 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionHarmonizer: Bridging Neural Reconstruction and Photorealistic Simulation with Online Diffusion Enhancer
Mar 05, 2026Simulation is essential to the development and evaluation of autonomous robots such as self-driving vehicles. Neural reconstruction is emerging as a promising solution as it enables simulating a wide variety of scenarios from real-world data alone in an automated and scalable way. However, while methods such as NeRF and 3D Gaussian Splatting can produce visually compelling results, they often exhibit artifacts particularly when rendering novel views, and fail to realistically integrate inserted dynamic objects, especially when they were captured from different scenes. To overcome these limitations, we introduce DiffusionHarmonizer, an online generative enhancement framework that transforms renderings from such imperfect scenes into temporally consistent outputs while improving their realism. At its core is a single-step temporally-conditioned enhancer that is converted from a pretrained multi-step image diffusion model, capable of running in online simulators on a single GPU. The key to training it effectively is a custom data curation pipeline that constructs synthetic-real pairs emphasizing appearance harmonization, artifact correction, and lighting realism. The result is a scalable system that significantly elevates simulation fidelity in both research and production environments.
ArtiFixer: Enhancing and Extending 3D Reconstruction with Auto-Regressive Diffusion Models
Feb 28, 2026Per-scene optimization methods such as 3D Gaussian Splatting provide state-of-the-art novel view synthesis quality but extrapolate poorly to under-observed areas. Methods that leverage generative priors to correct artifacts in these areas hold promise but currently suffer from two shortcomings. The first is scalability, as existing methods use image diffusion models or bidirectional video models that are limited in the number of views they can generate in a single pass (and thus require a costly iterative distillation process for consistency). The second is quality itself, as generators used in prior work tend to produce outputs that are inconsistent with existing scene content and fail entirely in completely unobserved regions. To solve these, we propose a two-stage pipeline that leverages two key insights. First, we train a powerful bidirectional generative model with a novel opacity mixing strategy that encourages consistency with existing observations while retaining the model's ability to extrapolate novel content in unseen areas. Second, we distill it into a causal auto-regressive model that generates hundreds of frames in a single pass. This model can directly produce novel views or serve as pseudo-supervision to improve the underlying 3D representation in a simple and highly efficient manner. We evaluate our method extensively and demonstrate that it can generate plausible reconstructions in scenarios where existing approaches fail completely. When measured on commonly benchmarked datasets, we outperform existing all existing baselines by a wide margin, exceeding prior state-of-the-art methods by 1-3 dB PSNR.
Tracking Everything Everywhere All at Once
Jun 08, 2023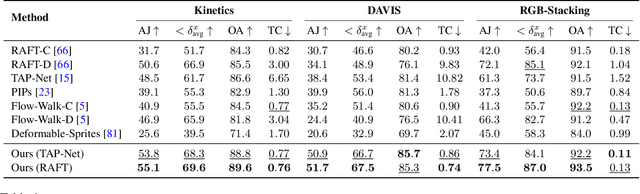
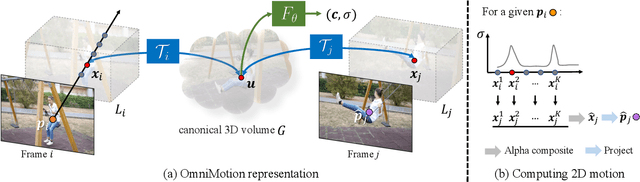
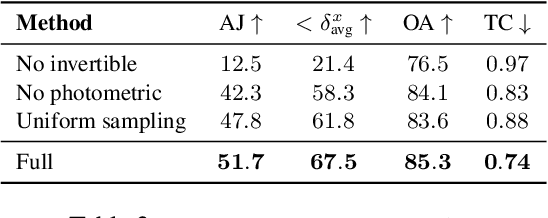

We present a new test-time optimization method for estimating dense and long-range motion from a video sequence. Prior optical flow or particle video tracking algorithms typically operate within limited temporal windows, struggling to track through occlusions and maintain global consistency of estimated motion trajectories. We propose a complete and globally consistent motion representation, dubbed OmniMotion, that allows for accurate, full-length motion estimation of every pixel in a video. OmniMotion represents a video using a quasi-3D canonical volume and performs pixel-wise tracking via bijections between local and canonical space. This representation allows us to ensure global consistency, track through occlusions, and model any combination of camera and object motion. Extensive evaluations on the TAP-Vid benchmark and real-world footage show that our approach outperforms prior state-of-the-art methods by a large margin both quantitatively and qualitatively. See our project page for more results: http://omnimotion.github.io/
Learning Object-Centric Neural Scattering Functions for Free-viewpoint Relighting and Scene Composition
Mar 10, 2023



Photorealistic object appearance modeling from 2D images is a constant topic in vision and graphics. While neural implicit methods (such as Neural Radiance Fields) have shown high-fidelity view synthesis results, they cannot relight the captured objects. More recent neural inverse rendering approaches have enabled object relighting, but they represent surface properties as simple BRDFs, and therefore cannot handle translucent objects. We propose Object-Centric Neural Scattering Functions (OSFs) for learning to reconstruct object appearance from only images. OSFs not only support free-viewpoint object relighting, but also can model both opaque and translucent objects. While accurately modeling subsurface light transport for translucent objects can be highly complex and even intractable for neural methods, OSFs learn to approximate the radiance transfer from a distant light to an outgoing direction at any spatial location. This approximation avoids explicitly modeling complex subsurface scattering, making learning a neural implicit model tractable. Experiments on real and synthetic data show that OSFs accurately reconstruct appearances for both opaque and translucent objects, allowing faithful free-viewpoint relighting as well as scene composition.
Learning Electron Bunch Distribution along a FEL Beamline by Normalising Flows
Feb 27, 2023Understanding and control of Laser-driven Free Electron Lasers remain to be difficult problems that require highly intensive experimental and theoretical research. The gap between simulated and experimentally collected data might complicate studies and interpretation of obtained results. In this work we developed a deep learning based surrogate that could help to fill in this gap. We introduce a surrogate model based on normalising flows for conditional phase-space representation of electron clouds in a FEL beamline. Achieved results let us discuss further benefits and limitations in exploitability of the models to gain deeper understanding of fundamental processes within a beamline.
* 7 pages, 5 figures
ObjectFolder 2.0: A Multisensory Object Dataset for Sim2Real Transfer
Apr 05, 2022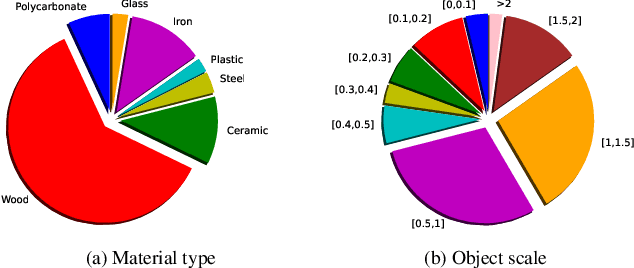
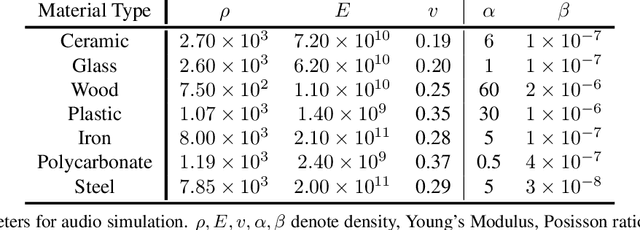


Objects play a crucial role in our everyday activities. Though multisensory object-centric learning has shown great potential lately, the modeling of objects in prior work is rather unrealistic. ObjectFolder 1.0 is a recent dataset that introduces 100 virtualized objects with visual, acoustic, and tactile sensory data. However, the dataset is small in scale and the multisensory data is of limited quality, hampering generalization to real-world scenarios. We present ObjectFolder 2.0, a large-scale, multisensory dataset of common household objects in the form of implicit neural representations that significantly enhances ObjectFolder 1.0 in three aspects. First, our dataset is 10 times larger in the amount of objects and orders of magnitude faster in rendering time. Second, we significantly improve the multisensory rendering quality for all three modalities. Third, we show that models learned from virtual objects in our dataset successfully transfer to their real-world counterparts in three challenging tasks: object scale estimation, contact localization, and shape reconstruction. ObjectFolder 2.0 offers a new path and testbed for multisensory learning in computer vision and robotics. The dataset is available at https://github.com/rhgao/ObjectFolder.
ObjectFolder: A Dataset of Objects with Implicit Visual, Auditory, and Tactile Representations
Sep 18, 2021
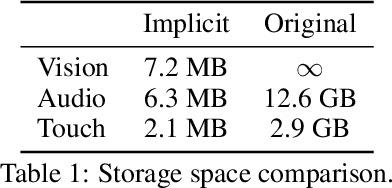

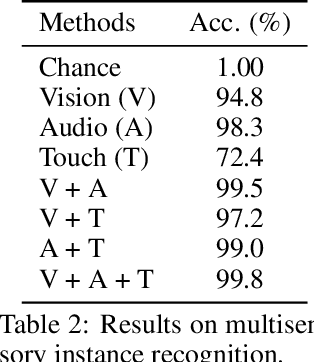
Multisensory object-centric perception, reasoning, and interaction have been a key research topic in recent years. However, the progress in these directions is limited by the small set of objects available -- synthetic objects are not realistic enough and are mostly centered around geometry, while real object datasets such as YCB are often practically challenging and unstable to acquire due to international shipping, inventory, and financial cost. We present ObjectFolder, a dataset of 100 virtualized objects that addresses both challenges with two key innovations. First, ObjectFolder encodes the visual, auditory, and tactile sensory data for all objects, enabling a number of multisensory object recognition tasks, beyond existing datasets that focus purely on object geometry. Second, ObjectFolder employs a uniform, object-centric, and implicit representation for each object's visual textures, acoustic simulations, and tactile readings, making the dataset flexible to use and easy to share. We demonstrate the usefulness of our dataset as a testbed for multisensory perception and control by evaluating it on a variety of benchmark tasks, including instance recognition, cross-sensory retrieval, 3D reconstruction, and robotic grasping.
Data-Driven Shadowgraph Simulation of a 3D Object
Jun 01, 2021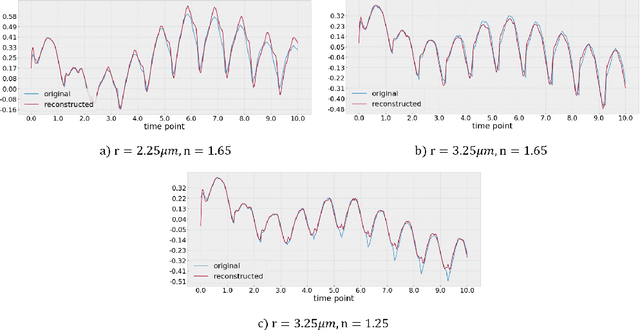
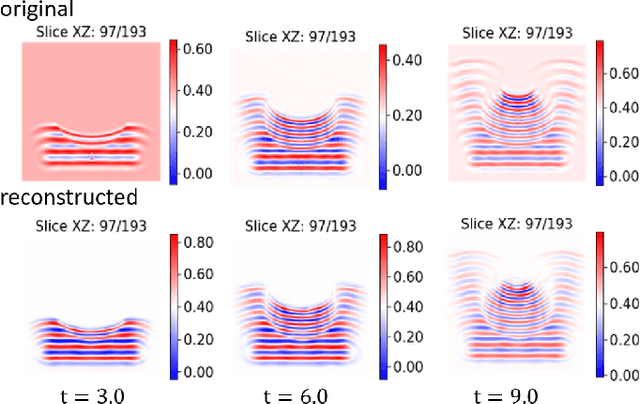
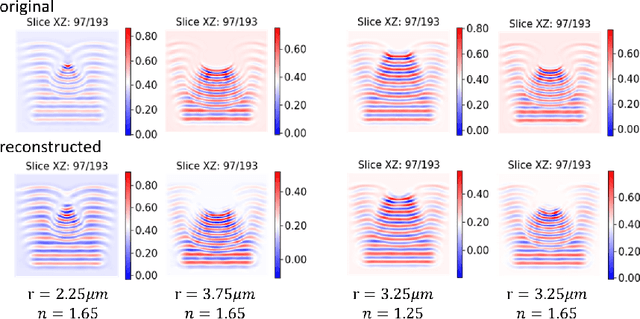
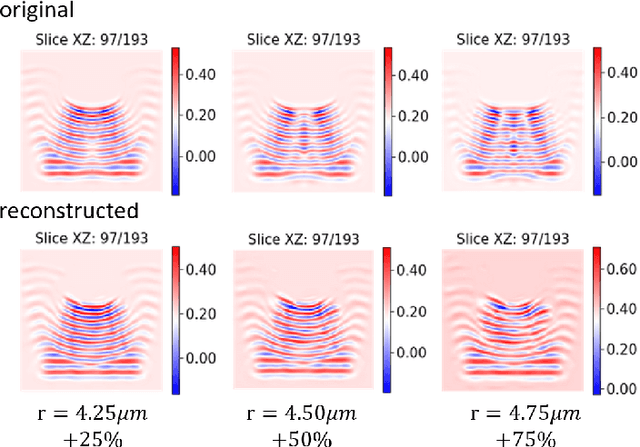
In this work we propose a deep neural network based surrogate model for a plasma shadowgraph - a technique for visualization of perturbations in a transparent medium. We are substituting the numerical code by a computationally cheaper projection based surrogate model that is able to approximate the electric fields at a given time without computing all preceding electric fields as required by numerical methods. This means that the projection based surrogate model allows to recover the solution of the governing 3D partial differential equation, 3D wave equation, at any point of a given compute domain and configuration without the need to run a full simulation. This model has shown a good quality of reconstruction in a problem of interpolation of data within a narrow range of simulation parameters and can be used for input data of large size.
Inductive Representation Learning in Temporal Networks via Causal Anonymous Walks
Jan 15, 2021

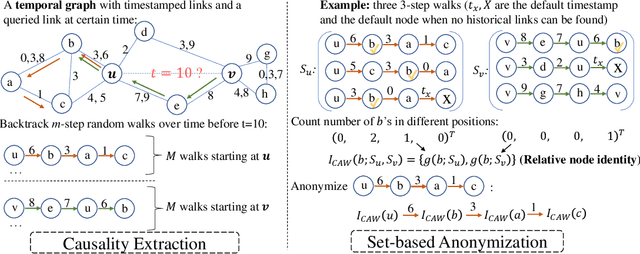
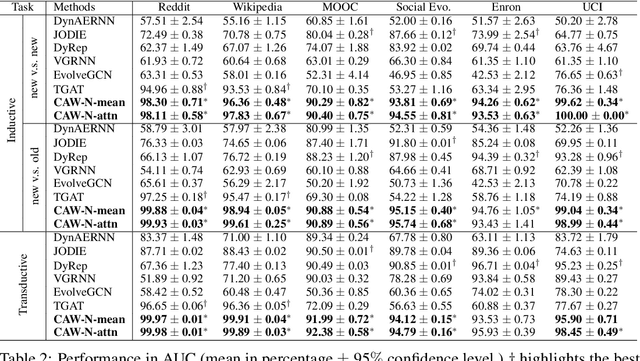
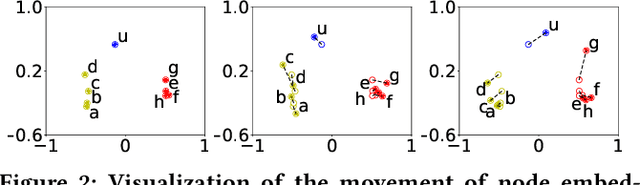
Temporal networks serve as abstractions of many real-world dynamic systems. These networks typically evolve according to certain laws, such as the law of triadic closure, which is universal in social networks. Inductive representation learning of temporal networks should be able to capture such laws and further be applied to systems that follow the same laws but have not been unseen during the training stage. Previous works in this area depend on either network node identities or rich edge attributes and typically fail to extract these laws. Here, we propose Causal Anonymous Walks (CAWs) to inductively represent a temporal network. CAWs are extracted by temporal random walks and work as automatic retrieval of temporal network motifs to represent network dynamics while avoiding the time-consuming selection and counting of those motifs. CAWs adopt a novel anonymization strategy that replaces node identities with the hitting counts of the nodes based on a set of sampled walks to keep the method inductive, and simultaneously establish the correlation between motifs. We further propose a neural-network model CAW-N to encode CAWs, and pair it with a CAW sampling strategy with constant memory and time cost to support online training and inference. CAW-N is evaluated to predict links over 6 real temporal networks and uniformly outperforms previous SOTA methods by averaged 15% AUC gain in the inductive setting. CAW-N also outperforms previous methods in 5 out of the 6 networks in the transductive setting.
F-FADE: Frequency Factorization for Anomaly Detection in Edge Streams
Nov 09, 2020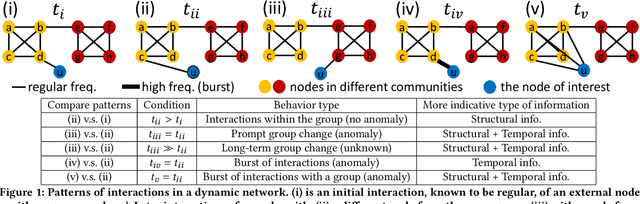


Edge streams are commonly used to capture interactions in dynamic networks, such as email, social, or computer networks. The problem of detecting anomalies or rare events in edge streams has a wide range of applications. However, it presents many challenges due to lack of labels, a highly dynamic nature of interactions, and the entanglement of temporal and structural changes in the network. Current methods are limited in their ability to address the above challenges and to efficiently process a large number of interactions. Here, we propose F-FADE, a new approach for detection of anomalies in edge streams, which uses a novel frequency-factorization technique to efficiently model the time-evolving distributions of frequencies of interactions between node-pairs. The anomalies are then determined based on the likelihood of the observed frequency of each incoming interaction. F-FADE is able to handle in an online streaming setting a broad variety of anomalies with temporal and structural changes, while requiring only constant memory. Our experiments on one synthetic and six real-world dynamic networks show that F-FADE achieves state of the art performance and may detect anomalies that previous methods are unable to find.