 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Rapid Test for Accuracy and Bias of Face Recognition Technology
Feb 20, 2025



Measuring the accuracy of face recognition (FR) systems is essential for improving performance and ensuring responsible use. Accuracy is typically estimated using large annotated datasets, which are costly and difficult to obtain. We propose a novel method for 1:1 face verification that benchmarks FR systems quickly and without manual annotation, starting from approximate labels (e.g., from web search results). Unlike previous methods for training set label cleaning, ours leverages the embedding representation of the models being evaluated, achieving high accuracy in smaller-sized test datasets. Our approach reliably estimates FR accuracy and ranking, significantly reducing the time and cost of manual labeling. We also introduce the first public benchmark of five FR cloud services, revealing demographic biases, particularly lower accuracy for Asian women. Our rapid test method can democratize FR testing, promoting scrutiny and responsible use of the technology. Our method is provided as a publicly accessible tool at https://github.com/caltechvisionlab/frt-rapid-test
Alien Recombination: Exploring Concept Blends Beyond Human Cognitive Availability in Visual Art
Nov 18, 2024
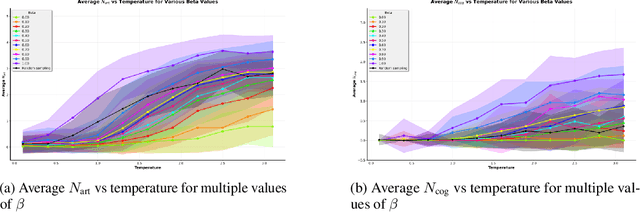
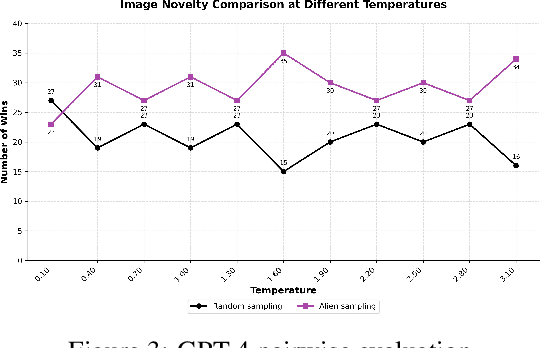
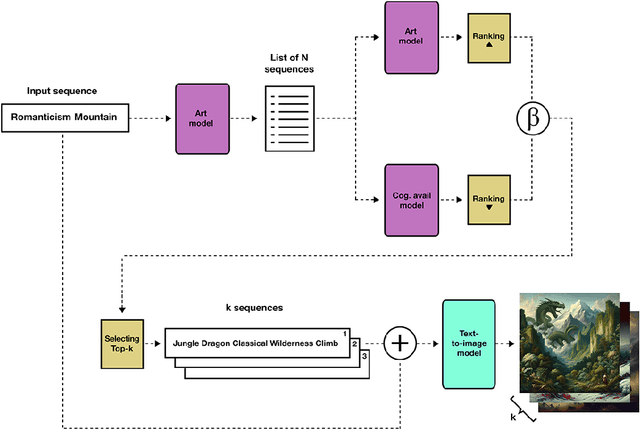
While AI models have demonstrated remarkable capabilities in constrained domains like game strategy, their potential for genuine creativity in open-ended domains like art remains debated. We explore this question by examining how AI can transcend human cognitive limitations in visual art creation. Our research hypothesizes that visual art contains a vast unexplored space of conceptual combinations, constrained not by inherent incompatibility, but by cognitive limitations imposed by artists' cultural, temporal, geographical and social contexts. To test this hypothesis, we present the Alien Recombination method, a novel approach utilizing fine-tuned large language models to identify and generate concept combinations that lie beyond human cognitive availability. The system models and deliberately counteracts human availability bias, the tendency to rely on immediately accessible examples, to discover novel artistic combinations. This system not only produces combinations that have never been attempted before within our dataset but also identifies and generates combinations that are cognitively unavailable to all artists in the domain. Furthermore, we translate these combinations into visual representations, enabling the exploration of subjective perceptions of novelty. Our findings suggest that cognitive unavailability is a promising metric for optimizing artistic novelty, outperforming merely temperature scaling without additional evaluation criteria. This approach uses generative models to connect previously unconnected ideas, providing new insight into the potential of framing AI-driven creativity as a combinatorial problem.
Empirical evidence of Large Language Model's influence on human spoken communication
Sep 03, 2024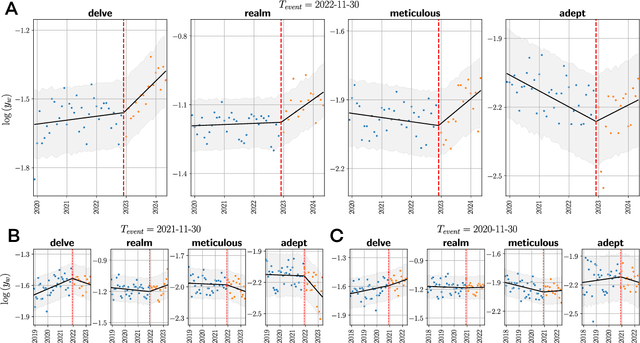
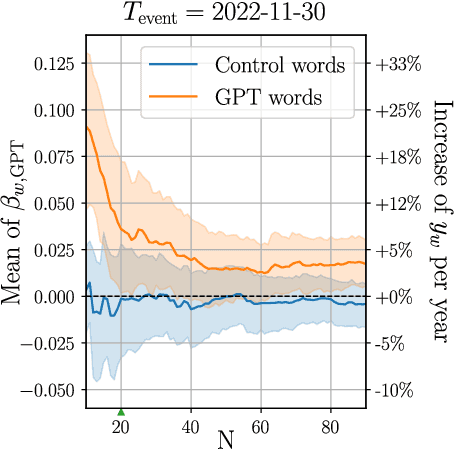
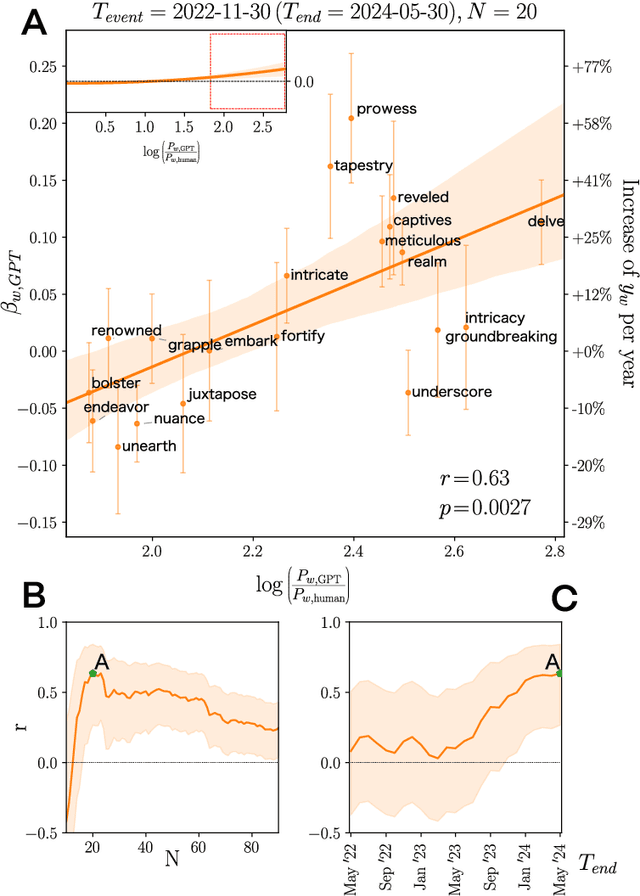

Artificial Intelligence (AI) agents now interact with billions of humans in natural language, thanks to advances in Large Language Models (LLMs) like ChatGPT. This raises the question of whether AI has the potential to shape a fundamental aspect of human culture: the way we speak. Recent analyses revealed that scientific publications already exhibit evidence of AI-specific language. But this evidence is inconclusive, since scientists may simply be using AI to copy-edit their writing. To explore whether AI has influenced human spoken communication, we transcribed and analyzed about 280,000 English-language videos of presentations, talks, and speeches from more than 20,000 YouTube channels of academic institutions. We find a significant shift in the trend of word usage specific to words distinctively associated with ChatGPT following its release. These findings provide the first empirical evidence that humans increasingly imitate LLMs in their spoken language. Our results raise societal and policy-relevant concerns about the potential of AI to unintentionally reduce linguistic diversity, or to be deliberately misused for mass manipulation. They also highlight the need for further investigation into the feedback loops between machine behavior and human culture.
Leveraging Large Language Models for Topic Classification in the Domain of Public Affairs
Jun 05, 2023The analysis of public affairs documents is crucial for citizens as it promotes transparency, accountability, and informed decision-making. It allows citizens to understand government policies, participate in public discourse, and hold representatives accountable. This is crucial, and sometimes a matter of life or death, for companies whose operation depend on certain regulations. Large Language Models (LLMs) have the potential to greatly enhance the analysis of public affairs documents by effectively processing and understanding the complex language used in such documents. In this work, we analyze the performance of LLMs in classifying public affairs documents. As a natural multi-label task, the classification of these documents presents important challenges. In this work, we use a regex-powered tool to collect a database of public affairs documents with more than 33K samples and 22.5M tokens. Our experiments assess the performance of 4 different Spanish LLMs to classify up to 30 different topics in the data in different configurations. The results shows that LLMs can be of great use to process domain-specific documents, such as those in the domain of public affairs.
Measuring Bias in AI Models with Application to Face Biometrics: An Statistical Approach
Apr 26, 2023

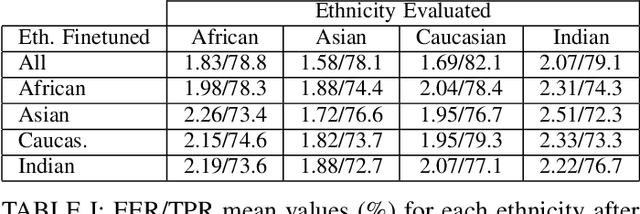
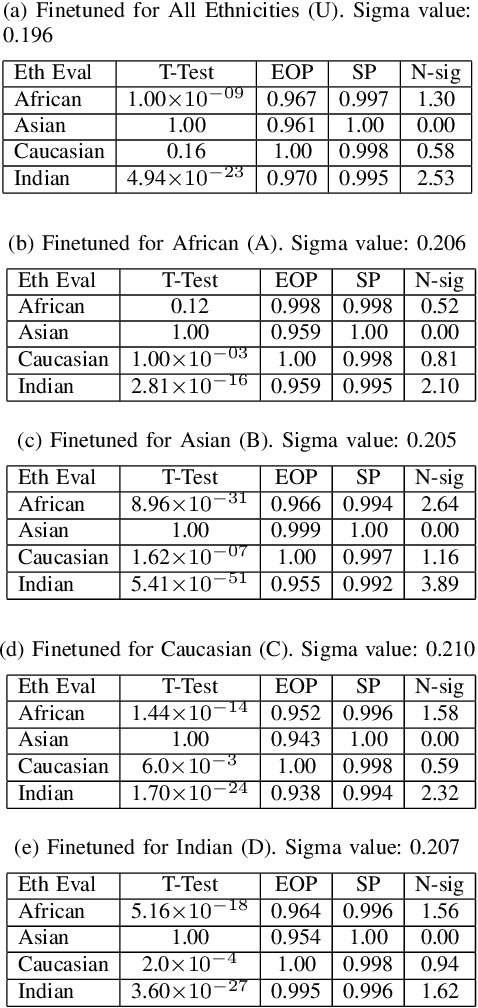
The new regulatory framework proposal on Artificial Intelligence (AI) published by the European Commission establishes a new risk-based legal approach. The proposal highlights the need to develop adequate risk assessments for the different uses of AI. This risk assessment should address, among others, the detection and mitigation of bias in AI. In this work we analyze statistical approaches to measure biases in automatic decision-making systems. We focus our experiments in face recognition technologies. We propose a novel way to measure the biases in machine learning models using a statistical approach based on the N-Sigma method. N-Sigma is a popular statistical approach used to validate hypotheses in general science such as physics and social areas and its application to machine learning is yet unexplored. In this work we study how to apply this methodology to develop new risk assessment frameworks based on bias analysis and we discuss the main advantages and drawbacks with respect to other popular statistical tests.
OTB-morph: One-Time Biometrics via Morphing
Feb 17, 2023Cancelable biometrics are a group of techniques to transform the input biometric to an irreversible feature intentionally using a transformation function and usually a key in order to provide security and privacy in biometric recognition systems. This transformation is repeatable enabling subsequent biometric comparisons. This paper is introducing a new idea to exploit as a transformation function for cancelable biometrics aimed at protecting the templates against iterative optimization attacks. Our proposed scheme is based on time-varying keys (random biometrics in our case) and morphing transformations. An experimental implementation of the proposed scheme is given for face biometrics. The results confirm that the proposed approach is able to withstand against leakage attacks while improving the recognition performance.
Human-Centric Multimodal Machine Learning: Recent Advances and Testbed on AI-based Recruitment
Feb 13, 2023The presence of decision-making algorithms in society is rapidly increasing nowadays, while concerns about their transparency and the possibility of these algorithms becoming new sources of discrimination are arising. There is a certain consensus about the need to develop AI applications with a Human-Centric approach. Human-Centric Machine Learning needs to be developed based on four main requirements: (i) utility and social good; (ii) privacy and data ownership; (iii) transparency and accountability; and (iv) fairness in AI-driven decision-making processes. All these four Human-Centric requirements are closely related to each other. With the aim of studying how current multimodal algorithms based on heterogeneous sources of information are affected by sensitive elements and inner biases in the data, we propose a fictitious case study focused on automated recruitment: FairCVtest. We train automatic recruitment algorithms using a set of multimodal synthetic profiles including image, text, and structured data, which are consciously scored with gender and racial biases. FairCVtest shows the capacity of the Artificial Intelligence (AI) behind automatic recruitment tools built this way (a common practice in many other application scenarios beyond recruitment) to extract sensitive information from unstructured data and exploit it in combination to data biases in undesirable (unfair) ways. We present an overview of recent works developing techniques capable of removing sensitive information and biases from the decision-making process of deep learning architectures, as well as commonly used databases for fairness research in AI. We demonstrate how learning approaches developed to guarantee privacy in latent spaces can lead to unbiased and fair automatic decision-making process.
FaceQgen: Semi-Supervised Deep Learning for Face Image Quality Assessment
Jan 03, 2022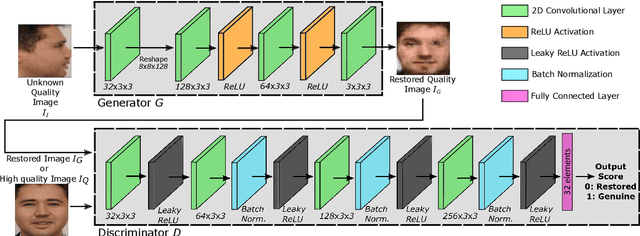
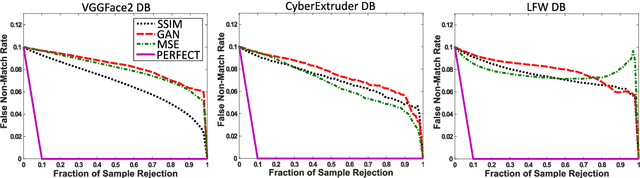
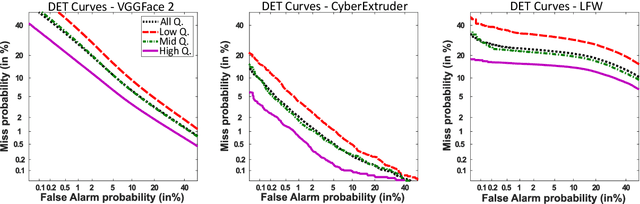
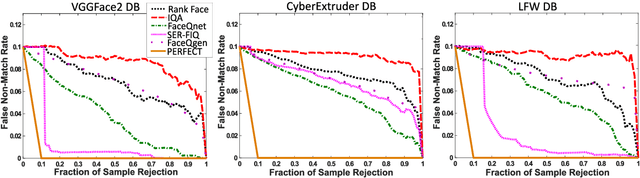
In this paper we develop FaceQgen, a No-Reference Quality Assessment approach for face images based on a Generative Adversarial Network that generates a scalar quality measure related with the face recognition accuracy. FaceQgen does not require labelled quality measures for training. It is trained from scratch using the SCface database. FaceQgen applies image restoration to a face image of unknown quality, transforming it into a canonical high quality image, i.e., frontal pose, homogeneous background, etc. The quality estimation is built as the similarity between the original and the restored images, since low quality images experience bigger changes due to restoration. We compare three different numerical quality measures: a) the MSE between the original and the restored images, b) their SSIM, and c) the output score of the Discriminator of the GAN. The results demonstrate that FaceQgen's quality measures are good estimators of face recognition accuracy. Our experiments include a comparison with other quality assessment methods designed for faces and for general images, in order to position FaceQgen in the state of the art. This comparison shows that, even though FaceQgen does not surpass the best existing face quality assessment methods in terms of face recognition accuracy prediction, it achieves good enough results to demonstrate the potential of semi-supervised learning approaches for quality estimation (in particular, data-driven learning based on a single high quality image per subject), having the capacity to improve its performance in the future with adequate refinement of the model and the significant advantage over competing methods of not needing quality labels for its development. This makes FaceQgen flexible and scalable without expensive data curation.
OTB-morph: One-Time Biometrics via Morphing applied to Face Templates
Nov 25, 2021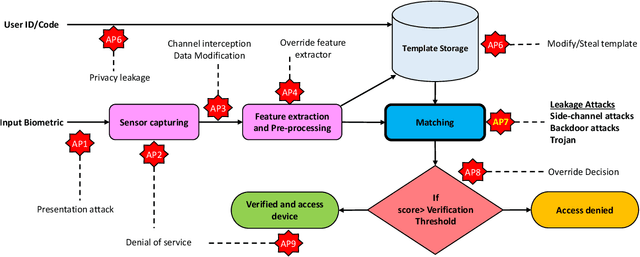

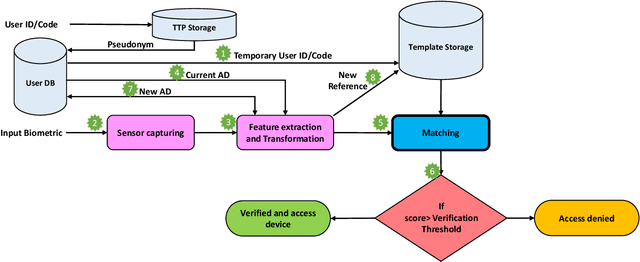
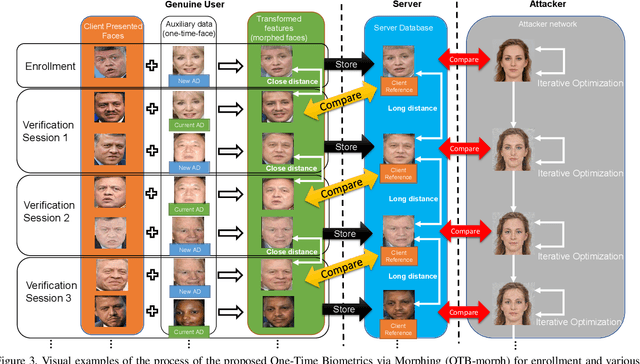
Cancelable biometrics refers to a group of techniques in which the biometric inputs are transformed intentionally using a key before processing or storage. This transformation is repeatable enabling subsequent biometric comparisons. This paper introduces a new scheme for cancelable biometrics aimed at protecting the templates against potential attacks, applicable to any biometric-based recognition system. Our proposed scheme is based on time-varying keys obtained from morphing random biometric information. An experimental implementation of the proposed scheme is given for face biometrics. The results confirm that the proposed approach is able to withstand against leakage attacks while improving the recognition performance.
IFBiD: Inference-Free Bias Detection
Sep 10, 2021



This paper is the first to explore an automatic way to detect bias in deep convolutional neural networks by simply looking at their weights. Furthermore, it is also a step towards understanding neural networks and how they work. We show that it is indeed possible to know if a model is biased or not simply by looking at its weights, without the model inference for an specific input. We analyze how bias is encoded in the weights of deep networks through a toy example using the Colored MNIST database and we also provide a realistic case study in gender detection from face images using state-of-the-art methods and experimental resources. To do so, we generated two databases with 36K and 48K biased models each. In the MNIST models we were able to detect whether they presented a strong or low bias with more than 99% accuracy, and we were also able to classify between four levels of bias with more than 70% accuracy. For the face models, we achieved 90% accuracy in distinguishing between models biased towards Asian, Black, or Caucasian ethnicity.