 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Bias in LLMs: Strategies and Application to Fair AI-based Recruitment
Jun 13, 2025The use of language technologies in high-stake settings is increasing in recent years, mostly motivated by the success of Large Language Models (LLMs). However, despite the great performance of LLMs, they are are susceptible to ethical concerns, such as demographic biases, accountability, or privacy. This work seeks to analyze the capacity of Transformers-based systems to learn demographic biases present in the data, using a case study on AI-based automated recruitment. We propose a privacy-enhancing framework to reduce gender information from the learning pipeline as a way to mitigate biased behaviors in the final tools. Our experiments analyze the influence of data biases on systems built on two different LLMs, and how the proposed framework effectively prevents trained systems from reproducing the bias in the data.
Balancing Tails when Comparing Distributions: Comprehensive Equity Index (CEI) with Application to Bias Evaluation in Operational Face Biometrics
Jun 12, 2025Demographic bias in high-performance face recognition (FR) systems often eludes detection by existing metrics, especially with respect to subtle disparities in the tails of the score distribution. We introduce the Comprehensive Equity Index (CEI), a novel metric designed to address this limitation. CEI uniquely analyzes genuine and impostor score distributions separately, enabling a configurable focus on tail probabilities while also considering overall distribution shapes. Our extensive experiments (evaluating state-of-the-art FR systems, intentionally biased models, and diverse datasets) confirm CEI's superior ability to detect nuanced biases where previous methods fall short. Furthermore, we present CEI^A, an automated version of the metric that enhances objectivity and simplifies practical application. CEI provides a robust and sensitive tool for operational FR fairness assessment. The proposed methods have been developed particularly for bias evaluation in face biometrics but, in general, they are applicable for comparing statistical distributions in any problem where one is interested in analyzing the distribution tails.
Comprehensive Equity Index (CEI): Definition and Application to Bias Evaluation in Biometrics
Sep 03, 2024


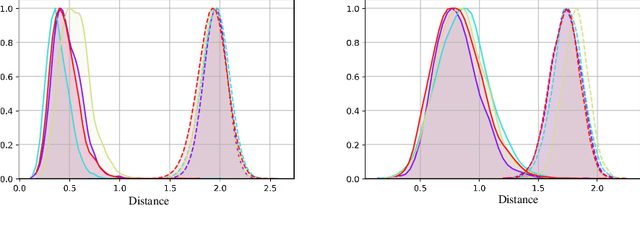
We present a novel metric designed, among other applications, to quantify biased behaviors of machine learning models. As its core, the metric consists of a new similarity metric between score distributions that balances both their general shapes and tails' probabilities. In that sense, our proposed metric may be useful in many application areas. Here we focus on and apply it to the operational evaluation of face recognition systems, with special attention to quantifying demographic biases; an application where our metric is especially useful. The topic of demographic bias and fairness in biometric recognition systems has gained major attention in recent years. The usage of these systems has spread in society, raising concerns about the extent to which these systems treat different population groups. A relevant step to prevent and mitigate demographic biases is first to detect and quantify them. Traditionally, two approaches have been studied to quantify differences between population groups in machine learning literature: 1) measuring differences in error rates, and 2) measuring differences in recognition score distributions. Our proposed Comprehensive Equity Index (CEI) trade-offs both approaches combining both errors from distribution tails and general distribution shapes. This new metric is well suited to real-world scenarios, as measured on NIST FRVT evaluations, involving high-performance systems and realistic face databases including a wide range of covariates and demographic groups. We first show the limitations of existing metrics to correctly assess the presence of biases in realistic setups and then propose our new metric to tackle these limitations. We tested the proposed metric with two state-of-the-art models and four widely used databases, showing its capacity to overcome the main flaws of previous bias metrics.
Document Layout Annotation: Database and Benchmark in the Domain of Public Affairs
Jun 12, 2023Every day, thousands of digital documents are generated with useful information for companies, public organizations, and citizens. Given the impossibility of processing them manually, the automatic processing of these documents is becoming increasingly necessary in certain sectors. However, this task remains challenging, since in most cases a text-only based parsing is not enough to fully understand the information presented through different components of varying significance. In this regard, Document Layout Analysis (DLA) has been an interesting research field for many years, which aims to detect and classify the basic components of a document. In this work, we used a procedure to semi-automatically annotate digital documents with different layout labels, including 4 basic layout blocks and 4 text categories. We apply this procedure to collect a novel database for DLA in the public affairs domain, using a set of 24 data sources from the Spanish Administration. The database comprises 37.9K documents with more than 441K document pages, and more than 8M labels associated to 8 layout block units. The results of our experiments validate the proposed text labeling procedure with accuracy up to 99%.
Leveraging Large Language Models for Topic Classification in the Domain of Public Affairs
Jun 05, 2023The analysis of public affairs documents is crucial for citizens as it promotes transparency, accountability, and informed decision-making. It allows citizens to understand government policies, participate in public discourse, and hold representatives accountable. This is crucial, and sometimes a matter of life or death, for companies whose operation depend on certain regulations. Large Language Models (LLMs) have the potential to greatly enhance the analysis of public affairs documents by effectively processing and understanding the complex language used in such documents. In this work, we analyze the performance of LLMs in classifying public affairs documents. As a natural multi-label task, the classification of these documents presents important challenges. In this work, we use a regex-powered tool to collect a database of public affairs documents with more than 33K samples and 22.5M tokens. Our experiments assess the performance of 4 different Spanish LLMs to classify up to 30 different topics in the data in different configurations. The results shows that LLMs can be of great use to process domain-specific documents, such as those in the domain of public affairs.
Human-Centric Multimodal Machine Learning: Recent Advances and Testbed on AI-based Recruitment
Feb 13, 2023The presence of decision-making algorithms in society is rapidly increasing nowadays, while concerns about their transparency and the possibility of these algorithms becoming new sources of discrimination are arising. There is a certain consensus about the need to develop AI applications with a Human-Centric approach. Human-Centric Machine Learning needs to be developed based on four main requirements: (i) utility and social good; (ii) privacy and data ownership; (iii) transparency and accountability; and (iv) fairness in AI-driven decision-making processes. All these four Human-Centric requirements are closely related to each other. With the aim of studying how current multimodal algorithms based on heterogeneous sources of information are affected by sensitive elements and inner biases in the data, we propose a fictitious case study focused on automated recruitment: FairCVtest. We train automatic recruitment algorithms using a set of multimodal synthetic profiles including image, text, and structured data, which are consciously scored with gender and racial biases. FairCVtest shows the capacity of the Artificial Intelligence (AI) behind automatic recruitment tools built this way (a common practice in many other application scenarios beyond recruitment) to extract sensitive information from unstructured data and exploit it in combination to data biases in undesirable (unfair) ways. We present an overview of recent works developing techniques capable of removing sensitive information and biases from the decision-making process of deep learning architectures, as well as commonly used databases for fairness research in AI. We demonstrate how learning approaches developed to guarantee privacy in latent spaces can lead to unbiased and fair automatic decision-making process.
Facial Expressions as a Vulnerability in Face Recognition
Nov 17, 2020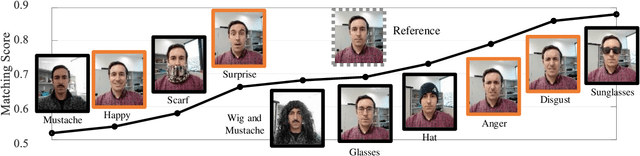



This work explores facial expression bias as a security vulnerability of face recognition systems. Face recognition technology has experienced great advances during the last decades. However, despite the great performance achieved by state of the art face recognition systems, the algorithms are still sensitive to a large range of covariates. This work presents a comprehensive analysis of how facial expression bias impacts the performance of face recognition technologies. Our study analyzes: i) facial expression biases in the most popular face recognition databases; and ii) the impact of facial expression in face recognition performances. Our experimental framework includes four face detectors, three face recognition models, and four different databases. Our results demonstrate a huge facial expression bias in the most widely used databases, as well as a related impact of face expression in the performance of state-of-the-art algorithms. This work opens the door to new research lines focused on mitigating the observed vulnerability.
Learning Emotional-Blinded Face Representations
Sep 18, 2020



We propose two face representations that are blind to facial expressions associated to emotional responses. This work is in part motivated by new international regulations for personal data protection, which enforce data controllers to protect any kind of sensitive information involved in automatic processes. The advances in Affective Computing have contributed to improve human-machine interfaces but, at the same time, the capacity to monitorize emotional responses triggers potential risks for humans, both in terms of fairness and privacy. We propose two different methods to learn these expression-blinded facial features. We show that it is possible to eliminate information related to emotion recognition tasks, while the performance of subject verification, gender recognition, and ethnicity classification are just slightly affected. We also present an application to train fairer classifiers in a case study of attractiveness classification with respect to a protected facial expression attribute. The results demonstrate that it is possible to reduce emotional information in the face representation while retaining competitive performance in other face-based artificial intelligence tasks.
FairCVtest Demo: Understanding Bias in Multimodal Learning with a Testbed in Fair Automatic Recruitment
Sep 12, 2020
With the aim of studying how current multimodal AI algorithms based on heterogeneous sources of information are affected by sensitive elements and inner biases in the data, this demonstrator experiments over an automated recruitment testbed based on Curriculum Vitae: FairCVtest. The presence of decision-making algorithms in society is rapidly increasing nowadays, while concerns about their transparency and the possibility of these algorithms becoming new sources of discrimination are arising. This demo shows the capacity of the Artificial Intelligence (AI) behind a recruitment tool to extract sensitive information from unstructured data, and exploit it in combination to data biases in undesirable (unfair) ways. Aditionally, the demo includes a new algorithm (SensitiveNets) for discrimination-aware learning which eliminates sensitive information in our multimodal AI framework.
InsideBias: Measuring Bias in Deep Networks and Application to Face Gender Biometrics
Apr 15, 2020



This work explores the biases in learning processes based on deep neural network architectures through a case study in gender detection from face images. We employ two gender detection models based on popular deep neural networks. We present a comprehensive analysis of bias effects when using an unbalanced training dataset on the features learned by the models. We show how ethnic attributes impact in the activations of gender detection models based on face images. We finally propose InsideBias, a novel method to detect biased models. InsideBias is based on how the models represent the information instead of how they perform, which is the normal practice in other existing methods for bias detection. Our strategy with InsideBias allows to detect biased models with very few samples (only 15 images in our case study). Our experiments include 72K face images from 24K identities and 3 ethnic groups.