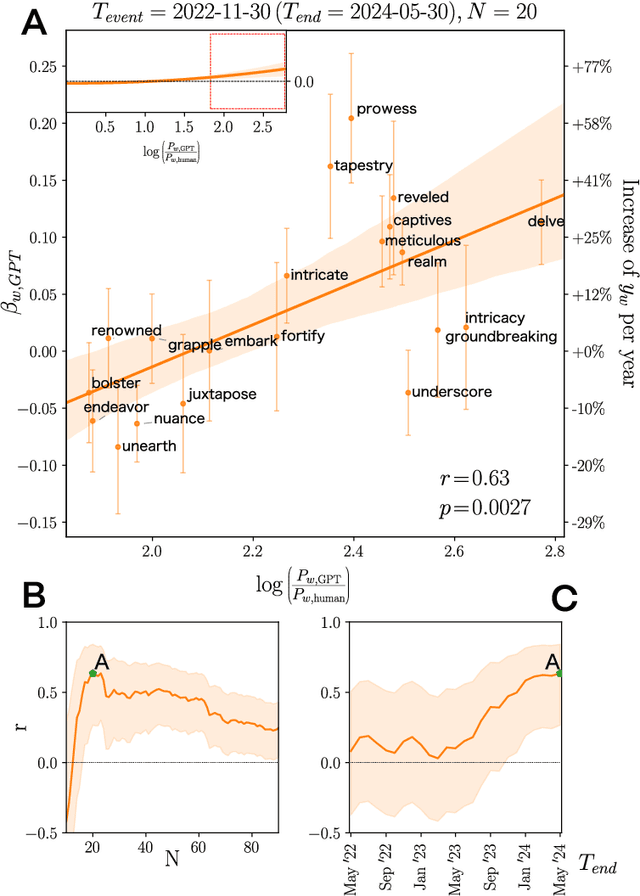

Artificial Intelligence (AI) agents now interact with billions of humans in natural language, thanks to advances in Large Language Models (LLMs) like ChatGPT. This raises the question of whether AI has the potential to shape a fundamental aspect of human culture: the way we speak. Recent analyses revealed that scientific publications already exhibit evidence of AI-specific language. But this evidence is inconclusive, since scientists may simply be using AI to copy-edit their writing. To explore whether AI has influenced human spoken communication, we transcribed and analyzed about 280,000 English-language videos of presentations, talks, and speeches from more than 20,000 YouTube channels of academic institutions. We find a significant shift in the trend of word usage specific to words distinctively associated with ChatGPT following its release. These findings provide the first empirical evidence that humans increasingly imitate LLMs in their spoken language. Our results raise societal and policy-relevant concerns about the potential of AI to unintentionally reduce linguistic diversity, or to be deliberately misused for mass manipulation. They also highlight the need for further investigation into the feedback loops between machine behavior and human culture.
PrISM-Observer: Intervention Agent to Help Users Perform Everyday Procedures Sensed using a Smartwatch
Jul 23, 2024We routinely perform procedures (such as cooking) that include a set of atomic steps. Often, inadvertent omission or misordering of a single step can lead to serious consequences, especially for those experiencing cognitive challenges such as dementia. This paper introduces PrISM-Observer, a smartwatch-based, context-aware, real-time intervention system designed to support daily tasks by preventing errors. Unlike traditional systems that require users to seek out information, the agent observes user actions and intervenes proactively. This capability is enabled by the agent's ability to continuously update its belief in the user's behavior in real-time through multimodal sensing and forecast optimal intervention moments and methods. We first validated the steps-tracking performance of our framework through evaluations across three datasets with different complexities. Then, we implemented a real-time agent system using a smartwatch and conducted a user study in a cooking task scenario. The system generated helpful interventions, and we gained positive feedback from the participants. The general applicability of PrISM-Observer to daily tasks promises broad applications, for instance, including support for users requiring more involved interventions, such as people with dementia or post-surgical patients.
Coaching Copilot: Blended Form of an LLM-Powered Chatbot and a Human Coach to Effectively Support Self-Reflection for Leadership Growth
May 24, 2024



Chatbots' role in fostering self-reflection is now widely recognized, especially in inducing users' behavior change. While the benefits of 24/7 availability, scalability, and consistent responses have been demonstrated in contexts such as healthcare and tutoring to help one form a new habit, their utilization in coaching necessitating deeper introspective dialogue to induce leadership growth remains unexplored. This paper explores the potential of such a chatbot powered by recent Large Language Models (LLMs) in collaboration with professional coaches in the field of executive coaching. Through a design workshop with them and two weeks of user study involving ten coach-client pairs, we explored the feasibility and nuances of integrating chatbots to complement human coaches. Our findings highlight the benefits of chatbots' ubiquity and reasoning capabilities enabled by LLMs while identifying their limitations and design necessities for effective collaboration between human coaches and chatbots. By doing so, this work contributes to the foundation for augmenting one's self-reflective process with prevalent conversational agents through the human-in-the-loop approach.
Supporting Experts with a Multimodal Machine-Learning-Based Tool for Human Behavior Analysis of Conversational Videos
Feb 17, 2024Multimodal scene search of conversations is essential for unlocking valuable insights into social dynamics and enhancing our communication. While experts in conversational analysis have their own knowledge and skills to find key scenes, a lack of comprehensive, user-friendly tools that streamline the processing of diverse multimodal queries impedes efficiency and objectivity. To solve it, we developed Providence, a visual-programming-based tool based on design considerations derived from a formative study with experts. It enables experts to combine various machine learning algorithms to capture human behavioral cues without writing code. Our study showed its preferable usability and satisfactory output with less cognitive load imposed in accomplishing scene search tasks of conversations, verifying the importance of its customizability and transparency. Furthermore, through the in-the-wild trial, we confirmed the objectivity and reusability of the tool transform experts' workflow, suggesting the advantage of expert-AI teaming in a highly human-contextual domain.
Evaluating large language models' ability to understand metaphor and sarcasm using a screening test for Asperger syndrome
Sep 19, 2023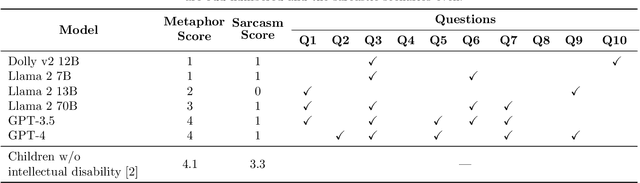
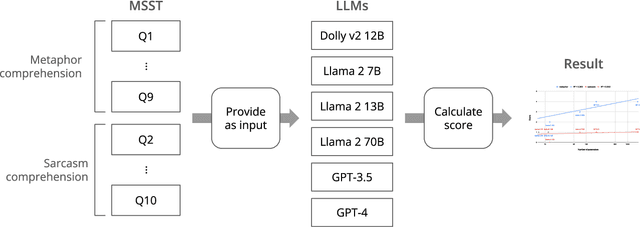
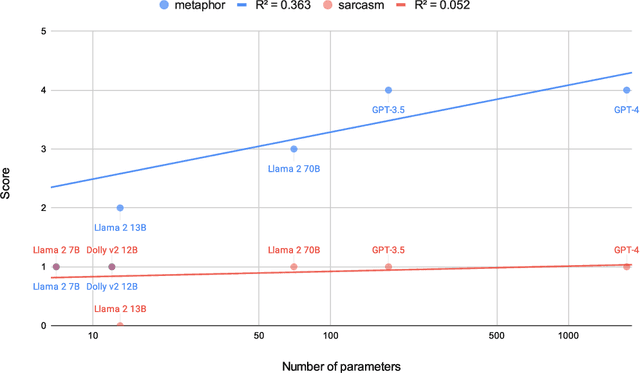
Metaphors and sarcasm are precious fruits of our highly-evolved social communication skills. However, children with Asperger syndrome are known to have difficulties in comprehending sarcasm, even if they possess a certain level of verbal IQ sufficient for understanding metaphors. Given that, a screening test that scores the ability to understand metaphor and sarcasm has been used to differentiate Asperger syndrome from other symptoms exhibiting akin external behaviors (e.g., attention-deficit/hyperactivity disorder). This study uses the standardized test to examine the capability of recent large language models (LLMs) in understanding human nuanced communication. The results divulged that, whereas their ability to comprehend metaphors has been improved with the increase of the number of model parameters, the improvement in sarcasm understanding was not observed. This implies that an alternative approach is imperative to imbue LLMs with the capacity to grasp sarcasm, which has been associated with the amygdala, a pivotal cerebral region for emotional learning, in the case of humans.
IteraTTA: An interface for exploring both text prompts and audio priors in generating music with text-to-audio models
Jul 24, 2023

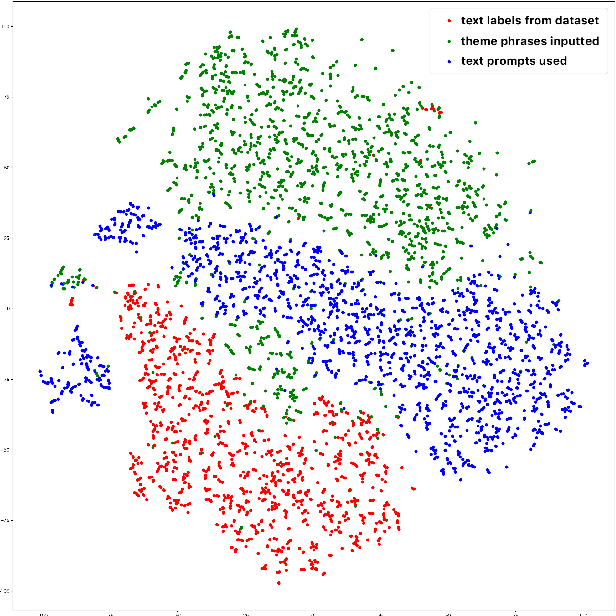

Recent text-to-audio generation techniques have the potential to allow novice users to freely generate music audio. Even if they do not have musical knowledge, such as about chord progressions and instruments, users can try various text prompts to generate audio. However, compared to the image domain, gaining a clear understanding of the space of possible music audios is difficult because users cannot listen to the variations of the generated audios simultaneously. We therefore facilitate users in exploring not only text prompts but also audio priors that constrain the text-to-audio music generation process. This dual-sided exploration enables users to discern the impact of different text prompts and audio priors on the generation results through iterative comparison of them. Our developed interface, IteraTTA, is specifically designed to aid users in refining text prompts and selecting favorable audio priors from the generated audios. With this, users can progressively reach their loosely-specified goals while understanding and exploring the space of possible results. Our implementation and discussions highlight design considerations that are specifically required for text-to-audio models and how interaction techniques can contribute to their effectiveness.
CatAlyst: Domain-Extensible Intervention for Preventing Task Procrastination Using Large Generative Models
Feb 11, 2023
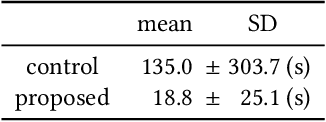

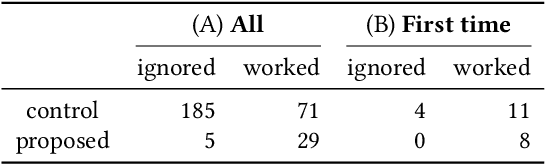
CatAlyst uses generative models to help workers' progress by influencing their task engagement instead of directly contributing to their task outputs. It prompts distracted workers to resume their tasks by generating a continuation of their work and presenting it as an intervention that is more context-aware than conventional (predetermined) feedback. The prompt can function by drawing their interest and lowering the hurdle for resumption even when the generated continuation is insufficient to substitute their work, while recent human-AI collaboration research aiming at work substitution depends on a stable high accuracy. This frees CatAlyst from domain-specific model-tuning and makes it applicable to various tasks. Our studies involving writing and slide-editing tasks demonstrated CatAlyst's effectiveness in helping workers swiftly resume tasks with a lowered cognitive load. The results suggest a new form of human-AI collaboration where large generative models publicly available but imperfect for each individual domain can contribute to workers' digital well-being.
SLOPT: Bandit Optimization Framework for Mutation-Based Fuzzing
Nov 07, 2022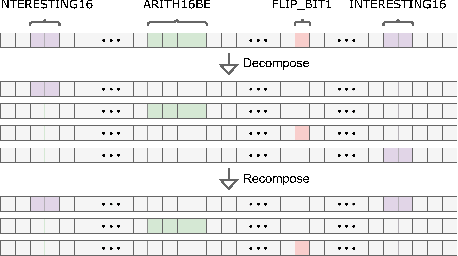

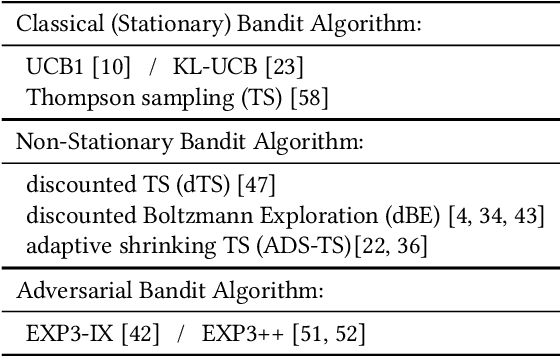
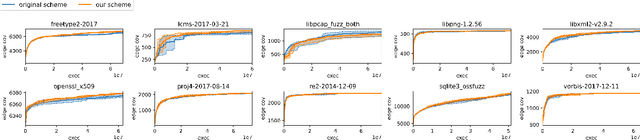
Mutation-based fuzzing has become one of the most common vulnerability discovery solutions over the last decade. Fuzzing can be optimized when targeting specific programs, and given that, some studies have employed online optimization methods to do it automatically, i.e., tuning fuzzers for any given program in a program-agnostic manner. However, previous studies have neither fully explored mutation schemes suitable for online optimization methods, nor online optimization methods suitable for mutation schemes. In this study, we propose an optimization framework called SLOPT that encompasses both a bandit-friendly mutation scheme and mutation-scheme-friendly bandit algorithms. The advantage of SLOPT is that it can generally be incorporated into existing fuzzers, such as AFL and Honggfuzz. As a proof of concept, we implemented SLOPT-AFL++ by integrating SLOPT into AFL++ and showed that the program-agnostic optimization delivered by SLOPT enabled SLOPT-AFL++ to achieve higher code coverage than AFL++ in all of ten real-world FuzzBench programs. Moreover, we ran SLOPT-AFL++ against several real-world programs from OSS-Fuzz and successfully identified three previously unknown vulnerabilities, even though these programs have been fuzzed by AFL++ for a considerable number of CPU days on OSS-Fuzz.