 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Improving Persuasiveness of Generative Models
Oct 03, 2024



LLMs are increasingly being used in workflows involving generating content to be consumed by humans (e.g., marketing) and also in directly interacting with humans (e.g., through chatbots). The development of such systems that are capable of generating verifiably persuasive messages presents both opportunities and challenges for society. On the one hand, such systems could positively impact domains like advertising and social good, such as addressing drug addiction, and on the other, they could be misused for spreading misinformation and shaping political opinions. To channel LLMs' impact on society, we need to develop systems to measure and benchmark their persuasiveness. With this motivation, we introduce PersuasionBench and PersuasionArena, the first large-scale benchmark and arena containing a battery of tasks to measure the persuasion ability of generative models automatically. We investigate to what extent LLMs know and leverage linguistic patterns that can help them generate more persuasive language. Our findings indicate that the persuasiveness of LLMs correlates positively with model size, but smaller models can also be made to have a higher persuasiveness than much larger models. Notably, targeted training using synthetic and natural datasets significantly enhances smaller models' persuasive capabilities, challenging scale-dependent assumptions. Our findings carry key implications for both model developers and policymakers. For instance, while the EU AI Act and California's SB-1047 aim to regulate AI models based on the number of floating point operations, we demonstrate that simple metrics like this alone fail to capture the full scope of AI's societal impact. We invite the community to explore and contribute to PersuasionArena and PersuasionBench, available at https://bit.ly/measure-persuasion, to advance our understanding of AI-driven persuasion and its societal implications.
LLaVA Finds Free Lunch: Teaching Human Behavior Improves Content Understanding Abilities Of LLMs
May 02, 2024Communication is defined as ``Who says what to whom with what effect.'' A message from a communicator generates downstream receiver effects, also known as behavior. Receiver behavior, being a downstream effect of the message, carries rich signals about it. Even after carrying signals about the message, the behavior data is often ignored while training large language models. We show that training LLMs on receiver behavior can actually help improve their content-understanding abilities. Specifically, we show that training LLMs to predict the receiver behavior of likes and comments improves the LLM's performance on a wide variety of downstream content understanding tasks. We show this performance increase over 40 video and image understanding tasks over 23 benchmark datasets across both 0-shot and fine-tuning settings, outperforming many supervised baselines. Moreover, since receiver behavior, such as likes and comments, is collected by default on the internet and does not need any human annotations to be useful, the performance improvement we get after training on this data is essentially free-lunch. We release the receiver behavior cleaned comments and likes of 750k images and videos collected from multiple platforms along with our instruction-tuning data.
Behavior Optimized Image Generation
Nov 18, 2023



The last few years have witnessed great success on image generation, which has crossed the acceptance thresholds of aesthetics, making it directly applicable to personal and commercial applications. However, images, especially in marketing and advertising applications, are often created as a means to an end as opposed to just aesthetic concerns. The goal can be increasing sales, getting more clicks, likes, or image sales (in the case of stock businesses). Therefore, the generated images need to perform well on these key performance indicators (KPIs), in addition to being aesthetically good. In this paper, we make the first endeavor to answer the question of "How can one infuse the knowledge of the end-goal within the image generation process itself to create not just better-looking images but also "better-performing'' images?''. We propose BoigLLM, an LLM that understands both image content and user behavior. BoigLLM knows how an image should look to get a certain required KPI. We show that BoigLLM outperforms 13x larger models such as GPT-3.5 and GPT-4 in this task, demonstrating that while these state-of-the-art models can understand images, they lack information on how these images perform in the real world. To generate actual pixels of behavior-conditioned images, we train a diffusion-based model (BoigSD) to align with a proposed BoigLLM-defined reward. We show the performance of the overall pipeline on two datasets covering two different behaviors: a stock dataset with the number of forward actions as the KPI and a dataset containing tweets with the total likes as the KPI, denoted as BoigBench. To advance research in the direction of utility-driven image generation and understanding, we release BoigBench, a benchmark dataset containing 168 million enterprise tweets with their media, brand account names, time of post, and total likes.
Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior
Sep 08, 2023



Shannon, in his seminal paper introducing information theory, divided the communication into three levels: technical, semantic, and effectivenss. While the technical level is concerned with accurate reconstruction of transmitted symbols, the semantic and effectiveness levels deal with the inferred meaning and its effect on the receiver. Thanks to telecommunications, the first level problem has produced great advances like the internet. Large Language Models (LLMs) make some progress towards the second goal, but the third level still remains largely untouched. The third problem deals with predicting and optimizing communication for desired receiver behavior. LLMs, while showing wide generalization capabilities across a wide range of tasks, are unable to solve for this. One reason for the underperformance could be a lack of "behavior tokens" in LLMs' training corpora. Behavior tokens define receiver behavior over a communication, such as shares, likes, clicks, purchases, retweets, etc. While preprocessing data for LLM training, behavior tokens are often removed from the corpora as noise. Therefore, in this paper, we make some initial progress towards reintroducing behavior tokens in LLM training. The trained models, other than showing similar performance to LLMs on content understanding tasks, show generalization capabilities on behavior simulation, content simulation, behavior understanding, and behavior domain adaptation. Using a wide range of tasks on two corpora, we show results on all these capabilities. We call these models Large Content and Behavior Models (LCBMs). Further, to spur more research on LCBMs, we release our new Content Behavior Corpus (CBC), a repository containing communicator, message, and corresponding receiver behavior.
Long-Term Memorability On Advertisements
Sep 01, 2023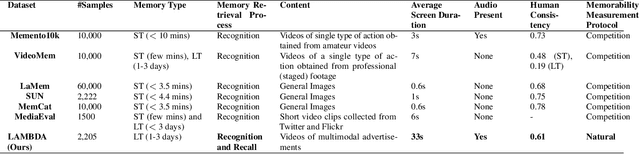
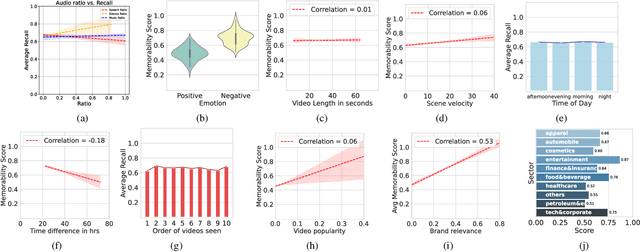
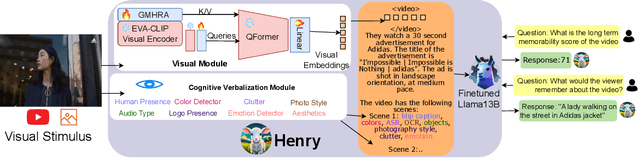

Marketers spend billions of dollars on advertisements but to what end? At the purchase time, if customers cannot recognize a brand for which they saw an ad, the money spent on the ad is essentially wasted. Despite its importance in marketing, until now, there has been no study on the memorability of ads in the ML literature. Most studies have been conducted on short-term recall (<5 mins) on specific content types like object and action videos. On the other hand, the advertising industry only cares about long-term memorability (a few hours or longer), and advertisements are almost always highly multimodal, depicting a story through its different modalities (text, images, and videos). With this motivation, we conduct the first large scale memorability study consisting of 1203 participants and 2205 ads covering 276 brands. Running statistical tests over different participant subpopulations and ad-types, we find many interesting insights into what makes an ad memorable - both content and human factors. For example, we find that brands which use commercials with fast moving scenes are more memorable than those with slower scenes (p=8e-10) and that people who use ad-blockers remember lower number of ads than those who don't (p=5e-3). Further, with the motivation of simulating the memorability of marketing materials for a particular audience, ultimately helping create one, we present a novel model, Sharingan, trained to leverage real-world knowledge of LLMs and visual knowledge of visual encoders to predict the memorability of a content. We test our model on all the prominent memorability datasets in literature (both images and videos) and achieve state of the art across all of them. We conduct extensive ablation studies across memory types, modality, brand, and architectural choices to find insights into what drives memory.
A Video Is Worth 4096 Tokens: Verbalize Story Videos To Understand Them In Zero Shot
May 23, 2023



Multimedia content, such as advertisements and story videos, exhibit a rich blend of creativity and multiple modalities. They incorporate elements like text, visuals, audio, and storytelling techniques, employing devices like emotions, symbolism, and slogans to convey meaning. While previous research in multimedia understanding has focused mainly on videos with specific actions like cooking, there is a dearth of large annotated training datasets, hindering the development of supervised learning models with satisfactory performance for real-world applications. However, the rise of large language models (LLMs) has witnessed remarkable zero-shot performance in various natural language processing (NLP) tasks, such as emotion classification, question-answering, and topic classification. To bridge this performance gap in multimedia understanding, we propose verbalizing story videos to generate their descriptions in natural language and then performing video-understanding tasks on the generated story as opposed to the original video. Through extensive experiments on five video-understanding tasks, we demonstrate that our method, despite being zero-shot, achieves significantly better results than supervised baselines for video understanding. Further, alleviating a lack of story understanding benchmarks, we publicly release the first dataset on a crucial task in computational social science, persuasion strategy identification.