 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Causal Imputation via Synthetic Interventions
Oct 28, 2024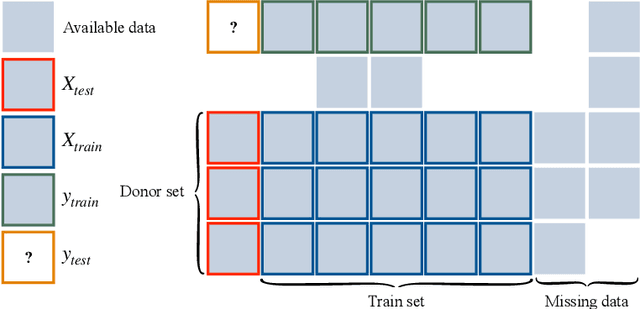
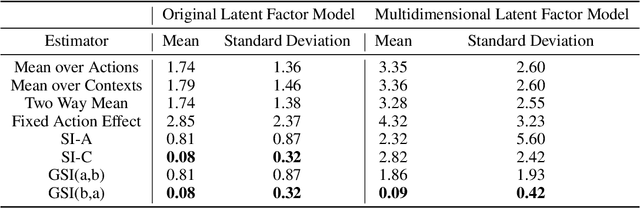
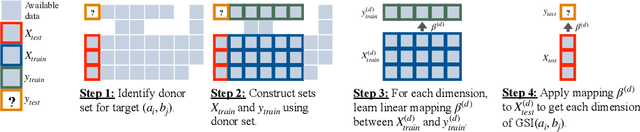
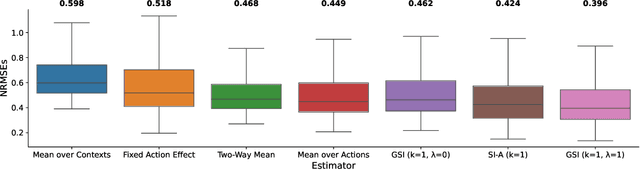
Given two sets of elements (such as cell types and drug compounds), researchers typically only have access to a limited subset of their interactions. The task of causal imputation involves using this subset to predict unobserved interactions. Squires et al. (2022) have proposed two estimators for this task based on the synthetic interventions (SI) estimator: SI-A (for actions) and SI-C (for contexts). We extend their work and introduce a novel causal imputation estimator, generalized synthetic interventions (GSI). We prove the identifiability of this estimator for data generated from a more complex latent factor model. On synthetic and real data we show empirically that it recovers or outperforms their estimators.
Expected flow networks in stochastic environments and two-player zero-sum games
Oct 04, 2023



Generative flow networks (GFlowNets) are sequential sampling models trained to match a given distribution. GFlowNets have been successfully applied to various structured object generation tasks, sampling a diverse set of high-reward objects quickly. We propose expected flow networks (EFlowNets), which extend GFlowNets to stochastic environments. We show that EFlowNets outperform other GFlowNet formulations in stochastic tasks such as protein design. We then extend the concept of EFlowNets to adversarial environments, proposing adversarial flow networks (AFlowNets) for two-player zero-sum games. We show that AFlowNets learn to find above 80% of optimal moves in Connect-4 via self-play and outperform AlphaZero in tournaments.
On the Stability of Iterative Retraining of Generative Models on their own Data
Oct 03, 2023


Deep generative models have made tremendous progress in modeling complex data, often exhibiting generation quality that surpasses a typical human's ability to discern the authenticity of samples. Undeniably, a key driver of this success is enabled by the massive amounts of web-scale data consumed by these models. Due to these models' striking performance and ease of availability, the web will inevitably be increasingly populated with synthetic content. Such a fact directly implies that future iterations of generative models must contend with the reality that their training is curated from both clean data and artificially generated data from past models. In this paper, we develop a framework to rigorously study the impact of training generative models on mixed datasets (of real and synthetic data) on their stability. We first prove the stability of iterative training under the condition that the initial generative models approximate the data distribution well enough and the proportion of clean training data (w.r.t. synthetic data) is large enough. We empirically validate our theory on both synthetic and natural images by iteratively training normalizing flows and state-of-the-art diffusion models on CIFAR10 and FFHQ.
AI4GCC -- Track 3: Consumption and the Challenges of Multi-Agent RL
Aug 09, 2023The AI4GCC competition presents a bold step forward in the direction of integrating machine learning with traditional economic policy analysis. Below, we highlight two potential areas for improvement that could enhance the competition's ability to identify and evaluate proposed negotiation protocols. Firstly, we suggest the inclusion of an additional index that accounts for consumption/utility as part of the evaluation criteria. Secondly, we recommend further investigation into the learning dynamics of agents in the simulator and the game theoretic properties of outcomes from proposed negotiation protocols. We hope that these suggestions can be of use for future iterations of the competition/simulation.
Feature Likelihood Score: Evaluating Generalization of Generative Models Using Samples
Feb 09, 2023


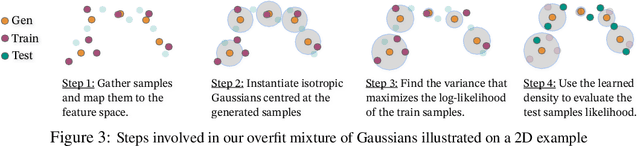
Deep generative models have demonstrated the ability to generate complex, high-dimensional, and photo-realistic data. However, a unified framework for evaluating different generative modeling families remains a challenge. Indeed, likelihood-based metrics do not apply in many cases while pure sample-based metrics such as FID fail to capture known failure modes such as overfitting on training data. In this work, we introduce the Feature Likelihood Score (FLS), a parametric sample-based score that uses density estimation to quantitatively measure the quality/diversity of generated samples while taking into account overfitting. We empirically demonstrate the ability of FLS to identify specific overfitting problem cases, even when previously proposed metrics fail. We further perform an extensive experimental evaluation on various image datasets and model classes. Our results indicate that FLS matches intuitions of previous metrics, such as FID, while providing a more holistic evaluation of generative models that highlights models whose generalization abilities are under or overappreciated. Code for computing FLS is provided at https://github.com/marcojira/fls
Proceedings of the ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
Jul 14, 2022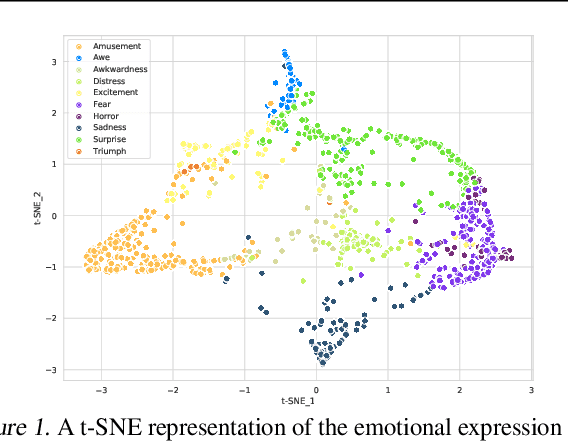
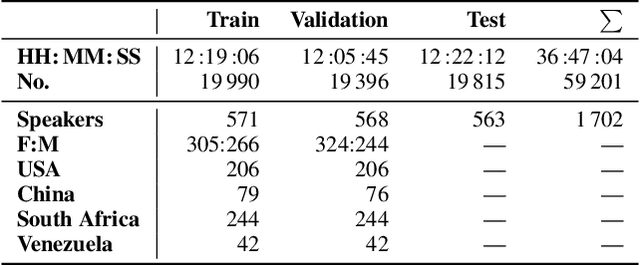
This is the Proceedings of the ICML Expressive Vocalization (ExVo) Competition. The ExVo competition focuses on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, included three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts.
Generating Diverse Vocal Bursts with StyleGAN2 and MEL-Spectrograms
Jun 25, 2022
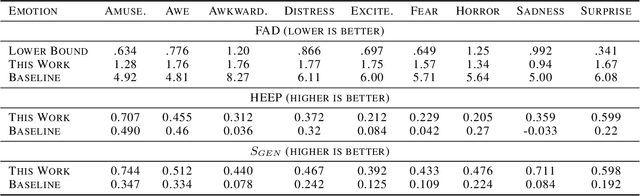

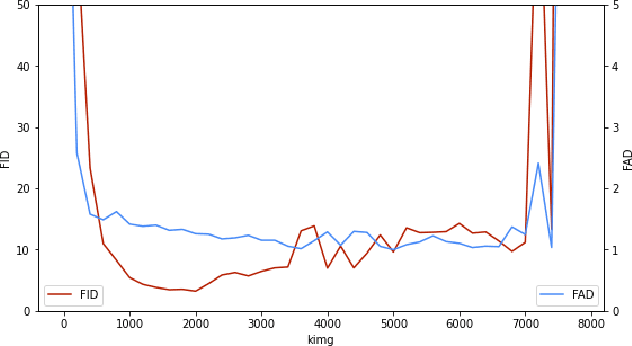
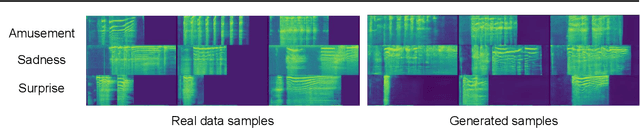
We describe our approach for the generative emotional vocal burst task (ExVo Generate) of the ICML Expressive Vocalizations Competition. We train a conditional StyleGAN2 architecture on mel-spectrograms of preprocessed versions of the audio samples. The mel-spectrograms generated by the model are then inverted back to the audio domain. As a result, our generated samples substantially improve upon the baseline provided by the competition from a qualitative and quantitative perspective for all emotions. More precisely, even for our worst-performing emotion (awe), we obtain an FAD of 1.76 compared to the baseline of 4.81 (as a reference, the FAD between the train/validation sets for awe is 0.776).
The ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
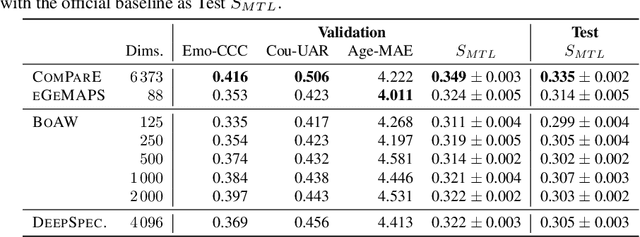
May 03, 2022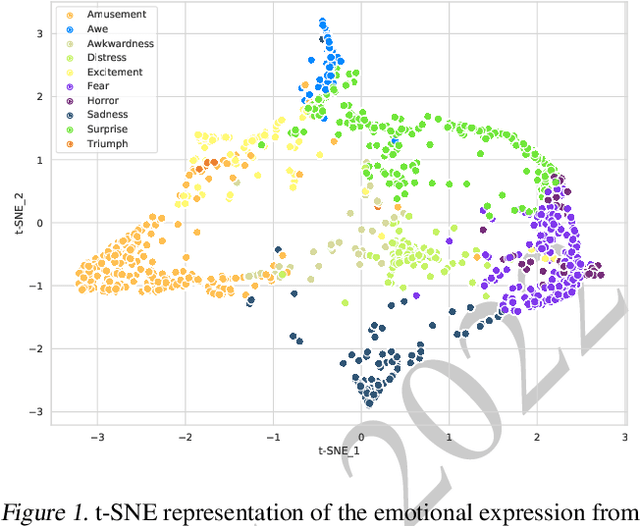
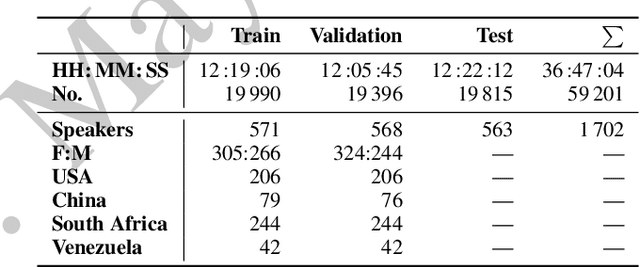
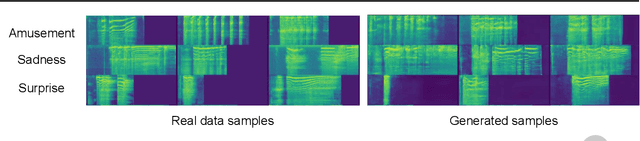
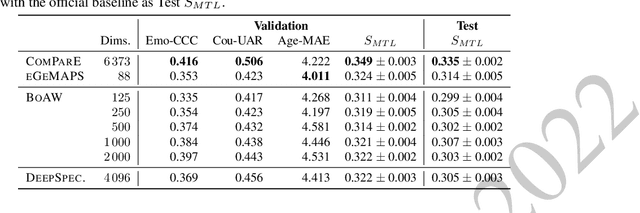
The ICML Expressive Vocalization (ExVo) Competition is focused on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, includes three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts. This paper describes the three tracks and provides performance measures for baseline models using state-of-the-art machine learning strategies. The baseline for each track is as follows, for ExVo-MultiTask, a combined score, computing the harmonic mean of Concordance Correlation Coefficient (CCC), Unweighted Average Recall (UAR), and inverted Mean Absolute Error (MAE) ($S_{MTL}$) is at best, 0.335 $S_{MTL}$; for ExVo-Generate, we report Fr\'echet inception distance (FID) scores ranging from 4.81 to 8.27 (depending on the emotion) between the training set and generated samples. We then combine the inverted FID with perceptual ratings of the generated samples ($S_{Gen}$) and obtain 0.174 $S_{Gen}$; and for ExVo-FewShot, a mean CCC of 0.444 is obtained.