 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriver2vec: Driver Identification from Automotive Data
Feb 10, 2021
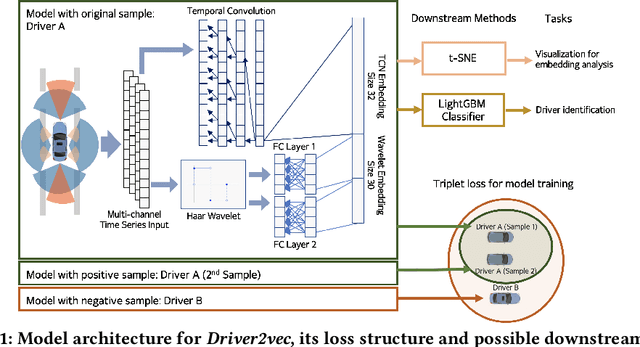
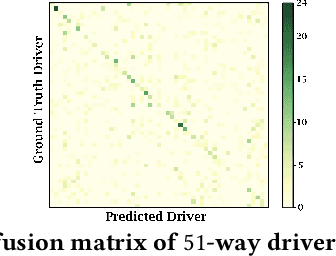

With increasing focus on privacy protection, alternative methods to identify vehicle operator without the use of biometric identifiers have gained traction for automotive data analysis. The wide variety of sensors installed on modern vehicles enable autonomous driving, reduce accidents and improve vehicle handling. On the other hand, the data these sensors collect reflect drivers' habit. Drivers' use of turn indicators, following distance, rate of acceleration, etc. can be transformed to an embedding that is representative of their behavior and identity. In this paper, we develop a deep learning architecture (Driver2vec) to map a short interval of driving data into an embedding space that represents the driver's behavior to assist in driver identification. We develop a custom model that leverages performance gains of temporal convolutional networks, embedding separation power of triplet loss and classification accuracy of gradient boosting decision trees. Trained on a dataset of 51 drivers provided by Nervtech, Driver2vec is able to accurately identify the driver from a short 10-second interval of sensor data, achieving an average pairwise driver identification accuracy of 83.1% from this 10-second interval, which is remarkably higher than performance obtained in previous studies. We then analyzed performance of Driver2vec to show that its performance is consistent across scenarios and that modeling choices are sound.
CASC: Context-Aware Segmentation and Clustering for Motif Discovery in Noisy Time Series Data
Sep 06, 2018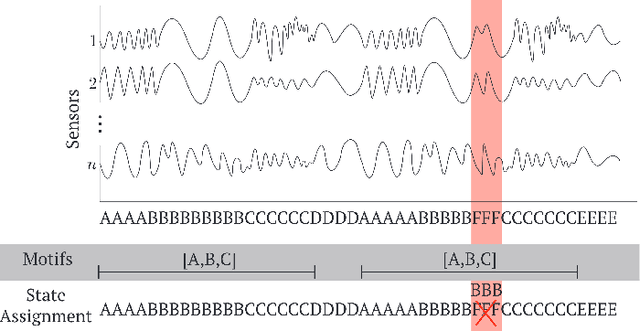
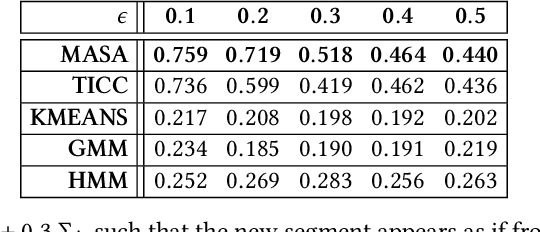
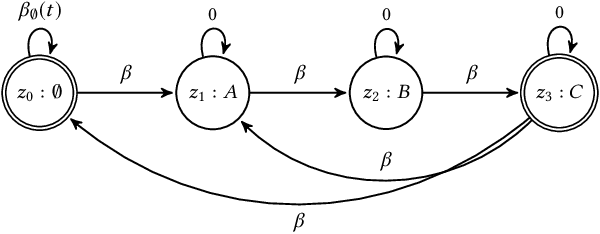
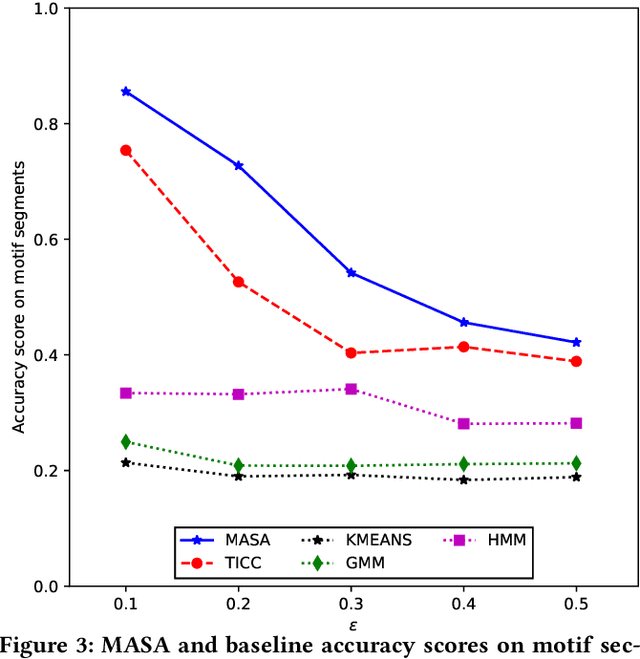
Complex systems, such as airplanes, cars, or financial markets, produce multivariate time series data consisting of system observations over a period of time. Such data can be interpreted as a sequence of segments, where each segment is associated with a certain state of the system. An important problem in this domain is to identify repeated sequences of states, known as motifs. Such motifs correspond to complex behaviors that capture common sequences of state transitions. For example, a motif of "making a turn" might manifest in sensor data as a sequence of states: slowing down, turning the wheel, and then speeding back up. However, discovering these motifs is challenging, because the individual states are unknown and need to be learned from the noisy time series. Simultaneously, the time series also needs to be precisely segmented and each segment needs to be associated with a state. Here we develop context-aware segmentation and clustering (CASC), a method for discovering common motifs in time series data. We formulate the problem of motif discovery as a large optimization problem, which we then solve using a greedy alternating minimization-based approach. CASC performs well in the presence of noise in the input data and is scalable to very large datasets. Furthermore, CASC leverages common motifs to more robustly segment the time series and assign segments to states. Experiments on synthetic data show that CASC outperforms state-of-the-art baselines by up to 38.2%, and two case studies demonstrate how our approach discovers insightful motifs in real-world time series data.
Learning Structural Node Embeddings Via Diffusion Wavelets
Jun 20, 2018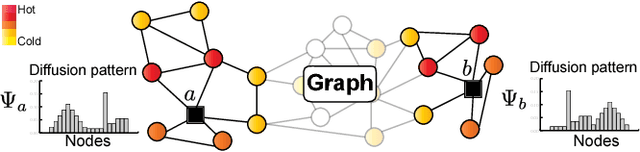
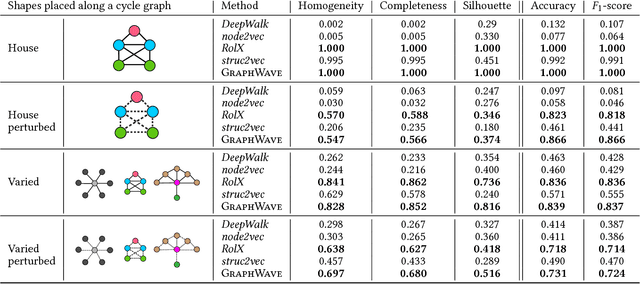

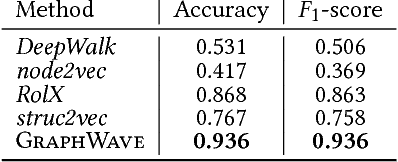
Nodes residing in different parts of a graph can have similar structural roles within their local network topology. The identification of such roles provides key insight into the organization of networks and can be used for a variety of machine learning tasks. However, learning structural representations of nodes is a challenging problem, and it has typically involved manually specifying and tailoring topological features for each node. In this paper, we develop GraphWave, a method that represents each node's network neighborhood via a low-dimensional embedding by leveraging heat wavelet diffusion patterns. Instead of training on hand-selected features, GraphWave learns these embeddings in an unsupervised way. We mathematically prove that nodes with similar network neighborhoods will have similar GraphWave embeddings even though these nodes may reside in very different parts of the network, and our method scales linearly with the number of edges. Experiments in a variety of different settings demonstrate GraphWave's real-world potential for capturing structural roles in networks, and our approach outperforms existing state-of-the-art baselines in every experiment, by as much as 137%.
Drive2Vec: Multiscale State-Space Embedding of Vehicular Sensor Data
Jun 12, 2018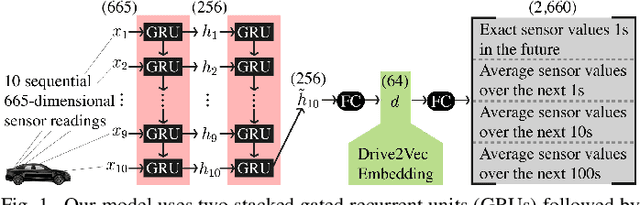
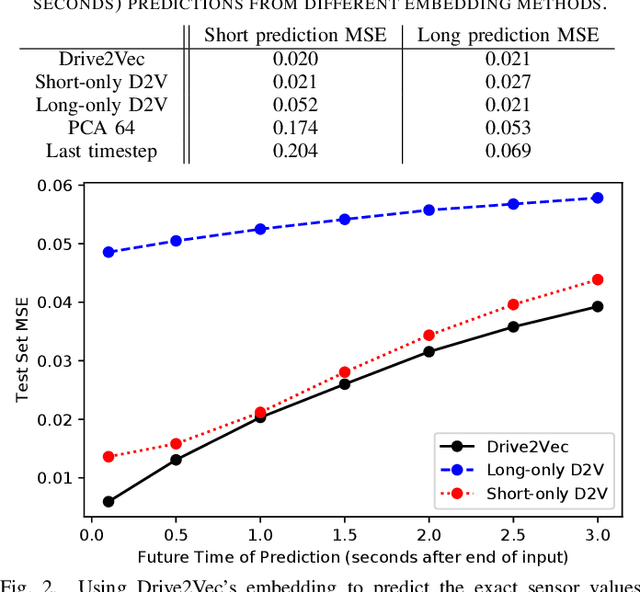
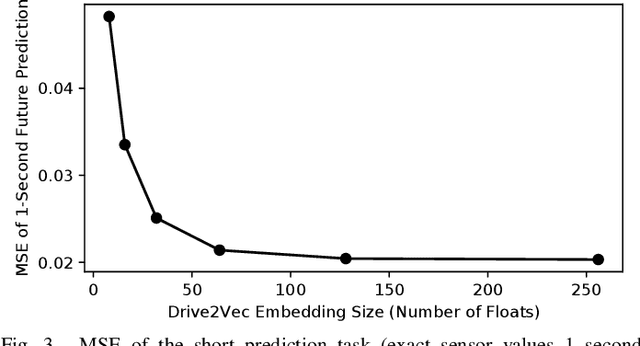

With automobiles becoming increasingly reliant on sensors to perform various driving tasks, it is important to encode the relevant CAN bus sensor data in a way that captures the general state of the vehicle in a compact form. In this paper, we develop a deep learning-based method, called Drive2Vec, for embedding such sensor data in a low-dimensional yet actionable form. Our method is based on stacked gated recurrent units (GRUs). It accepts a short interval of automobile sensor data as input and computes a low-dimensional representation of that data, which can then be used to accurately solve a range of tasks. With this representation, we (1) predict the exact values of the sensors in the short term (up to three seconds in the future), (2) forecast the long-term average values of these same sensors, (3) infer additional contextual information that is not encoded in the data, including the identity of the driver behind the wheel, and (4) build a knowledge base that can be used to auto-label data and identify risky states. We evaluate our approach on a dataset collected by Audi, which equipped a fleet of test vehicles with data loggers to store all sensor readings on 2,098 hours of driving on real roads. We show in several experiments that our method outperforms other baselines by up to 90%, and we further demonstrate how these embeddings of sensor data can be used to solve a variety of real-world automotive applications.
Toeplitz Inverse Covariance-Based Clustering of Multivariate Time Series Data
May 15, 2018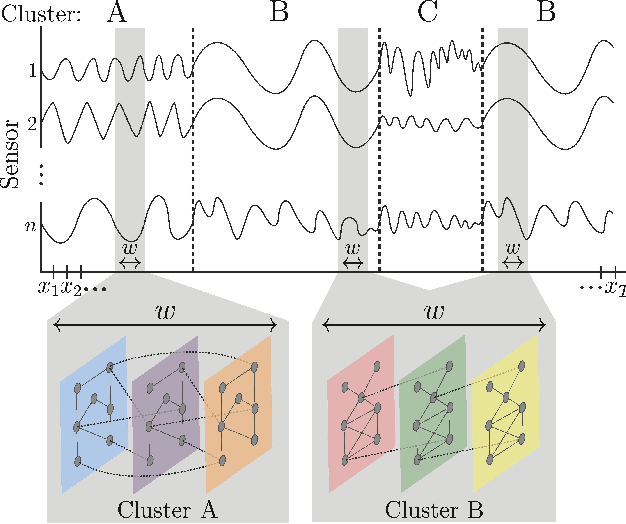
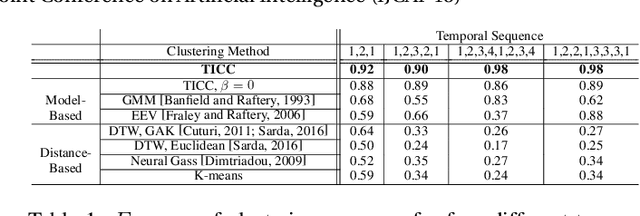
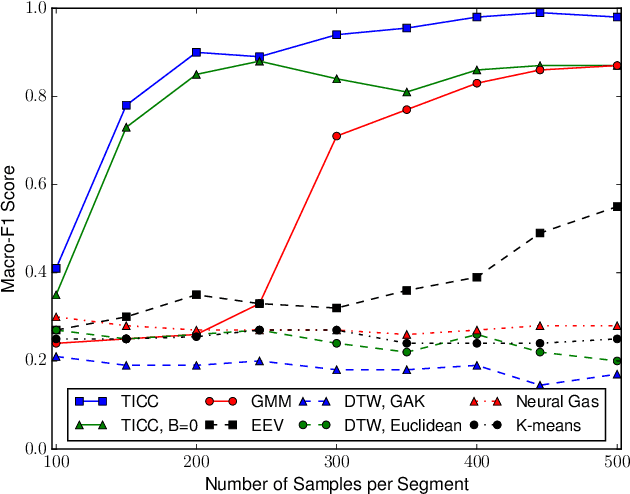
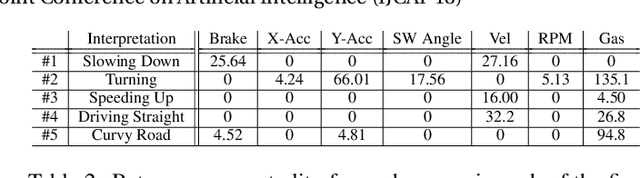
Subsequence clustering of multivariate time series is a useful tool for discovering repeated patterns in temporal data. Once these patterns have been discovered, seemingly complicated datasets can be interpreted as a temporal sequence of only a small number of states, or clusters. For example, raw sensor data from a fitness-tracking application can be expressed as a timeline of a select few actions (i.e., walking, sitting, running). However, discovering these patterns is challenging because it requires simultaneous segmentation and clustering of the time series. Furthermore, interpreting the resulting clusters is difficult, especially when the data is high-dimensional. Here we propose a new method of model-based clustering, which we call Toeplitz Inverse Covariance-based Clustering (TICC). Each cluster in the TICC method is defined by a correlation network, or Markov random field (MRF), characterizing the interdependencies between different observations in a typical subsequence of that cluster. Based on this graphical representation, TICC simultaneously segments and clusters the time series data. We solve the TICC problem through alternating minimization, using a variation of the expectation maximization (EM) algorithm. We derive closed-form solutions to efficiently solve the two resulting subproblems in a scalable way, through dynamic programming and the alternating direction method of multipliers (ADMM), respectively. We validate our approach by comparing TICC to several state-of-the-art baselines in a series of synthetic experiments, and we then demonstrate on an automobile sensor dataset how TICC can be used to learn interpretable clusters in real-world scenarios.
Data-Driven Model Predictive Control of Autonomous Mobility-on-Demand Systems
Sep 20, 2017
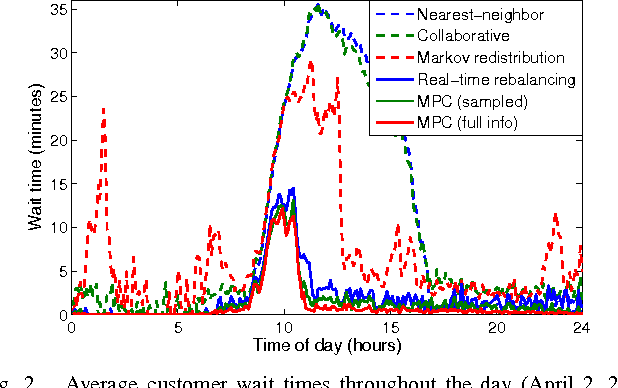
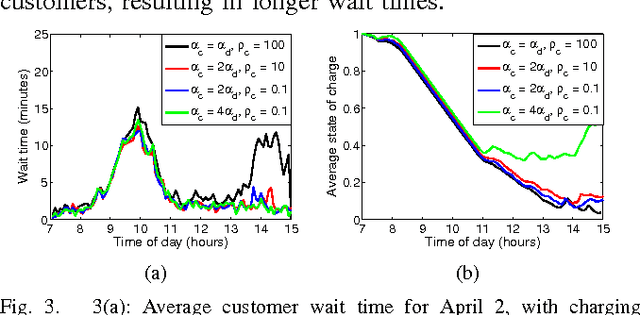
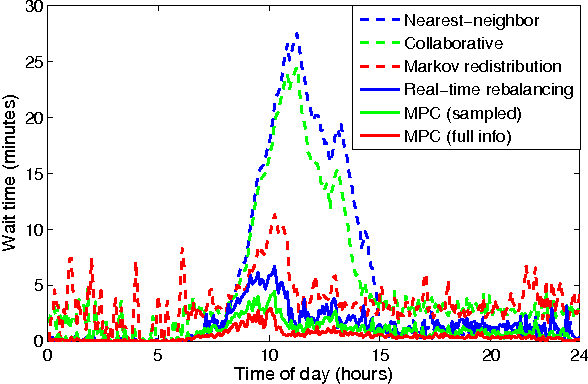
The goal of this paper is to present an end-to-end, data-driven framework to control Autonomous Mobility-on-Demand systems (AMoD, i.e. fleets of self-driving vehicles). We first model the AMoD system using a time-expanded network, and present a formulation that computes the optimal rebalancing strategy (i.e., preemptive repositioning) and the minimum feasible fleet size for a given travel demand. Then, we adapt this formulation to devise a Model Predictive Control (MPC) algorithm that leverages short-term demand forecasts based on historical data to compute rebalancing strategies. We test the end-to-end performance of this controller with a state-of-the-art LSTM neural network to predict customer demand and real customer data from DiDi Chuxing: we show that this approach scales very well for large systems (indeed, the computational complexity of the MPC algorithm does not depend on the number of customers and of vehicles in the system) and outperforms state-of-the-art rebalancing strategies by reducing the mean customer wait time by up to to 89.6%.
Network Inference via the Time-Varying Graphical Lasso
Jun 10, 2017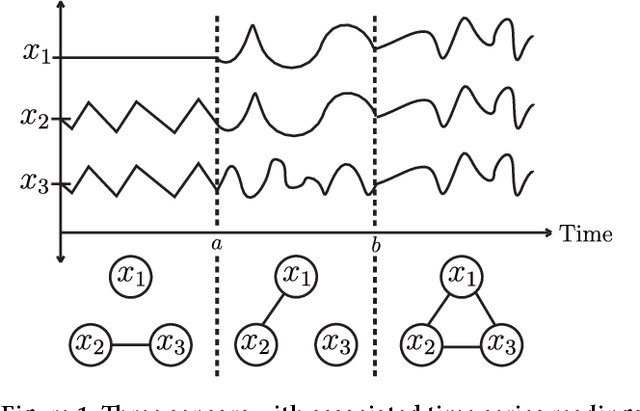
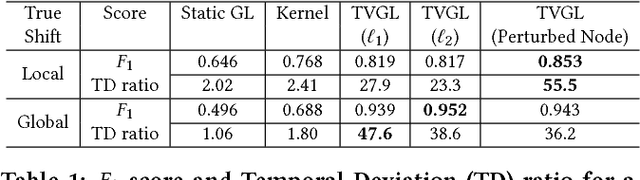
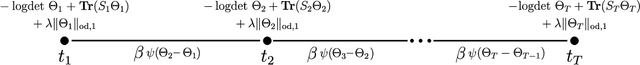
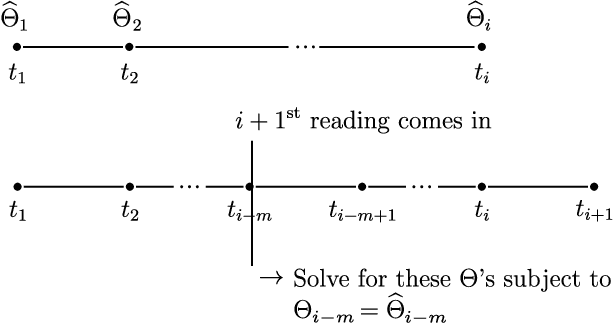
Many important problems can be modeled as a system of interconnected entities, where each entity is recording time-dependent observations or measurements. In order to spot trends, detect anomalies, and interpret the temporal dynamics of such data, it is essential to understand the relationships between the different entities and how these relationships evolve over time. In this paper, we introduce the time-varying graphical lasso (TVGL), a method of inferring time-varying networks from raw time series data. We cast the problem in terms of estimating a sparse time-varying inverse covariance matrix, which reveals a dynamic network of interdependencies between the entities. Since dynamic network inference is a computationally expensive task, we derive a scalable message-passing algorithm based on the Alternating Direction Method of Multipliers (ADMM) to solve this problem in an efficient way. We also discuss several extensions, including a streaming algorithm to update the model and incorporate new observations in real time. Finally, we evaluate our TVGL algorithm on both real and synthetic datasets, obtaining interpretable results and outperforming state-of-the-art baselines in terms of both accuracy and scalability.
Driver Identification Using Automobile Sensor Data from a Single Turn
Jun 09, 2017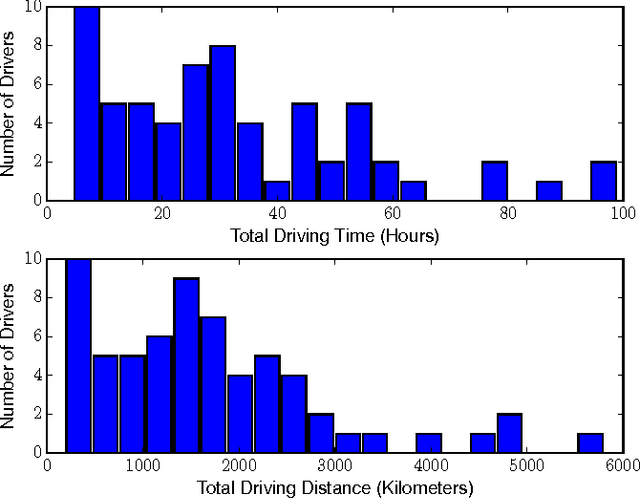

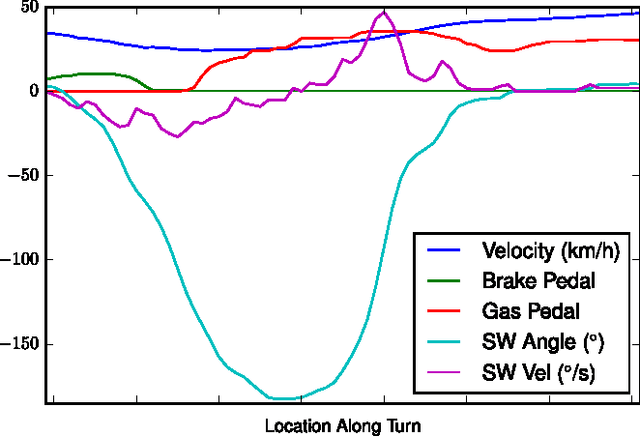

As automotive electronics continue to advance, cars are becoming more and more reliant on sensors to perform everyday driving operations. These sensors are omnipresent and help the car navigate, reduce accidents, and provide comfortable rides. However, they can also be used to learn about the drivers themselves. In this paper, we propose a method to predict, from sensor data collected at a single turn, the identity of a driver out of a given set of individuals. We cast the problem in terms of time series classification, where our dataset contains sensor readings at one turn, repeated several times by multiple drivers. We build a classifier to find unique patterns in each individual's driving style, which are visible in the data even on such a short road segment. To test our approach, we analyze a new dataset collected by AUDI AG and Audi Electronics Venture, where a fleet of test vehicles was equipped with automotive data loggers storing all sensor readings on real roads. We show that turns are particularly well-suited for detecting variations across drivers, especially when compared to straightaways. We then focus on the 12 most frequently made turns in the dataset, which include rural, urban, highway on-ramps, and more, obtaining accurate identification results and learning useful insights about driver behavior in a variety of settings.