 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Aware Reward Optimization
Feb 08, 2026Demographic skews in human preference data propagate systematic unfairness through reward models into aligned LLMs. We introduce Fairness Aware Reward Optimization (Faro), an in-processing framework that trains reward models under demographic parity, equalized odds, or counterfactual fairness constraints. We provide the first theoretical analysis of reward-level fairness in LLM alignment, establishing: (i) provable fairness certificates for Faro-trained rewards with controllable slack; a (ii) formal characterization of the accuracy-fairness trade-off induced by KL-regularized fine-tuning, proving fairness transfers from reward to policy; and the (iii) existence of a non-empty Pareto frontier. Unlike pre- and post-processing methods, Faro ensures reward models are simultaneously ordinal (ranking correctly), cardinal (calibrated), and fair. Across multiple LLMs and benchmarks, Faro significantly reduces bias and harmful generations while maintaining or improving model quality.
Unlearning-based Neural Interpretations
Oct 10, 2024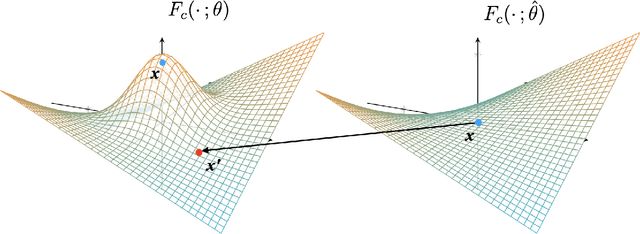
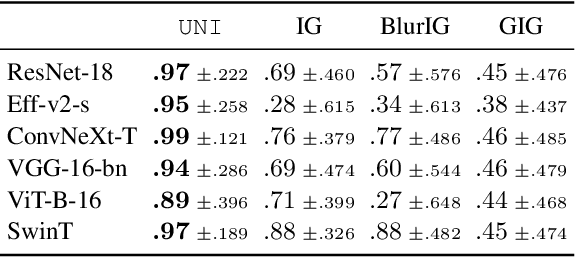
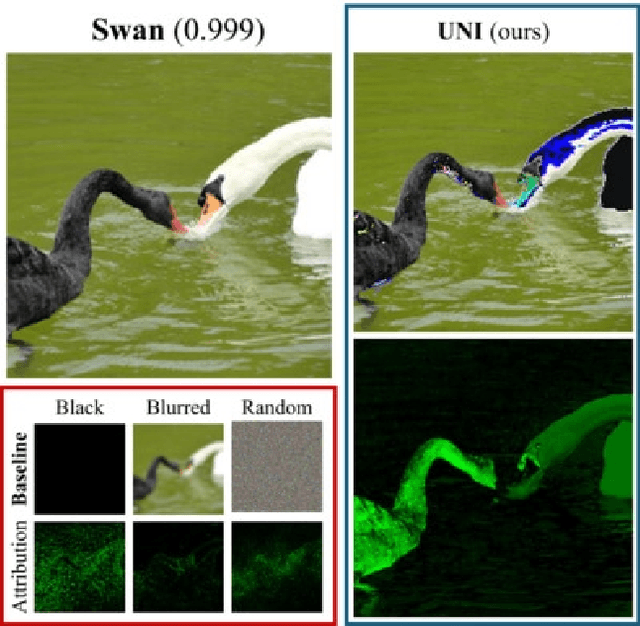
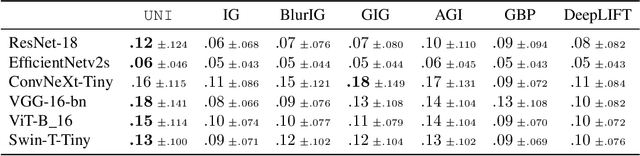
Gradient-based interpretations often require an anchor point of comparison to avoid saturation in computing feature importance. We show that current baselines defined using static functions--constant mapping, averaging or blurring--inject harmful colour, texture or frequency assumptions that deviate from model behaviour. This leads to accumulation of irregular gradients, resulting in attribution maps that are biased, fragile and manipulable. Departing from the static approach, we propose UNI to compute an (un)learnable, debiased and adaptive baseline by perturbing the input towards an unlearning direction of steepest ascent. Our method discovers reliable baselines and succeeds in erasing salient features, which in turn locally smooths the high-curvature decision boundaries. Our analyses point to unlearning as a promising avenue for generating faithful, efficient and robust interpretations.
Universal Adversarial Directions
Oct 28, 2022Despite their great success in image recognition tasks, deep neural networks (DNNs) have been observed to be susceptible to universal adversarial perturbations (UAPs) which perturb all input samples with a single perturbation vector. However, UAPs often struggle in transferring across DNN architectures and lead to challenging optimization problems. In this work, we study the transferability of UAPs by analyzing equilibrium in the universal adversarial example game between the classifier and UAP adversary players. We show that under mild assumptions the universal adversarial example game lacks a pure Nash equilibrium, indicating UAPs' suboptimal transferability across DNN classifiers. To address this issue, we propose Universal Adversarial Directions (UADs) which only fix a universal direction for adversarial perturbations and allow the perturbations' magnitude to be chosen freely across samples. We prove that the UAD adversarial example game can possess a Nash equilibrium with a pure UAD strategy, implying the potential transferability of UADs. We also connect the UAD optimization problem to the well-known principal component analysis (PCA) and develop an efficient PCA-based algorithm for optimizing UADs. We evaluate UADs over multiple benchmark image datasets. Our numerical results show the superior transferability of UADs over standard gradient-based UAPs.
Self-distillation with Batch Knowledge Ensembling Improves ImageNet Classification
Apr 27, 2021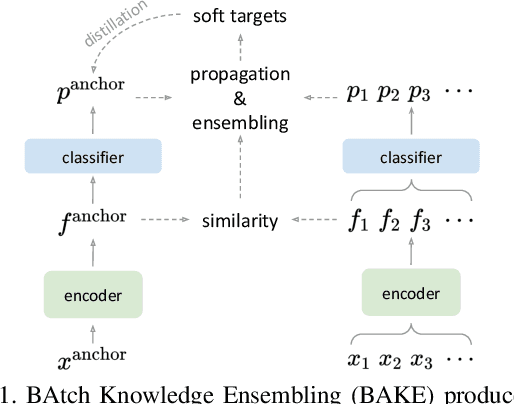

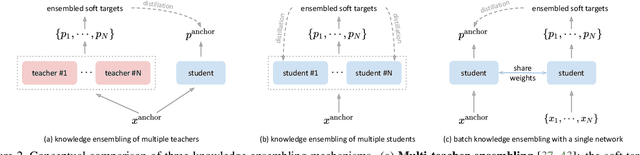
The recent studies of knowledge distillation have discovered that ensembling the "dark knowledge" from multiple teachers or students contributes to creating better soft targets for training, but at the cost of significantly more computations and/or parameters. In this work, we present BAtch Knowledge Ensembling (BAKE) to produce refined soft targets for anchor images by propagating and ensembling the knowledge of the other samples in the same mini-batch. Specifically, for each sample of interest, the propagation of knowledge is weighted in accordance with the inter-sample affinities, which are estimated on-the-fly with the current network. The propagated knowledge can then be ensembled to form a better soft target for distillation. In this way, our BAKE framework achieves online knowledge ensembling across multiple samples with only a single network. It requires minimal computational and memory overhead compared to existing knowledge ensembling methods. Extensive experiments demonstrate that the lightweight yet effective BAKE consistently boosts the classification performance of various architectures on multiple datasets, e.g., a significant +1.2% gain of ResNet-50 on ImageNet with only +3.7% computational overhead and zero additional parameters. BAKE does not only improve the vanilla baselines, but also surpasses the single-network state-of-the-arts on all the benchmarks.
DivCo: Diverse Conditional Image Synthesis via Contrastive Generative Adversarial Network
Mar 14, 2021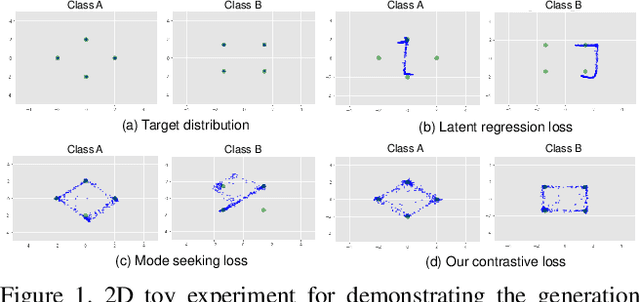
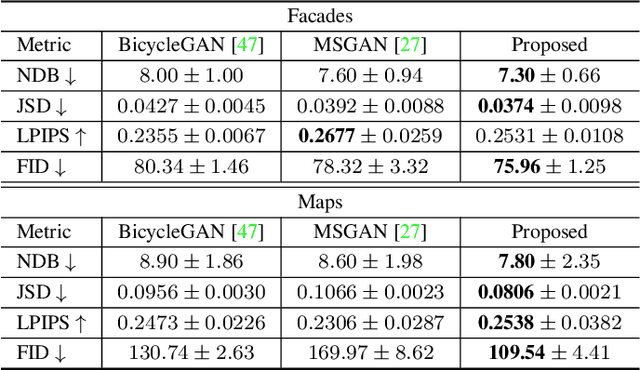
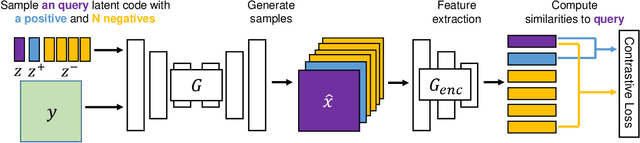
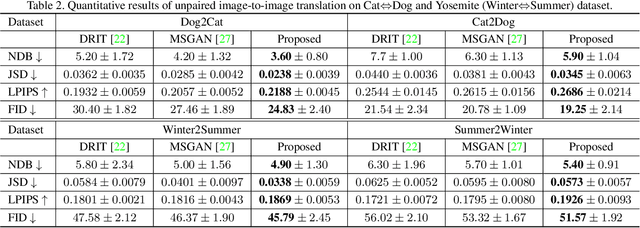
Conditional generative adversarial networks (cGANs) target at synthesizing diverse images given the input conditions and latent codes, but unfortunately, they usually suffer from the issue of mode collapse. To solve this issue, previous works mainly focused on encouraging the correlation between the latent codes and their generated images, while ignoring the relations between images generated from various latent codes. The recent MSGAN tried to encourage the diversity of the generated image but only considers "negative" relations between the image pairs. In this paper, we propose a novel DivCo framework to properly constrain both "positive" and "negative" relations between the generated images specified in the latent space. To the best of our knowledge, this is the first attempt to use contrastive learning for diverse conditional image synthesis. A novel latent-augmented contrastive loss is introduced, which encourages images generated from adjacent latent codes to be similar and those generated from distinct latent codes to be dissimilar. The proposed latent-augmented contrastive loss is well compatible with various cGAN architectures. Extensive experiments demonstrate that the proposed DivCo can produce more diverse images than state-of-the-art methods without sacrificing visual quality in multiple unpaired and paired image generation tasks.