 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacroGuide: Topological Guidance for Macrocycle Generation
Feb 16, 2026Macrocycles are ring-shaped molecules that offer a promising alternative to small-molecule drugs due to their enhanced selectivity and binding affinity against difficult targets. Despite their chemical value, they remain underexplored in generative modeling, likely owing to their scarcity in public datasets and the challenges of enforcing topological constraints in standard deep generative models. We introduce MacroGuide: Topological Guidance for Macrocycle Generation, a diffusion guidance mechanism that uses Persistent Homology to steer the sampling of pretrained molecular generative models toward the generation of macrocycles, in both unconditional and conditional (protein pocket) settings. At each denoising step, MacroGuide constructs a Vietoris-Rips complex from atomic positions and promotes ring formation by optimizing persistent homology features. Empirically, applying MacroGuide to pretrained diffusion models increases macrocycle generation rates from 1% to 99%, while matching or exceeding state-of-the-art performance on key quality metrics such as chemical validity, diversity, and PoseBusters checks.
Unlearning-based Neural Interpretations
Oct 10, 2024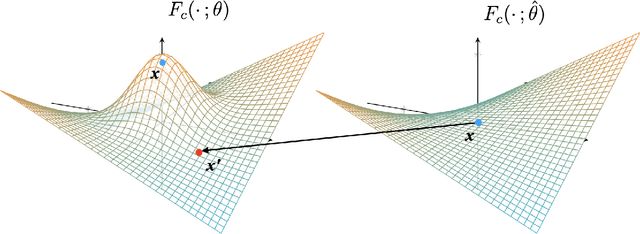
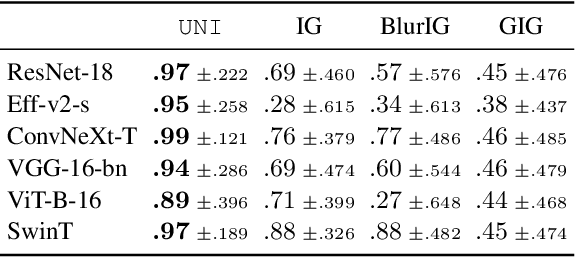
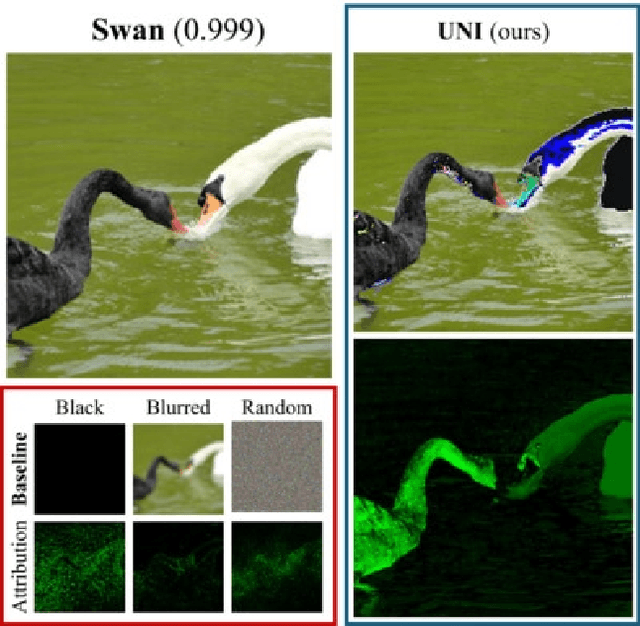
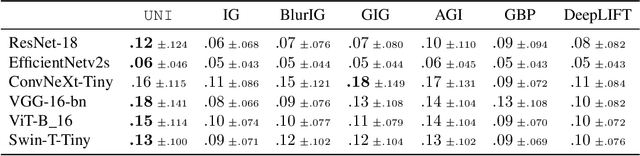
Gradient-based interpretations often require an anchor point of comparison to avoid saturation in computing feature importance. We show that current baselines defined using static functions--constant mapping, averaging or blurring--inject harmful colour, texture or frequency assumptions that deviate from model behaviour. This leads to accumulation of irregular gradients, resulting in attribution maps that are biased, fragile and manipulable. Departing from the static approach, we propose UNI to compute an (un)learnable, debiased and adaptive baseline by perturbing the input towards an unlearning direction of steepest ascent. Our method discovers reliable baselines and succeeds in erasing salient features, which in turn locally smooths the high-curvature decision boundaries. Our analyses point to unlearning as a promising avenue for generating faithful, efficient and robust interpretations.
On the Stability of Iterative Retraining of Generative Models on their own Data
Oct 03, 2023


Deep generative models have made tremendous progress in modeling complex data, often exhibiting generation quality that surpasses a typical human's ability to discern the authenticity of samples. Undeniably, a key driver of this success is enabled by the massive amounts of web-scale data consumed by these models. Due to these models' striking performance and ease of availability, the web will inevitably be increasingly populated with synthetic content. Such a fact directly implies that future iterations of generative models must contend with the reality that their training is curated from both clean data and artificially generated data from past models. In this paper, we develop a framework to rigorously study the impact of training generative models on mixed datasets (of real and synthetic data) on their stability. We first prove the stability of iterative training under the condition that the initial generative models approximate the data distribution well enough and the proportion of clean training data (w.r.t. synthetic data) is large enough. We empirically validate our theory on both synthetic and natural images by iteratively training normalizing flows and state-of-the-art diffusion models on CIFAR10 and FFHQ.
Tackling Computational Heterogeneity in FL: A Few Theoretical Insights
Jul 12, 2023



The future of machine learning lies in moving data collection along with training to the edge. Federated Learning, for short FL, has been recently proposed to achieve this goal. The principle of this approach is to aggregate models learned over a large number of distributed clients, i.e., resource-constrained mobile devices that collect data from their environment, to obtain a new more general model. The latter is subsequently redistributed to clients for further training. A key feature that distinguishes federated learning from data-center-based distributed training is the inherent heterogeneity. In this work, we introduce and analyse a novel aggregation framework that allows for formalizing and tackling computational heterogeneity in federated optimization, in terms of both heterogeneous data and local updates. Proposed aggregation algorithms are extensively analyzed from a theoretical, and an experimental prospective.
Adversarial Path Planning for Optimal Camera Positioning
Feb 26, 2023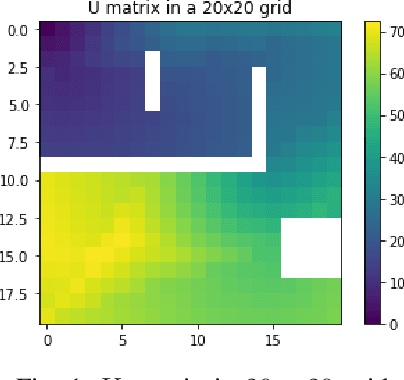

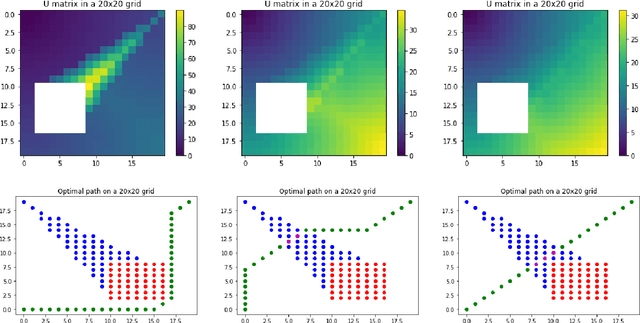

The use of visual sensors is flourishing, driven among others by the several applications in detection and prevention of crimes or dangerous events. While the problem of optimal camera placement for total coverage has been solved for a decade or so, that of the arrangement of cameras maximizing the recognition of objects "in-transit" is still open. The objective of this paper is to attack this problem by providing an adversarial method of proven optimality based on the resolution of Hamilton-Jacobi equations. The problem is attacked by first assuming the perspective of an adversary, i.e. computing explicitly the path minimizing the probability of detection and the quality of reconstruction. Building on this result, we introduce an optimality measure for camera configurations and perform a simulated annealing algorithm to find the optimal camera placement.
FedControl: When Control Theory Meets Federated Learning
May 27, 2022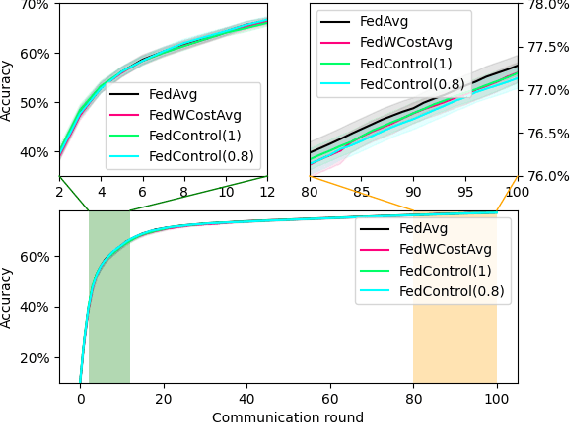
To date, the most popular federated learning algorithms use coordinate-wise averaging of the model parameters. We depart from this approach by differentiating client contributions according to the performance of local learning and its evolution. The technique is inspired from control theory and its classification performance is evaluated extensively in IID framework and compared with FedAvg.
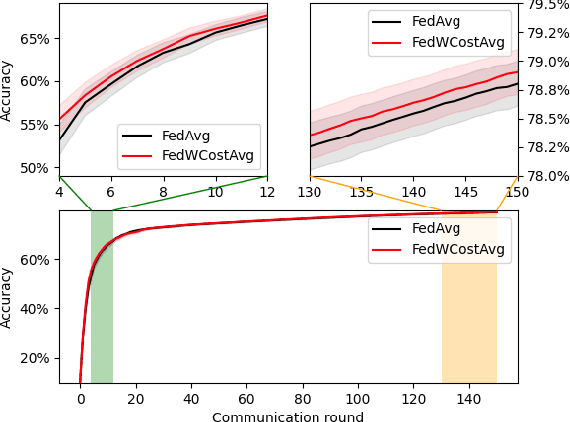
Federated Learning Aggregation: New Robust Algorithms with Guarantees
May 22, 2022

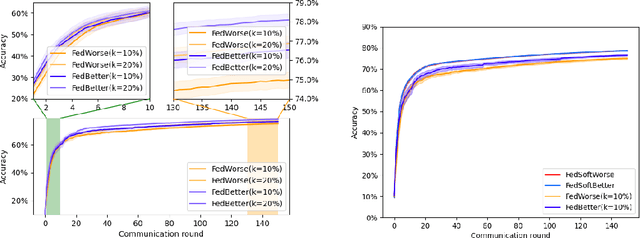
Federated Learning has been recently proposed for distributed model training at the edge. The principle of this approach is to aggregate models learned on distributed clients to obtain a new more general "average" model (FedAvg). The resulting model is then redistributed to clients for further training. To date, the most popular federated learning algorithm uses coordinate-wise averaging of the model parameters for aggregation. In this paper, we carry out a complete general mathematical convergence analysis to evaluate aggregation strategies in a federated learning framework. From this, we derive novel aggregation algorithms which are able to modify their model architecture by differentiating client contributions according to the value of their losses. Moreover, we go beyond the assumptions introduced in theory, by evaluating the performance of these strategies and by comparing them with the one of FedAvg in classification tasks in both the IID and the Non-IID framework without additional hypothesis.