 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Stage Huffman Encoder for ML Compression
Jan 15, 2026Training and serving Large Language Models (LLMs) require partitioning data across multiple accelerators, where collective operations are frequently bottlenecked by network bandwidth. Lossless compression using Huffman codes is an effective way to alleviate the issue, however, its three-stage design requiring on-the-fly frequency analysis, codebook generation and transmission of codebook along with data introduces computational, latency and data overheads which are prohibitive for latency-sensitive scenarios such as die-to-die communication. This paper proposes a single-stage Huffman encoder that eliminates these overheads by using fixed codebooks derived from the average probability distribution of previous data batches. Through our analysis of the Gemma 2B model, we demonstrate that tensors exhibit high statistical similarity across layers and shards. Using this approach we achieve compression within 0.5% of per-shard Huffman coding and within 1% of the ideal Shannon compressibility, enabling efficient on-the-fly compression.
PoseBench3D: A Cross-Dataset Analysis Framework for 3D Human Pose Estimation
May 16, 2025Reliable three-dimensional human pose estimation is becoming increasingly important for real-world applications, yet much of prior work has focused solely on the performance within a single dataset. In practice, however, systems must adapt to diverse viewpoints, environments, and camera setups -- conditions that differ significantly from those encountered during training, which is often the case in real-world scenarios. To address these challenges, we present a standardized testing environment in which each method is evaluated on a variety of datasets, ensuring consistent and fair cross-dataset comparisons -- allowing for the analysis of methods on previously unseen data. Therefore, we propose PoseBench3D, a unified framework designed to systematically re-evaluate prior and future models across four of the most widely used datasets for human pose estimation -- with the framework able to support novel and future datasets as the field progresses. Through a unified interface, our framework provides datasets in a pre-configured yet easily modifiable format, ensuring compatibility with diverse model architectures. We re-evaluated the work of 18 methods, either trained or gathered from existing literature, and reported results using both Mean Per Joint Position Error (MPJPE) and Procrustes Aligned Mean Per Joint Position Error (PA-MPJPE) metrics, yielding more than 100 novel cross-dataset evaluation results. Additionally, we analyze performance differences resulting from various pre-processing techniques and dataset preparation parameters -- offering further insight into model generalization capabilities.
Latent Representation Matters: Human-like Sketches in One-shot Drawing Tasks
Jun 10, 2024Humans can effortlessly draw new categories from a single exemplar, a feat that has long posed a challenge for generative models. However, this gap has started to close with recent advances in diffusion models. This one-shot drawing task requires powerful inductive biases that have not been systematically investigated. Here, we study how different inductive biases shape the latent space of Latent Diffusion Models (LDMs). Along with standard LDM regularizers (KL and vector quantization), we explore supervised regularizations (including classification and prototype-based representation) and contrastive inductive biases (using SimCLR and redundancy reduction objectives). We demonstrate that LDMs with redundancy reduction and prototype-based regularizations produce near-human-like drawings (regarding both samples' recognizability and originality) -- better mimicking human perception (as evaluated psychophysically). Overall, our results suggest that the gap between humans and machines in one-shot drawings is almost closed.
eXmY: A Data Type and Technique for Arbitrary Bit Precision Quantization
May 22, 2024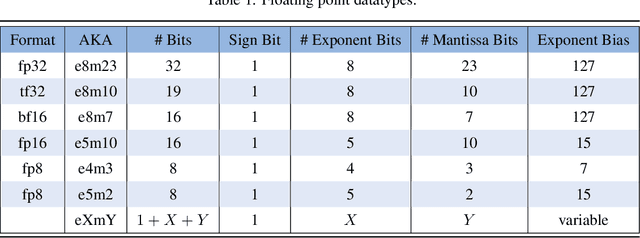
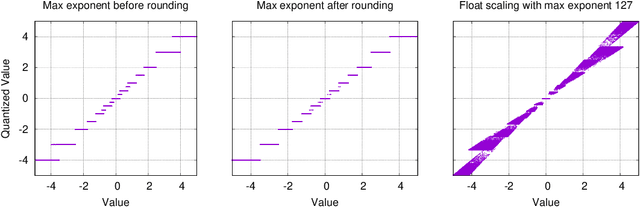
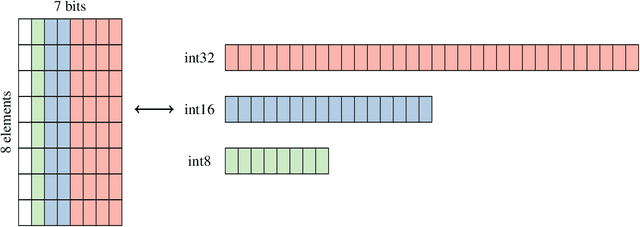

eXmY is a novel data type for quantization of ML models. It supports both arbitrary bit widths and arbitrary integer and floating point formats. For example, it seamlessly supports 3, 5, 6, 7, 9 bit formats. For a specific bit width, say 7, it defines all possible formats e.g. e0m6, e1m5, e2m4, e3m3, e4m2, e5m1 and e6m0. For non-power of two bit widths e.g. 5, 6, 7, we created a novel encoding and decoding scheme which achieves perfect compression, byte addressability and is amenable to sharding and vector processing. We implemented libraries for emulation, encoding and decoding tensors and checkpoints in C++, TensorFlow, JAX and PAX. For optimal performance, the codecs use SIMD instructions on CPUs and vector instructions on TPUs and GPUs. eXmY is also a technique and exploits the statistical distribution of exponents in tensors. It can be used to quantize weights, static and dynamic activations, gradients, master weights and optimizer state. It can reduce memory (CPU DRAM and accelerator HBM), network and disk storage and transfers. It can increase multi tenancy and accelerate compute. eXmY has been deployed in production for almost 2 years.
COVID-19 Vaccine Misinformation in Middle Income Countries
Nov 30, 2023



This paper introduces a multilingual dataset of COVID-19 vaccine misinformation, consisting of annotated tweets from three middle-income countries: Brazil, Indonesia, and Nigeria. The expertly curated dataset includes annotations for 5,952 tweets, assessing their relevance to COVID-19 vaccines, presence of misinformation, and the themes of the misinformation. To address challenges posed by domain specificity, the low-resource setting, and data imbalance, we adopt two approaches for developing COVID-19 vaccine misinformation detection models: domain-specific pre-training and text augmentation using a large language model. Our best misinformation detection models demonstrate improvements ranging from 2.7 to 15.9 percentage points in macro F1-score compared to the baseline models. Additionally, we apply our misinformation detection models in a large-scale study of 19 million unlabeled tweets from the three countries between 2020 and 2022, showcasing the practical application of our dataset and models for detecting and analyzing vaccine misinformation in multiple countries and languages. Our analysis indicates that percentage changes in the number of new COVID-19 cases are positively associated with COVID-19 vaccine misinformation rates in a staggered manner for Brazil and Indonesia, and there are significant positive associations between the misinformation rates across the three countries.
Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior
Sep 08, 2023



Shannon, in his seminal paper introducing information theory, divided the communication into three levels: technical, semantic, and effectivenss. While the technical level is concerned with accurate reconstruction of transmitted symbols, the semantic and effectiveness levels deal with the inferred meaning and its effect on the receiver. Thanks to telecommunications, the first level problem has produced great advances like the internet. Large Language Models (LLMs) make some progress towards the second goal, but the third level still remains largely untouched. The third problem deals with predicting and optimizing communication for desired receiver behavior. LLMs, while showing wide generalization capabilities across a wide range of tasks, are unable to solve for this. One reason for the underperformance could be a lack of "behavior tokens" in LLMs' training corpora. Behavior tokens define receiver behavior over a communication, such as shares, likes, clicks, purchases, retweets, etc. While preprocessing data for LLM training, behavior tokens are often removed from the corpora as noise. Therefore, in this paper, we make some initial progress towards reintroducing behavior tokens in LLM training. The trained models, other than showing similar performance to LLMs on content understanding tasks, show generalization capabilities on behavior simulation, content simulation, behavior understanding, and behavior domain adaptation. Using a wide range of tasks on two corpora, we show results on all these capabilities. We call these models Large Content and Behavior Models (LCBMs). Further, to spur more research on LCBMs, we release our new Content Behavior Corpus (CBC), a repository containing communicator, message, and corresponding receiver behavior.
Neural Feature-Adaptation for Symbolic Predictions Using Pre-Training and Semantic Loss
Nov 29, 2022



We are interested in neurosymbolic systems consisting of a high-level symbolic layer for explainable prediction in terms of human-intelligible concepts; and a low-level neural layer for extracting symbols required to generate the symbolic explanation. Real data is often imperfect meaning that even if the symbolic theory remains unchanged, we may still need to address the problem of mapping raw data to high-level symbols, each time there is a change in the data acquisition environment or equipment. Manual (re-)annotation of the raw data each time this happens is laborious and expensive; and automated labelling methods are often imperfect, especially for complex problems. NEUROLOG proposed the use of a semantic loss function that allows an existing feature-based symbolic model to guide the extraction of feature-values from raw data, using `abduction'. However, the experiments demonstrating the use of semantic loss through abduction appear to rely heavily on a domain-specific pre-processing step that enables a prior delineation of feature locations in the raw data. We examine the use of semantic loss in domains where such pre-processing is not possible, or is not obvious. We show that without any prior information about the features, the NEUROLOG approach can continue to predict accurately even with substantially incorrect feature predictions. We show also that prior information about the features in the form of even imperfect pre-training can help correct this situation. These findings are replicated on the original problem considered by NEUROLOG, without the use of feature-delineation. This suggests that symbolic explanations constructed for data in a domain could be re-used in a related domain, by `feature-adaptation' of pre-trained neural extractors using the semantic loss function constrained by abductive feedback.