 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Object-Centric World Models Meet Policy Learning: From Pixels to Policies, and Where It Breaks
Nov 11, 2025Object-centric world models (OCWM) aim to decompose visual scenes into object-level representations, providing structured abstractions that could improve compositional generalization and data efficiency in reinforcement learning. We hypothesize that explicitly disentangled object-level representations, by localizing task-relevant information, can enhance policy performance across novel feature combinations. To test this hypothesis, we introduce DLPWM, a fully unsupervised, disentangled object-centric world model that learns object-level latents directly from pixels. DLPWM achieves strong reconstruction and prediction performance, including robustness to several out-of-distribution (OOD) visual variations. However, when used for downstream model-based control, policies trained on DLPWM latents underperform compared to DreamerV3. Through latent-trajectory analyses, we identify representation shift during multi-object interactions as a key driver of unstable policy learning. Our results suggest that, although object-centric perception supports robust visual modeling, achieving stable control requires mitigating latent drift.
Object-Centric Temporal Consistency via Conditional Autoregressive Inductive Biases
Oct 21, 2024



Unsupervised object-centric learning from videos is a promising approach towards learning compositional representations that can be applied to various downstream tasks, such as prediction and reasoning. Recently, it was shown that pretrained Vision Transformers (ViTs) can be useful to learn object-centric representations on real-world video datasets. However, while these approaches succeed at extracting objects from the scenes, the slot-based representations fail to maintain temporal consistency across consecutive frames in a video, i.e. the mapping of objects to slots changes across the video. To address this, we introduce Conditional Autoregressive Slot Attention (CA-SA), a framework that enhances the temporal consistency of extracted object-centric representations in video-centric vision tasks. Leveraging an autoregressive prior network to condition representations on previous timesteps and a novel consistency loss function, CA-SA predicts future slot representations and imposes consistency across frames. We present qualitative and quantitative results showing that our proposed method outperforms the considered baselines on downstream tasks, such as video prediction and visual question-answering tasks.
Masked Generative Priors Improve World Models Sequence Modelling Capabilities
Oct 10, 2024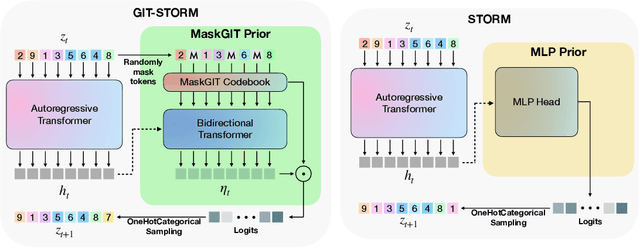


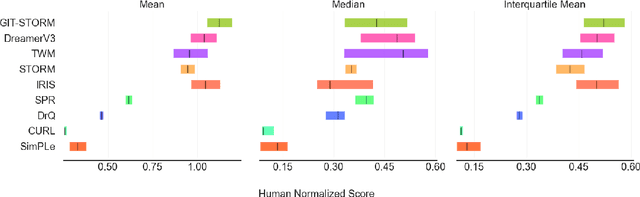
Deep Reinforcement Learning (RL) has become the leading approach for creating artificial agents in complex environments. Model-based approaches, which are RL methods with world models that predict environment dynamics, are among the most promising directions for improving data efficiency, forming a critical step toward bridging the gap between research and real-world deployment. In particular, world models enhance sample efficiency by learning in imagination, which involves training a generative sequence model of the environment in a self-supervised manner. Recently, Masked Generative Modelling has emerged as a more efficient and superior inductive bias for modelling and generating token sequences. Building on the Efficient Stochastic Transformer-based World Models (STORM) architecture, we replace the traditional MLP prior with a Masked Generative Prior (e.g., MaskGIT Prior) and introduce GIT-STORM. We evaluate our model on two downstream tasks: reinforcement learning and video prediction. GIT-STORM demonstrates substantial performance gains in RL tasks on the Atari 100k benchmark. Moreover, we apply Transformer-based World Models to continuous action environments for the first time, addressing a significant gap in prior research. To achieve this, we employ a state mixer function that integrates latent state representations with actions, enabling our model to handle continuous control tasks. We validate this approach through qualitative and quantitative analyses on the DeepMind Control Suite, showcasing the effectiveness of Transformer-based World Models in this new domain. Our results highlight the versatility and efficacy of the MaskGIT dynamics prior, paving the way for more accurate world models and effective RL policies.
Cross-Task Consistency Learning Framework for Multi-Task Learning
Nov 28, 2021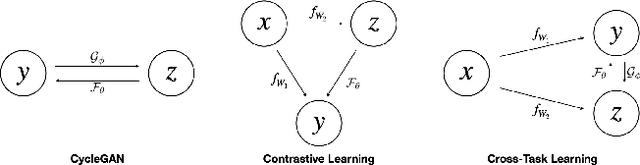



Multi-task learning (MTL) is an active field in deep learning in which we train a model to jointly learn multiple tasks by exploiting relationships between the tasks. It has been shown that MTL helps the model share the learned features between tasks and enhance predictions compared to when learning each task independently. We propose a new learning framework for 2-task MTL problem that uses the predictions of one task as inputs to another network to predict the other task. We define two new loss terms inspired by cycle-consistency loss and contrastive learning, alignment loss and cross-task consistency loss. Both losses are designed to enforce the model to align the predictions of multiple tasks so that the model predicts consistently. We theoretically prove that both losses help the model learn more efficiently and that cross-task consistency loss is better in terms of alignment with the straight-forward predictions. Experimental results also show that our proposed model achieves significant performance on the benchmark Cityscapes and NYU dataset.