 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings of the ACII Affective Vocal Bursts Workshop and Competition 2022 (A-VB): Understanding a critically understudied modality of emotional expression
Oct 27, 2022This is the Proceedings of the ACII Affective Vocal Bursts Workshop and Competition (A-VB). A-VB was a workshop-based challenge that introduces the problem of understanding emotional expression in vocal bursts -- a wide range of non-verbal vocalizations that includes laughs, grunts, gasps, and much more. With affective states informing both mental and physical wellbeing, the core focus of the A-VB workshop was the broader discussion of current strategies in affective computing for modeling vocal emotional expression. Within this first iteration of the A-VB challenge, the participants were presented with four emotion-focused sub-challenges that utilize the large-scale and `in-the-wild' Hume-VB dataset. The dataset and the four sub-challenges draw attention to new innovations in emotion science as it pertains to vocal expression, addressing low- and high-dimensional theories of emotional expression, cultural variation, and `call types' (laugh, cry, sigh, etc.).
Proceedings of the ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
Jul 14, 2022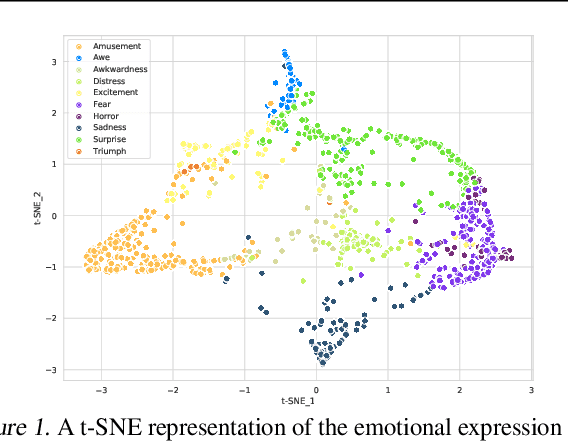
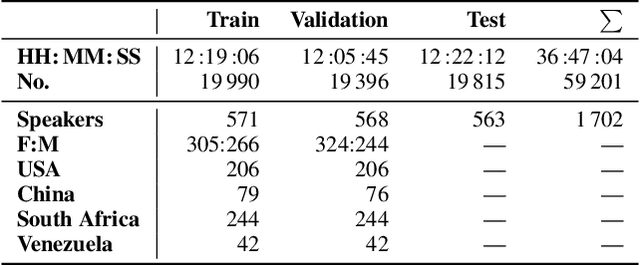
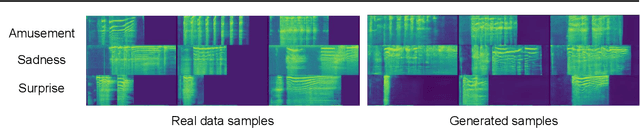
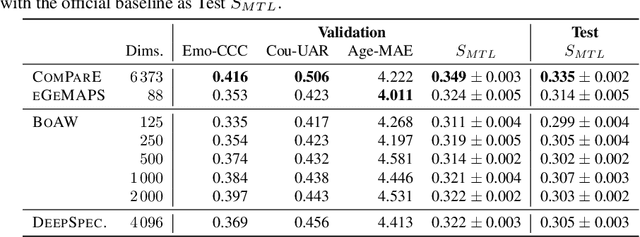
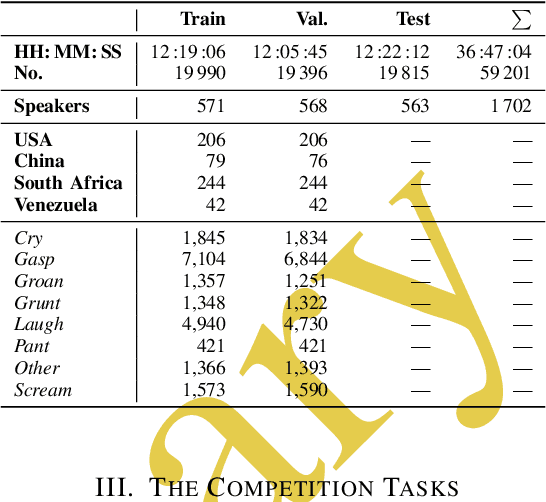
This is the Proceedings of the ICML Expressive Vocalization (ExVo) Competition. The ExVo competition focuses on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, included three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts.
The ACII 2022 Affective Vocal Bursts Workshop & Competition: Understanding a critically understudied modality of emotional expression
Jul 07, 2022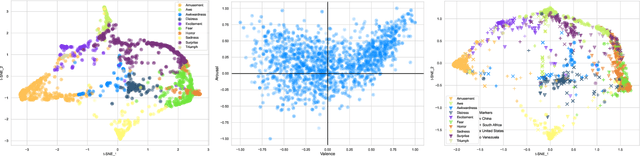
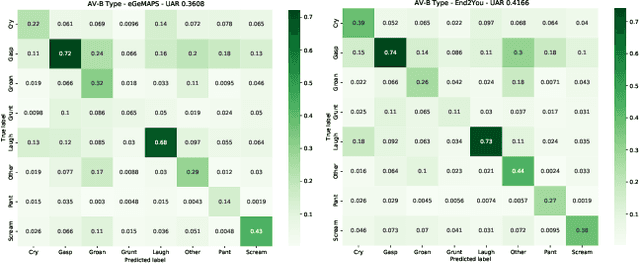
The ACII Affective Vocal Bursts Workshop & Competition is focused on understanding multiple affective dimensions of vocal bursts: laughs, gasps, cries, screams, and many other non-linguistic vocalizations central to the expression of emotion and to human communication more generally. This year's competition comprises four tracks using a large-scale and in-the-wild dataset of 59,299 vocalizations from 1,702 speakers. The first, the A-VB-High task, requires competition participants to perform a multi-label regression on a novel model for emotion, utilizing ten classes of richly annotated emotional expression intensities, including; Awe, Fear, and Surprise. The second, the A-VB-Two task, utilizes the more conventional 2-dimensional model for emotion, arousal, and valence. The third, the A-VB-Culture task, requires participants to explore the cultural aspects of the dataset, training native-country dependent models. Finally, for the fourth task, A-VB-Type, participants should recognize the type of vocal burst (e.g., laughter, cry, grunt) as an 8-class classification. This paper describes the four tracks and baseline systems, which use state-of-the-art machine learning methods. The baseline performance for each track is obtained by utilizing an end-to-end deep learning model and is as follows: for A-VB-High, a mean (over the 10-dimensions) Concordance Correlation Coefficient (CCC) of 0.5687 CCC is obtained; for A-VB-Two, a mean (over the 2-dimensions) CCC of 0.5084 is obtained; for A-VB-Culture, a mean CCC from the four cultures of 0.4401 is obtained; and for A-VB-Type, the baseline Unweighted Average Recall (UAR) from the 8-classes is 0.4172 UAR.
The ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
May 03, 2022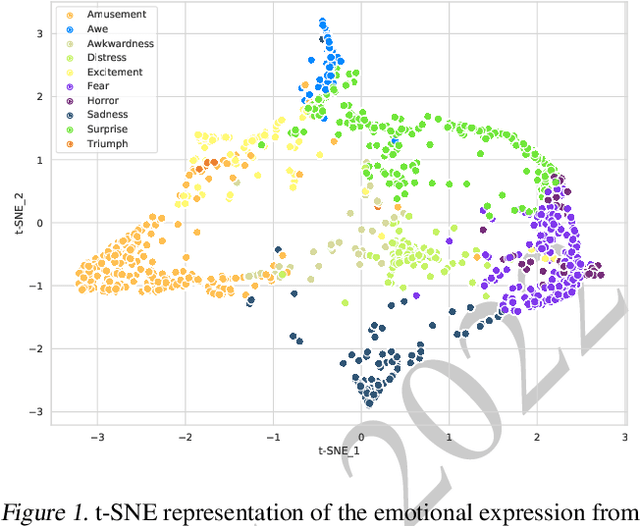
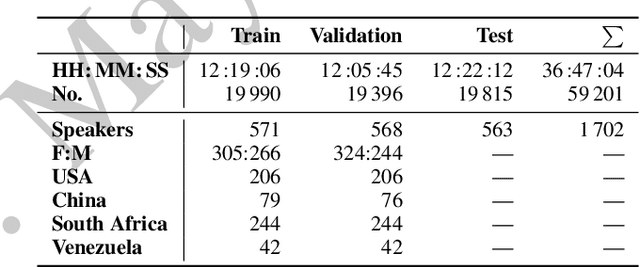
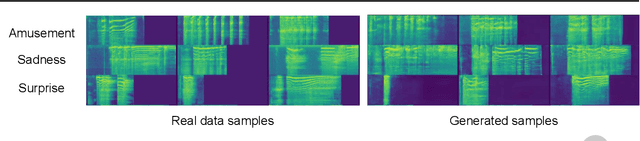
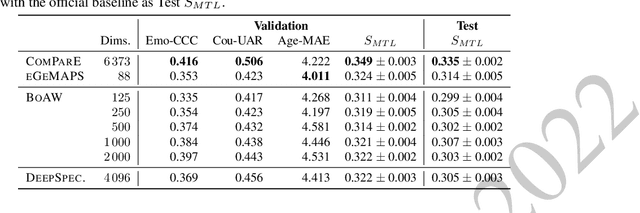
The ICML Expressive Vocalization (ExVo) Competition is focused on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, includes three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts. This paper describes the three tracks and provides performance measures for baseline models using state-of-the-art machine learning strategies. The baseline for each track is as follows, for ExVo-MultiTask, a combined score, computing the harmonic mean of Concordance Correlation Coefficient (CCC), Unweighted Average Recall (UAR), and inverted Mean Absolute Error (MAE) ($S_{MTL}$) is at best, 0.335 $S_{MTL}$; for ExVo-Generate, we report Fr\'echet inception distance (FID) scores ranging from 4.81 to 8.27 (depending on the emotion) between the training set and generated samples. We then combine the inverted FID with perceptual ratings of the generated samples ($S_{Gen}$) and obtain 0.174 $S_{Gen}$; and for ExVo-FewShot, a mean CCC of 0.444 is obtained.