 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAres: Adaptive Reasoning Effort Selection for Efficient LLM Agents
Mar 09, 2026Modern agents powered by thinking LLMs achieve high accuracy through long chain-of-thought reasoning but incur substantial inference costs. While many LLMs now support configurable reasoning levels (e.g., high/medium/low), static strategies are often ineffective: using low-effort modes at every step leads to significant performance degradation, while random selection fails to preserve accuracy or provide meaningful cost reduction. However, agents should reserve high reasoning effort for difficult steps like navigating complex website structures, while using lower-effort modes for simpler steps like opening a target URL. In this paper, we propose Ares, a framework for per-step dynamic reasoning effort selection tailored for multi-step agent tasks. Ares employs a lightweight router to predict the lowest appropriate reasoning level for each step based on the interaction history. To train this router, we develop a data generation pipeline that identifies the minimum reasoning effort required for successful step completion. We then fine-tune the router to predict these levels, enabling plug-and-play integration for any LLM agents. We evaluate Ares on a diverse set of agent tasks, including TAU-Bench for tool use agents, BrowseComp-Plus for deep-research agents, and WebArena for web agents. Experimental results show that Ares reduces reasoning token usage by up to 52.7% compared to fixed high-effort reasoning, while introducing minimal degradation in task success rates.
Inference-based GAN Video Generation
Dec 25, 2025



Video generation has seen remarkable progresses thanks to advancements in generative deep learning. Generated videos should not only display coherent and continuous movement but also meaningful movement in successions of scenes. Generating models such as Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs) and more recently Diffusion Networks have been used for generating short video sequences, usually of up to 16 frames. In this paper, we first propose a new type of video generator by enabling adversarial-based unconditional video generators with a variational encoder, akin to a VAE-GAN hybrid structure, in order to enable the generation process with inference capabilities. The proposed model, as in other video deep learning-based processing frameworks, incorporates two processing branches, one for content and another for movement. However, existing models struggle with the temporal scaling of the generated videos. In classical approaches when aiming to increase the generated video length, the resulting video quality degrades, particularly when considering generating significantly long sequences. To overcome this limitation, our research study extends the initially proposed VAE-GAN video generation model by employing a novel, memory-efficient approach to generate long videos composed of hundreds or thousands of frames ensuring their temporal continuity, consistency and dynamics. Our approach leverages a Markov chain framework with a recall mechanism, with each state representing a VAE-GAN short-length video generator. This setup allows for the sequential connection of generated video sub-sequences, enabling temporal dependencies, resulting in meaningful long video sequences.
Self-Resource Allocation in Multi-Agent LLM Systems
Apr 02, 2025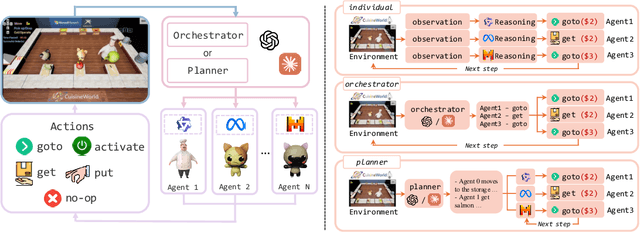
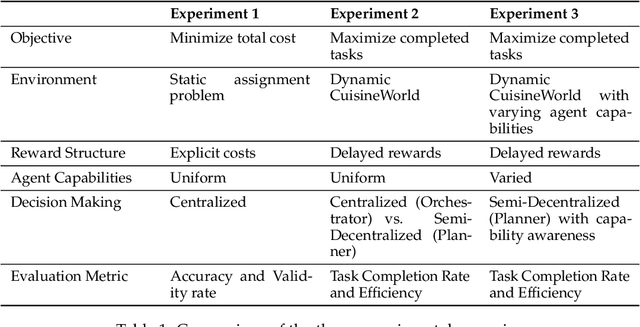
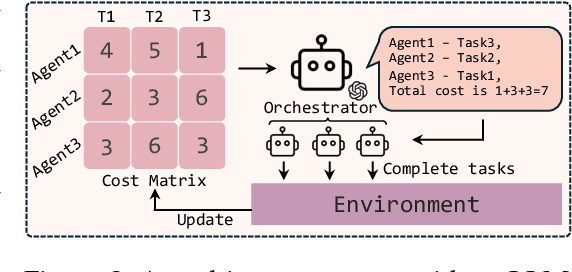
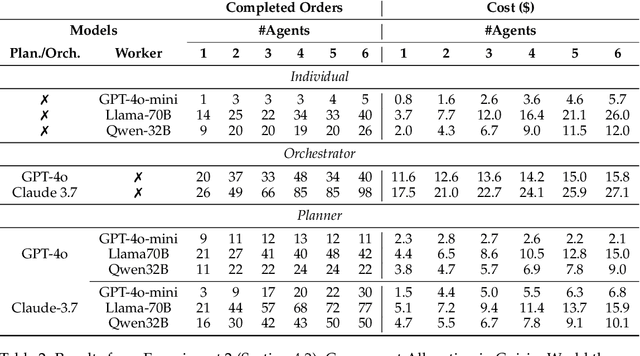
With the development of LLMs as agents, there is a growing interest in connecting multiple agents into multi-agent systems to solve tasks concurrently, focusing on their role in task assignment and coordination. This paper explores how LLMs can effectively allocate computational tasks among multiple agents, considering factors such as cost, efficiency, and performance. In this work, we address key questions, including the effectiveness of LLMs as orchestrators and planners, comparing their effectiveness in task assignment and coordination. Our experiments demonstrate that LLMs can achieve high validity and accuracy in resource allocation tasks. We find that the planner method outperforms the orchestrator method in handling concurrent actions, resulting in improved efficiency and better utilization of agents. Additionally, we show that providing explicit information about worker capabilities enhances the allocation strategies of planners, particularly when dealing with suboptimal workers.
KVLink: Accelerating Large Language Models via Efficient KV Cache Reuse
Feb 21, 2025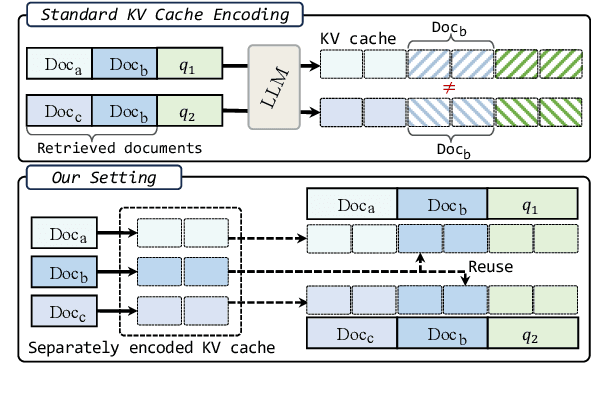
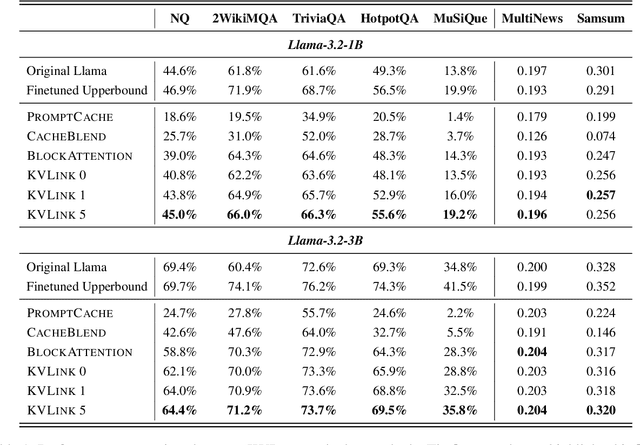
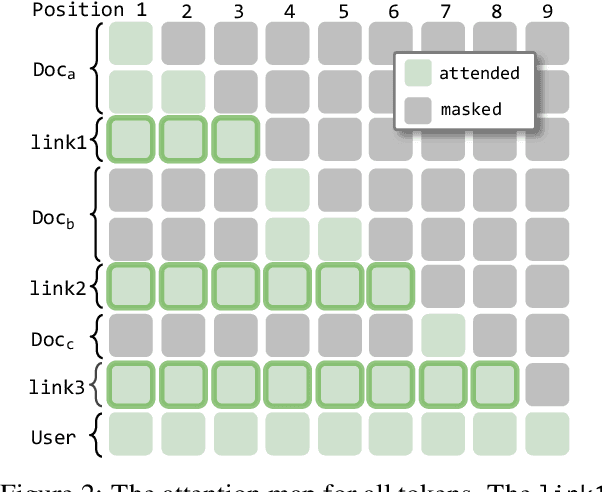
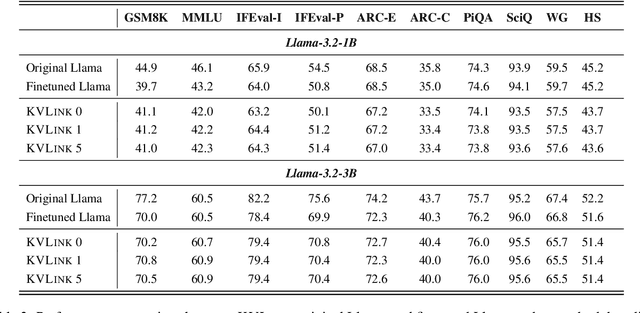
We describe KVLink, an approach for efficient key-value (KV) cache reuse in large language models (LLMs). In many LLM applications, different inputs can share overlapping context, such as the same retrieved document appearing in multiple queries. However, the LLMs still need to encode the entire context for each query, leading to redundant computation. In this paper, we propose a new strategy to eliminate such inefficiency, where the KV cache of each document is precomputed independently. During inference, the KV caches of retrieved documents are concatenated, allowing the model to reuse cached representations instead of recomputing them. To mitigate the performance degradation of LLMs when using KV caches computed independently for each document, KVLink introduces three key components: adjusting positional embeddings of the KV cache at inference to match the global position after concatenation, using trainable special tokens to restore self-attention across independently encoded documents, and applying mixed-data fine-tuning to enhance performance while preserving the model's original capabilities. Experiments across 7 datasets demonstrate that KVLink improves question answering accuracy by an average of 4% over state-of-the-art methods. Furthermore, by leveraging precomputed KV caches, our approach reduces time-to-first-token by up to 90% compared to standard LLM inference, making it a scalable and efficient solution for context reuse.
Driver2vec: Driver Identification from Automotive Data
Feb 10, 2021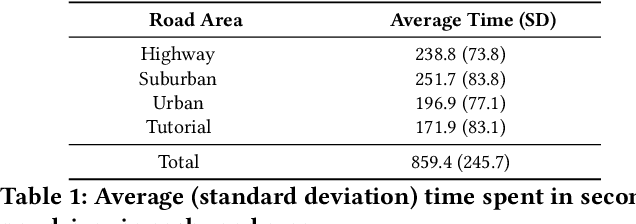
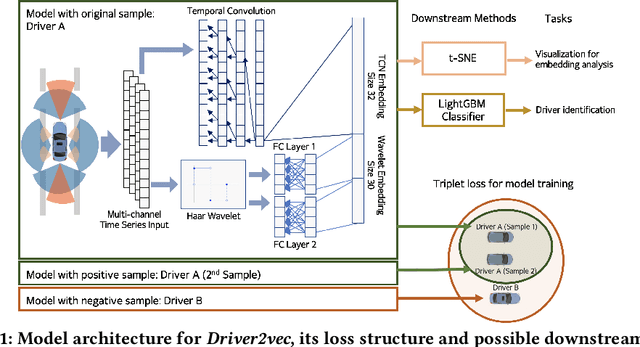
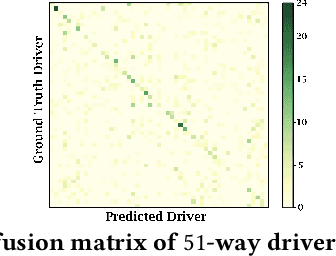

With increasing focus on privacy protection, alternative methods to identify vehicle operator without the use of biometric identifiers have gained traction for automotive data analysis. The wide variety of sensors installed on modern vehicles enable autonomous driving, reduce accidents and improve vehicle handling. On the other hand, the data these sensors collect reflect drivers' habit. Drivers' use of turn indicators, following distance, rate of acceleration, etc. can be transformed to an embedding that is representative of their behavior and identity. In this paper, we develop a deep learning architecture (Driver2vec) to map a short interval of driving data into an embedding space that represents the driver's behavior to assist in driver identification. We develop a custom model that leverages performance gains of temporal convolutional networks, embedding separation power of triplet loss and classification accuracy of gradient boosting decision trees. Trained on a dataset of 51 drivers provided by Nervtech, Driver2vec is able to accurately identify the driver from a short 10-second interval of sensor data, achieving an average pairwise driver identification accuracy of 83.1% from this 10-second interval, which is remarkably higher than performance obtained in previous studies. We then analyzed performance of Driver2vec to show that its performance is consistent across scenarios and that modeling choices are sound.
MoCo Pretraining Improves Representation and Transferability of Chest X-ray Models
Oct 11, 2020

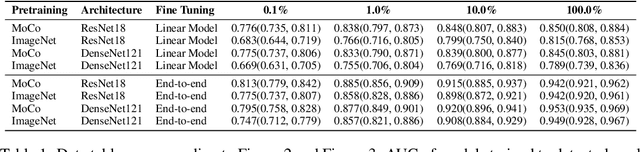
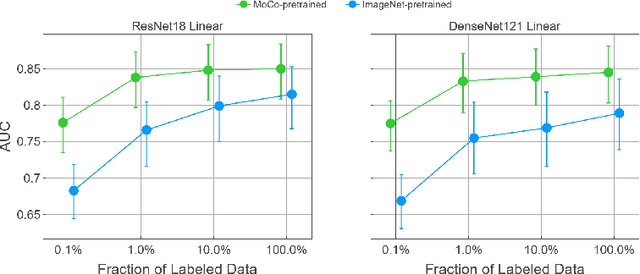
Self-supervised approaches such as Momentum Contrast (MoCo) can leverage unlabeled data to produce pretrained models for subsequent fine-tuning on labeled data. While MoCo has demonstrated promising results on natural image classification tasks, its application to medical imaging tasks like chest X-ray interpretation has been limited. Chest X-ray interpretation is fundamentally different from natural image classification in ways that may limit the applicability of self-supervised approaches. In this work, we investigate whether MoCo-pretraining leads to better representations or initializations for chest X-ray interpretation. We conduct MoCo-pretraining on CheXpert, a large labeled dataset of X-rays, followed by supervised fine-tuning experiments on the pleural effusion task. Using 0.1% of labeled training data, we find that a linear model trained on MoCo-pretrained representations outperforms one trained on representations without MoCo-pretraining by an AUC of 0.096 (95% CI 0.061, 0.130), indicating that MoCo-pretrained representations are of higher quality. Furthermore, a model fine-tuned end-to-end with MoCo-pretraining outperforms its non-MoCo-pretrained counterpart by an AUC of 0.037 (95% CI 0.015, 0.062) with the 0.1% label fraction. These AUC improvements are observed for all label fractions for both the linear model and an end-to-end fine-tuned model with the greater improvements for smaller label fractions. Finally, we observe similar results on a small, target chest X-ray dataset (Shenzhen dataset for tuberculosis) with MoCo-pretraining done on the source dataset (CheXpert), which suggests that pretraining on unlabeled X-rays can provide transfer learning benefits for a target task. Our study demonstrates that MoCo-pretraining provides high-quality representations and transferable initializations for chest X-ray interpretation.