 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture frame prediction in chest cine MR imaging using the PCA respiratory motion model and dynamically trained recurrent neural networks
Oct 08, 2024Lung radiotherapy treatment systems are subject to a latency that leads to uncertainty in the estimated tumor location and high irradiation of healthy tissue. This work addresses future frame prediction in chest dynamic MRI sequences to compensate for that delay using RNNs trained with online learning algorithms. The latter enable networks to mitigate irregular movements, as they update synaptic weights with each new training example. Experiments were conducted using four publicly available 2D thoracic cine-MRI sequences. PCA decomposes the time-varying deformation vector field (DVF), computed with the Lucas-Kanade optical flow algorithm, into static deformation fields and low-dimensional time-dependent weights. We compare various algorithms to forecast the latter: linear regression, least mean squares (LMS), and RNNs trained with real-time recurrent learning (RTRL), unbiased online recurrent optimization, decoupled neural interfaces and sparse 1-step approximation (SnAp-1). That enables estimating the future DVFs and, in turn, the next frames by warping the initial image. Linear regression led to the lowest mean DVF error at a horizon h = 0.32s (the time interval in advance for which the prediction is made), equal to 1.30mm, followed by SnAp-1 and RTRL, whose error increased from 1.37mm to 1.44mm as h increased from 0.62s to 2.20s. Similarly, the structural similarity index measure (SSIM) of LMS decreased from 0.904 to 0.898 as h increased from 0.31s to 1.57s and was the highest among the algorithms compared for the latter horizons. SnAp-1 attained the highest SSIM for h $\geq$ 1.88s, with values of less than 0.898. The predicted images look similar to the original ones, and the highest errors occurred at challenging areas such as the diaphragm boundary at the end-of-inhale phase, where motion variability is more prominent, and regions where out-of-plane motion was more prevalent.
Quater-GCN: Enhancing 3D Human Pose Estimation with Orientation and Semi-supervised Training
Apr 30, 2024



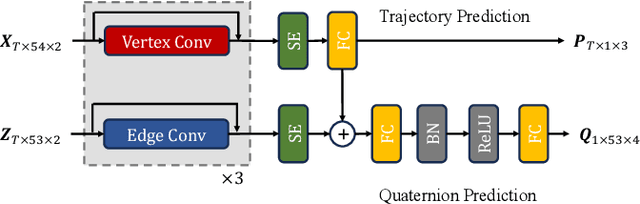
3D human pose estimation is a vital task in computer vision, involving the prediction of human joint positions from images or videos to reconstruct a skeleton of a human in three-dimensional space. This technology is pivotal in various fields, including animation, security, human-computer interaction, and automotive safety, where it promotes both technological progress and enhanced human well-being. The advent of deep learning significantly advances the performance of 3D pose estimation by incorporating temporal information for predicting the spatial positions of human joints. However, traditional methods often fall short as they primarily focus on the spatial coordinates of joints and overlook the orientation and rotation of the connecting bones, which are crucial for a comprehensive understanding of human pose in 3D space. To address these limitations, we introduce Quater-GCN (Q-GCN), a directed graph convolutional network tailored to enhance pose estimation by orientation. Q-GCN excels by not only capturing the spatial dependencies among node joints through their coordinates but also integrating the dynamic context of bone rotations in 2D space. This approach enables a more sophisticated representation of human poses by also regressing the orientation of each bone in 3D space, moving beyond mere coordinate prediction. Furthermore, we complement our model with a semi-supervised training strategy that leverages unlabeled data, addressing the challenge of limited orientation ground truth data. Through comprehensive evaluations, Q-GCN has demonstrated outstanding performance against current state-of-the-art methods.
An Animation-based Augmentation Approach for Action Recognition from Discontinuous Video
Apr 10, 2024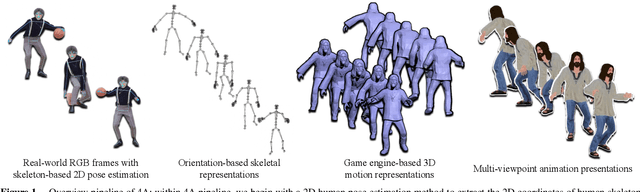
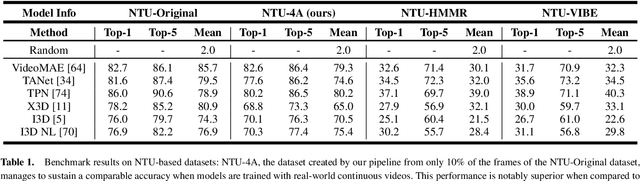
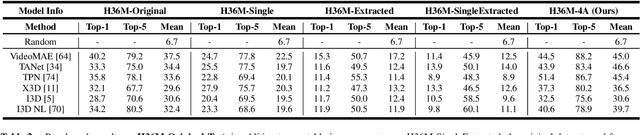
The study of action recognition has attracted considerable attention recently due to its broad applications in multiple areas. However, with the issue of discontinuous training video, which not only decreases the performance of action recognition model, but complicates the data augmentation process as well, still remains under-exploration. In this study, we introduce the 4A (Action Animation-based Augmentation Approach), an innovative pipeline for data augmentation to address the problem. The main contributions remain in our work includes: (1) we investigate the problem of severe decrease on performance of action recognition task training by discontinuous video, and the limitation of existing augmentation methods on solving this problem. (2) we propose a novel augmentation pipeline, 4A, to address the problem of discontinuous video for training, while achieving a smoother and natural-looking action representation than the latest data augmentation methodology. (3) We achieve the same performance with only 10% of the original data for training as with all of the original data from the real-world dataset, and a better performance on In-the-wild videos, by employing our data augmentation techniques.
Respiratory motion forecasting with online learning of recurrent neural networks for safety enhancement in externally guided radiotherapy
Mar 03, 2024



In lung radiotherapy, infrared cameras can record the location of reflective objects on the chest to infer the position of the tumor moving due to breathing, but treatment system latencies hinder radiation beam precision. Real-time recurrent learning (RTRL), is a potential solution as it can learn patterns within non-stationary respiratory data but has high complexity. This study assesses the capabilities of resource-efficient online RNN algorithms, namely unbiased online recurrent optimization (UORO), sparse-1 step approximation (SnAp-1), and decoupled neural interfaces (DNI) to forecast respiratory motion during radiotherapy treatment accurately. We use time series containing the 3D position of external markers on the chest of healthy subjects. We propose efficient implementations for SnAp-1 and DNI based on compression of the influence and immediate Jacobian matrices and an accurate update of the linear coefficients used in credit assignment estimation, respectively. The original sampling frequency was 10Hz; we performed resampling at 3.33Hz and 30Hz. We use UORO, SnAp-1, and DNI to forecast each marker's 3D position with horizons (the time interval in advance for which the prediction is made) h<=2.1s and compare them with RTRL, least mean squares, and linear regression. RNNs trained online achieved similar or better accuracy than most previous works using larger training databases and deep learning, even though we used only the first minute of each sequence to predict motion within that exact sequence. SnAp-1 had the lowest normalized root mean square errors (nRMSE) averaged over the horizon values considered, equal to 0.335 and 0.157, at 3.33Hz and 10.0Hz, respectively. Similarly, UORO had the highest accuracy at 30Hz, with an nRMSE of 0.0897. DNI's inference time, equal to 6.8ms per time step at 30Hz (Intel Core i7-13700 CPU), was the lowest among the RNN methods examined.
GTAutoAct: An Automatic Datasets Generation Framework Based on Game Engine Redevelopment for Action Recognition
Jan 24, 2024Current datasets for action recognition tasks face limitations stemming from traditional collection and generation methods, including the constrained range of action classes, absence of multi-viewpoint recordings, limited diversity, poor video quality, and labor-intensive manually collection. To address these challenges, we introduce GTAutoAct, a innovative dataset generation framework leveraging game engine technology to facilitate advancements in action recognition. GTAutoAct excels in automatically creating large-scale, well-annotated datasets with extensive action classes and superior video quality. Our framework's distinctive contributions encompass: (1) it innovatively transforms readily available coordinate-based 3D human motion into rotation-orientated representation with enhanced suitability in multiple viewpoints; (2) it employs dynamic segmentation and interpolation of rotation sequences to create smooth and realistic animations of action; (3) it offers extensively customizable animation scenes; (4) it implements an autonomous video capture and processing pipeline, featuring a randomly navigating camera, with auto-trimming and labeling functionalities. Experimental results underscore the framework's robustness and highlights its potential to significantly improve action recognition model training.
Prediction of the motion of chest internal points using a recurrent neural network trained with real-time recurrent learning for latency compensation in lung cancer radiotherapy
Jul 13, 2022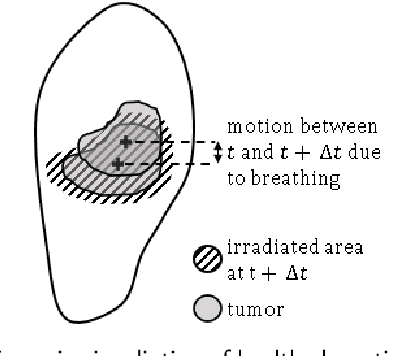

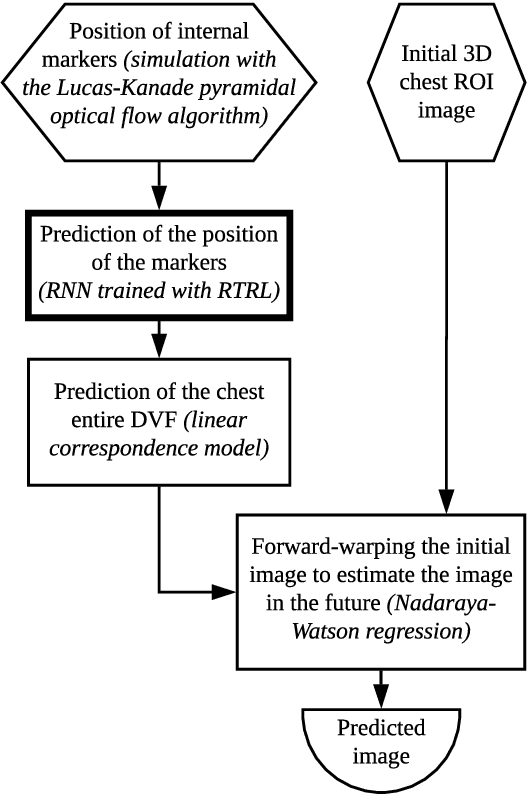

During the radiotherapy treatment of patients with lung cancer, the radiation delivered to healthy tissue around the tumor needs to be minimized, which is difficult because of respiratory motion and the latency of linear accelerator systems. In the proposed study, we first use the Lucas-Kanade pyramidal optical flow algorithm to perform deformable image registration of chest computed tomography scan images of four patients with lung cancer. We then track three internal points close to the lung tumor based on the previously computed deformation field and predict their position with a recurrent neural network (RNN) trained using real-time recurrent learning (RTRL) and gradient clipping. The breathing data is quite regular, sampled at approximately 2.5Hz, and includes artificial drift in the spine direction. The amplitude of the motion of the tracked points ranged from 12.0mm to 22.7mm. Finally, we propose a simple method for recovering and predicting 3D tumor images from the tracked points and the initial tumor image based on a linear correspondence model and Nadaraya-Watson non-linear regression. The root-mean-square error, maximum error, and jitter corresponding to the RNN prediction on the test set were smaller than the same performance measures obtained with linear prediction and least mean squares (LMS). In particular, the maximum prediction error associated with the RNN, equal to 1.51mm, is respectively 16.1% and 5.0% lower than the maximum error associated with linear prediction and LMS. The average prediction time per time step with RTRL is equal to 119ms, which is less than the 400ms marker position sampling time. The tumor position in the predicted images appears visually correct, which is confirmed by the high mean cross-correlation between the original and predicted images, equal to 0.955.
* 21 pages, 24 figures; accepted manuscript version
Cross-Task Consistency Learning Framework for Multi-Task Learning
Nov 28, 2021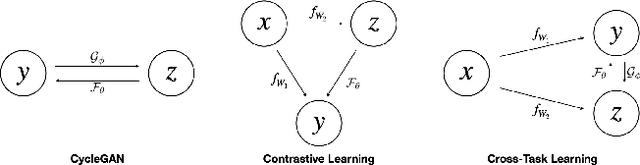



Multi-task learning (MTL) is an active field in deep learning in which we train a model to jointly learn multiple tasks by exploiting relationships between the tasks. It has been shown that MTL helps the model share the learned features between tasks and enhance predictions compared to when learning each task independently. We propose a new learning framework for 2-task MTL problem that uses the predictions of one task as inputs to another network to predict the other task. We define two new loss terms inspired by cycle-consistency loss and contrastive learning, alignment loss and cross-task consistency loss. Both losses are designed to enforce the model to align the predictions of multiple tasks so that the model predicts consistently. We theoretically prove that both losses help the model learn more efficiently and that cross-task consistency loss is better in terms of alignment with the straight-forward predictions. Experimental results also show that our proposed model achieves significant performance on the benchmark Cityscapes and NYU dataset.
Prediction of the Position of External Markers Using a Recurrent Neural Network Trained With Unbiased Online Recurrent Optimization for Safe Lung Cancer Radiotherapy
Jun 02, 2021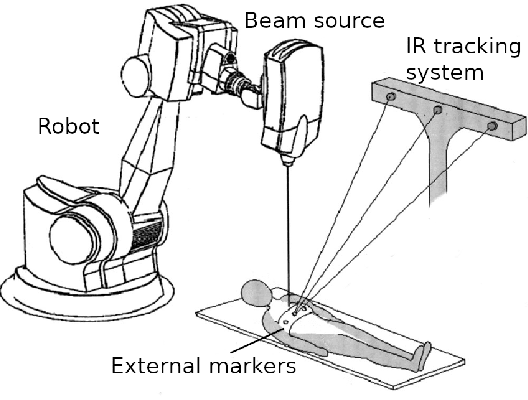
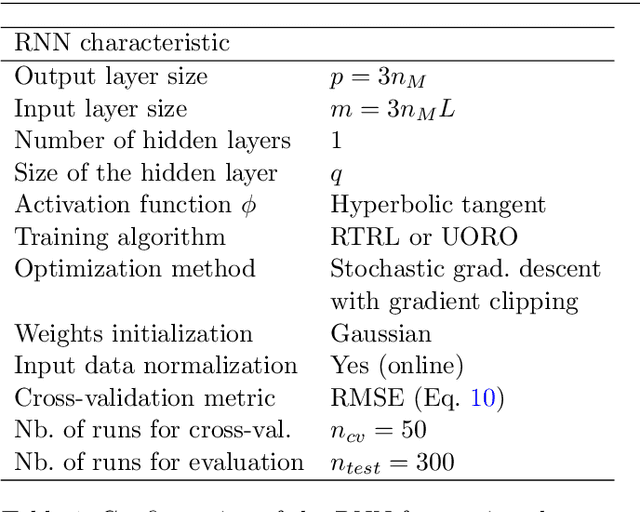
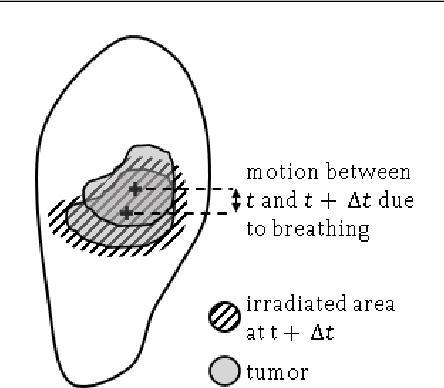
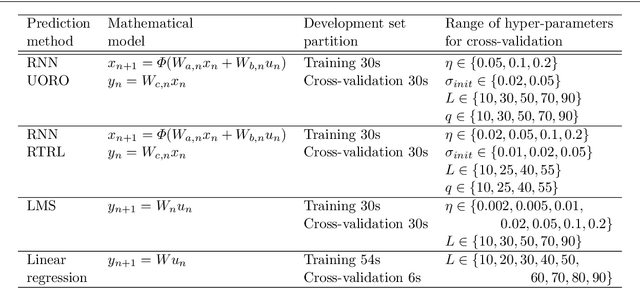
During lung cancer radiotherapy, the position of infrared reflective objects on the chest can be recorded to estimate the tumor location. However, radiotherapy systems usually have a latency inherent to robot control limitations that impedes the radiation delivery precision. Not taking this phenomenon into account may cause unwanted damage to healthy tissues and lead to side effects such as radiation pneumonitis. In this research, we use nine observation records of the three-dimensional position of three external markers on the chest and abdomen of healthy individuals breathing during intervals from 73s to 222s. The sampling frequency is equal to 10Hz and the amplitudes of the recorded trajectories range from 6mm to 40mm in the superior-inferior direction. We forecast the location of each marker simultaneously with a horizon value (the time interval in advance for which the prediction is made) between 0.1s and 2.0s, using a recurrent neural network (RNN) trained with unbiased online recurrent optimization (UORO). We compare its performance with an RNN trained with real-time recurrent learning, least mean squares (LMS), and offline linear regression. Training and cross-validation are performed during the first minute of each sequence. On average, UORO achieves the lowest root-mean-square (RMS) and maximum error, equal respectively to 1.3mm and 8.8mm, with a prediction time per time step lower than 2.8ms (Dell Intel core i9-9900K 3.60Ghz). Linear regression has the lowest RMS error for the horizon values 0.1s and 0.2s, followed by LMS for horizon values between 0.3s and 0.5s, and UORO for horizon values greater than 0.6s.