Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Diverse Vocal Bursts with StyleGAN2 and MEL-Spectrograms
Paper and Code

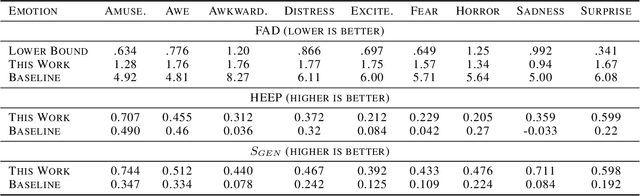

We describe our approach for the generative emotional vocal burst task (ExVo Generate) of the ICML Expressive Vocalizations Competition. We train a conditional StyleGAN2 architecture on mel-spectrograms of preprocessed versions of the audio samples. The mel-spectrograms generated by the model are then inverted back to the audio domain. As a result, our generated samples substantially improve upon the baseline provided by the competition from a qualitative and quantitative perspective for all emotions. More precisely, even for our worst-performing emotion (awe), we obtain an FAD of 1.76 compared to the baseline of 4.81 (as a reference, the FAD between the train/validation sets for awe is 0.776).
* To be published at the ICML Expressive Vocalizations Workshop and
Competition (ExVo Generate) held in conjunction with the 39th International
Conference on Machine Learning
View paper on