 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegative to Positive Co-learning with Aggressive Modality Dropout
Jan 01, 2025This paper aims to document an effective way to improve multimodal co-learning by using aggressive modality dropout. We find that by using aggressive modality dropout we are able to reverse negative co-learning (NCL) to positive co-learning (PCL). Aggressive modality dropout can be used to "prep" a multimodal model for unimodal deployment, and dramatically increases model performance during negative co-learning, where during some experiments we saw a 20% gain in accuracy. We also benchmark our modality dropout technique against PCL to show that our modality drop out technique improves co-learning during PCL, although it does not have as much as an substantial effect as it does during NCL. Github: https://github.com/nmagal/modality_drop_for_colearning
PrISM-Observer: Intervention Agent to Help Users Perform Everyday Procedures Sensed using a Smartwatch
Jul 23, 2024We routinely perform procedures (such as cooking) that include a set of atomic steps. Often, inadvertent omission or misordering of a single step can lead to serious consequences, especially for those experiencing cognitive challenges such as dementia. This paper introduces PrISM-Observer, a smartwatch-based, context-aware, real-time intervention system designed to support daily tasks by preventing errors. Unlike traditional systems that require users to seek out information, the agent observes user actions and intervenes proactively. This capability is enabled by the agent's ability to continuously update its belief in the user's behavior in real-time through multimodal sensing and forecast optimal intervention moments and methods. We first validated the steps-tracking performance of our framework through evaluations across three datasets with different complexities. Then, we implemented a real-time agent system using a smartwatch and conducted a user study in a cooking task scenario. The system generated helpful interventions, and we gained positive feedback from the participants. The general applicability of PrISM-Observer to daily tasks promises broad applications, for instance, including support for users requiring more involved interventions, such as people with dementia or post-surgical patients.
Coaching Copilot: Blended Form of an LLM-Powered Chatbot and a Human Coach to Effectively Support Self-Reflection for Leadership Growth
May 24, 2024



Chatbots' role in fostering self-reflection is now widely recognized, especially in inducing users' behavior change. While the benefits of 24/7 availability, scalability, and consistent responses have been demonstrated in contexts such as healthcare and tutoring to help one form a new habit, their utilization in coaching necessitating deeper introspective dialogue to induce leadership growth remains unexplored. This paper explores the potential of such a chatbot powered by recent Large Language Models (LLMs) in collaboration with professional coaches in the field of executive coaching. Through a design workshop with them and two weeks of user study involving ten coach-client pairs, we explored the feasibility and nuances of integrating chatbots to complement human coaches. Our findings highlight the benefits of chatbots' ubiquity and reasoning capabilities enabled by LLMs while identifying their limitations and design necessities for effective collaboration between human coaches and chatbots. By doing so, this work contributes to the foundation for augmenting one's self-reflective process with prevalent conversational agents through the human-in-the-loop approach.
Supporting Experts with a Multimodal Machine-Learning-Based Tool for Human Behavior Analysis of Conversational Videos
Feb 17, 2024Multimodal scene search of conversations is essential for unlocking valuable insights into social dynamics and enhancing our communication. While experts in conversational analysis have their own knowledge and skills to find key scenes, a lack of comprehensive, user-friendly tools that streamline the processing of diverse multimodal queries impedes efficiency and objectivity. To solve it, we developed Providence, a visual-programming-based tool based on design considerations derived from a formative study with experts. It enables experts to combine various machine learning algorithms to capture human behavioral cues without writing code. Our study showed its preferable usability and satisfactory output with less cognitive load imposed in accomplishing scene search tasks of conversations, verifying the importance of its customizability and transparency. Furthermore, through the in-the-wild trial, we confirmed the objectivity and reusability of the tool transform experts' workflow, suggesting the advantage of expert-AI teaming in a highly human-contextual domain.
IMUPoser: Full-Body Pose Estimation using IMUs in Phones, Watches, and Earbuds
Apr 25, 2023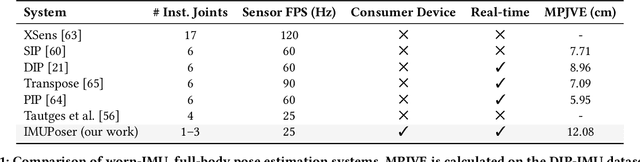
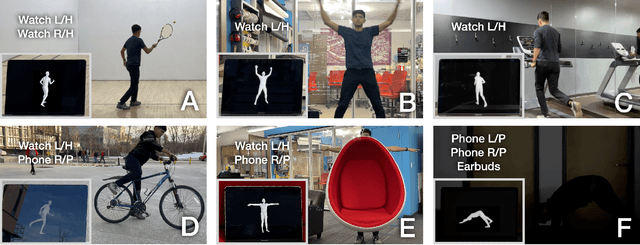
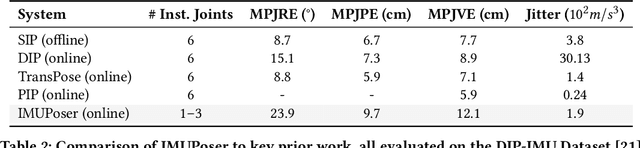
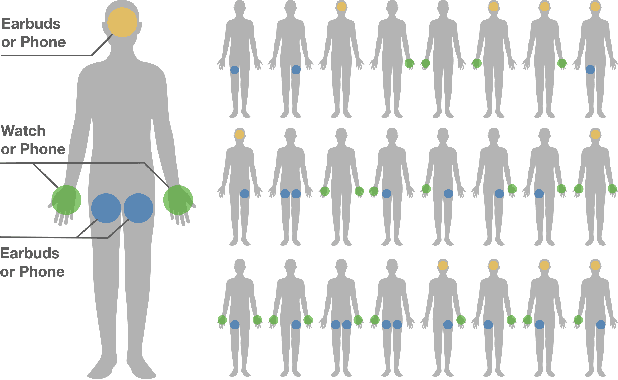
Tracking body pose on-the-go could have powerful uses in fitness, mobile gaming, context-aware virtual assistants, and rehabilitation. However, users are unlikely to buy and wear special suits or sensor arrays to achieve this end. Instead, in this work, we explore the feasibility of estimating body pose using IMUs already in devices that many users own -- namely smartphones, smartwatches, and earbuds. This approach has several challenges, including noisy data from low-cost commodity IMUs, and the fact that the number of instrumentation points on a users body is both sparse and in flux. Our pipeline receives whatever subset of IMU data is available, potentially from just a single device, and produces a best-guess pose. To evaluate our model, we created the IMUPoser Dataset, collected from 10 participants wearing or holding off-the-shelf consumer devices and across a variety of activity contexts. We provide a comprehensive evaluation of our system, benchmarking it on both our own and existing IMU datasets.
CatAlyst: Domain-Extensible Intervention for Preventing Task Procrastination Using Large Generative Models
Feb 11, 2023
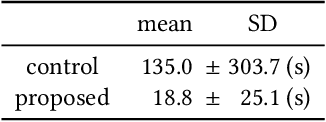

CatAlyst uses generative models to help workers' progress by influencing their task engagement instead of directly contributing to their task outputs. It prompts distracted workers to resume their tasks by generating a continuation of their work and presenting it as an intervention that is more context-aware than conventional (predetermined) feedback. The prompt can function by drawing their interest and lowering the hurdle for resumption even when the generated continuation is insufficient to substitute their work, while recent human-AI collaboration research aiming at work substitution depends on a stable high accuracy. This frees CatAlyst from domain-specific model-tuning and makes it applicable to various tasks. Our studies involving writing and slide-editing tasks demonstrated CatAlyst's effectiveness in helping workers swiftly resume tasks with a lowered cognitive load. The results suggest a new form of human-AI collaboration where large generative models publicly available but imperfect for each individual domain can contribute to workers' digital well-being.
Human-AI communication for human-human communication: Applying interpretable unsupervised anomaly detection to executive coaching
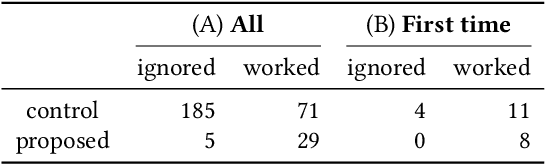
Jun 22, 2022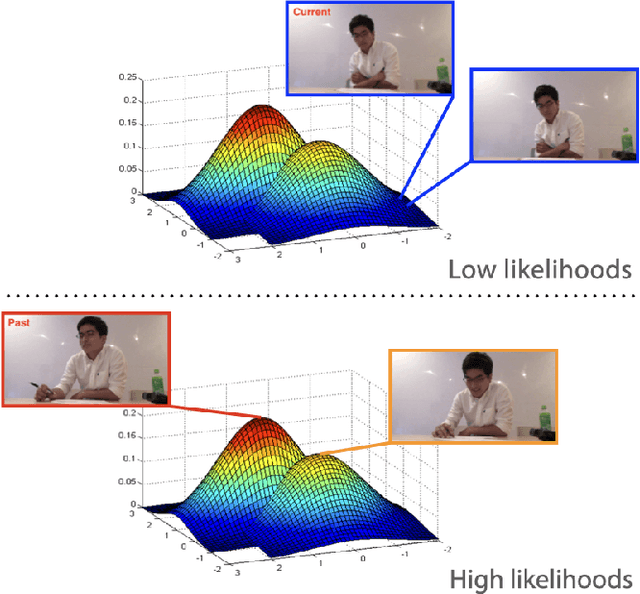


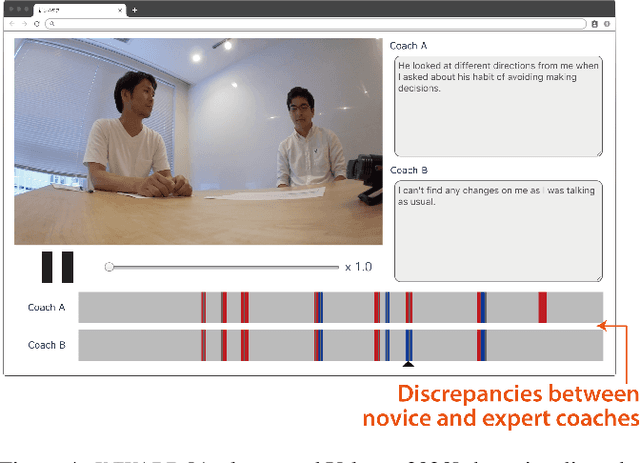
In this paper, we discuss the potential of applying unsupervised anomaly detection in constructing AI-based interactive systems that deal with highly contextual situations, i.e., human-human communication, in collaboration with domain experts. We reached this approach of utilizing unsupervised anomaly detection through our experience of developing a computational support tool for executive coaching, which taught us the importance of providing interpretable results so that expert coaches can take both the results and contexts into account. The key idea behind this approach is to leave room for expert coaches to unleash their open-ended interpretations, rather than simplifying the nature of social interactions to well-defined problems that are tractable by conventional supervised algorithms. In addition, we found that this approach can be extended to nurturing novice coaches; by prompting them to interpret the results from the system, it can provide the coaches with educational opportunities. Although the applicability of this approach should be validated in other domains, we believe that the idea of leveraging unsupervised anomaly detection to construct AI-based interactive systems would shed light on another direction of human-AI communication.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
AI for human assessment: What do professional assessors need?
Apr 18, 2022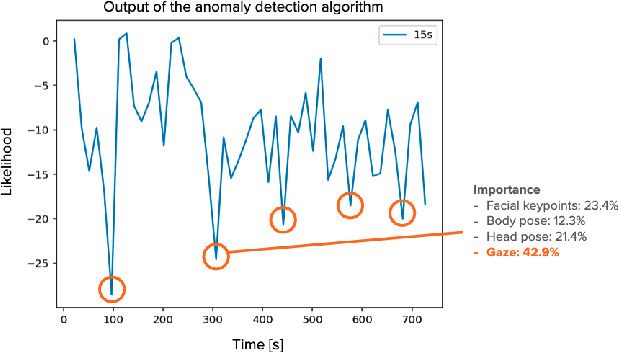
We present our case study that aims to help professional assessors make decisions in human assessment, in which they conduct interviews with assessees and evaluate their suitability for certain job roles. Our workshop with two industrial assessors revealed that a computational system that can extract nonverbal cues of assesses from interview videos would be beneficial to assessors in terms of supporting their decision making. In response, we developed such a system based on an unsupervised anomaly detection algorithm using multimodal behavioral features such as facial keypoints, pose, head pose, and gaze. Moreover, we enabled the system to output how much each feature contributed to the outlierness of the detected cues with the purpose of enhancing its interpretability. We then conducted a preliminary study to examine the validity of the system's output by using 20 actual assessment interview videos and involving the two assessors. The results suggested the advantages of using unsupervised anomaly detection in an interpretable manner by illustrating the informativeness of its outputs for assessors. Our approach, which builds on top of the idea of separation of observation and interpretation in human-AI teaming, will facilitate human decision making in highly contextual domains, such as human assessment, while keeping their trust in the system.
Semantic constraints to represent common sense required in household actions for multi-modal Learning-from-observation robot
Mar 03, 2021



The paradigm of learning-from-observation (LfO) enables a robot to learn how to perform actions by observing human-demonstrated actions. Previous research in LfO have mainly focused on the industrial domain which only consist of the observable physical constraints between a manipulating tool and the robot's working environment. In order to extend this paradigm to the household domain which consists non-observable constraints derived from a human's common sense; we introduce the idea of semantic constraints. The semantic constraints are represented similar to the physical constraints by defining a contact with an imaginary semantic environment. We thoroughly investigate the necessary and sufficient set of contact state and state transitions to understand the different types of physical and semantic constraints. We then apply our constraint representation to analyze various actions in top hit household YouTube videos and real home cooking recordings. We further categorize the frequently appearing constraint patterns into physical, semantic, and multistage task groups and verify that these groups are not only necessary but a sufficient set for covering standard household actions. Finally, we conduct a preliminary experiment using textual input to explore the possibilities of combining verbal and visual input for recognizing the task groups. Our results provide promising directions for incorporating common sense in the literature of robot teaching.