 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA Finds Free Lunch: Teaching Human Behavior Improves Content Understanding Abilities Of LLMs
May 02, 2024Communication is defined as ``Who says what to whom with what effect.'' A message from a communicator generates downstream receiver effects, also known as behavior. Receiver behavior, being a downstream effect of the message, carries rich signals about it. Even after carrying signals about the message, the behavior data is often ignored while training large language models. We show that training LLMs on receiver behavior can actually help improve their content-understanding abilities. Specifically, we show that training LLMs to predict the receiver behavior of likes and comments improves the LLM's performance on a wide variety of downstream content understanding tasks. We show this performance increase over 40 video and image understanding tasks over 23 benchmark datasets across both 0-shot and fine-tuning settings, outperforming many supervised baselines. Moreover, since receiver behavior, such as likes and comments, is collected by default on the internet and does not need any human annotations to be useful, the performance improvement we get after training on this data is essentially free-lunch. We release the receiver behavior cleaned comments and likes of 750k images and videos collected from multiple platforms along with our instruction-tuning data.
Long-Term Memorability On Advertisements
Sep 01, 2023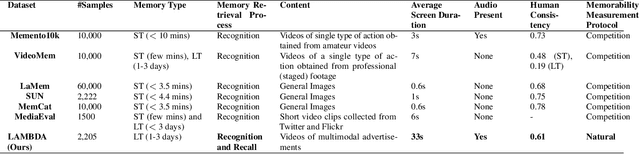
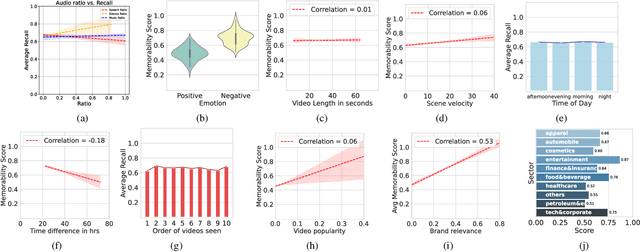
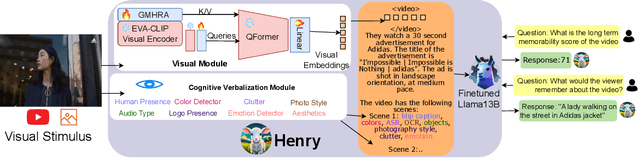

Marketers spend billions of dollars on advertisements but to what end? At the purchase time, if customers cannot recognize a brand for which they saw an ad, the money spent on the ad is essentially wasted. Despite its importance in marketing, until now, there has been no study on the memorability of ads in the ML literature. Most studies have been conducted on short-term recall (<5 mins) on specific content types like object and action videos. On the other hand, the advertising industry only cares about long-term memorability (a few hours or longer), and advertisements are almost always highly multimodal, depicting a story through its different modalities (text, images, and videos). With this motivation, we conduct the first large scale memorability study consisting of 1203 participants and 2205 ads covering 276 brands. Running statistical tests over different participant subpopulations and ad-types, we find many interesting insights into what makes an ad memorable - both content and human factors. For example, we find that brands which use commercials with fast moving scenes are more memorable than those with slower scenes (p=8e-10) and that people who use ad-blockers remember lower number of ads than those who don't (p=5e-3). Further, with the motivation of simulating the memorability of marketing materials for a particular audience, ultimately helping create one, we present a novel model, Sharingan, trained to leverage real-world knowledge of LLMs and visual knowledge of visual encoders to predict the memorability of a content. We test our model on all the prominent memorability datasets in literature (both images and videos) and achieve state of the art across all of them. We conduct extensive ablation studies across memory types, modality, brand, and architectural choices to find insights into what drives memory.