 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-free Knowledge Distillation for Segmentation using Data-Enriching GAN
Paper and Code
Nov 02, 2020


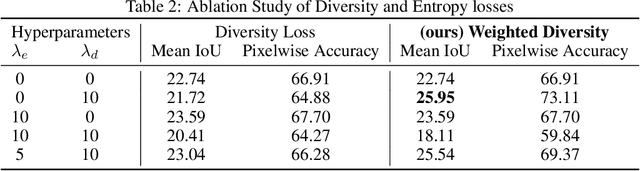
Distilling knowledge from huge pre-trained networks to improve the performance of tiny networks has favored deep learning models to be used in many real-time and mobile applications. Several approaches that demonstrate success in this field have made use of the true training dataset to extract relevant knowledge. In absence of the True dataset, however, extracting knowledge from deep networks is still a challenge. Recent works on data-free knowledge distillation demonstrate such techniques on classification tasks. To this end, we explore the task of data-free knowledge distillation for segmentation tasks. First, we identify several challenges specific to segmentation. We make use of the DeGAN training framework to propose a novel loss function for enforcing diversity in a setting where a few classes are underrepresented. Further, we explore a new training framework for performing knowledge distillation in a data-free setting. We get an improvement of 6.93% in Mean IoU over previous approaches.