 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-distillation with Batch Knowledge Ensembling Improves ImageNet Classification
Paper and Code
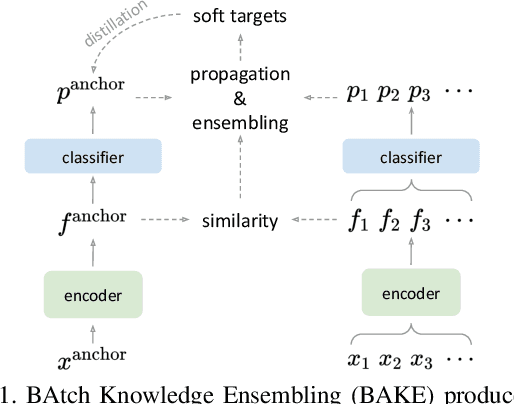

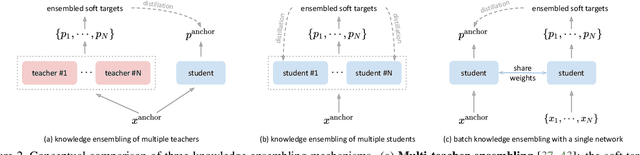
The recent studies of knowledge distillation have discovered that ensembling the "dark knowledge" from multiple teachers or students contributes to creating better soft targets for training, but at the cost of significantly more computations and/or parameters. In this work, we present BAtch Knowledge Ensembling (BAKE) to produce refined soft targets for anchor images by propagating and ensembling the knowledge of the other samples in the same mini-batch. Specifically, for each sample of interest, the propagation of knowledge is weighted in accordance with the inter-sample affinities, which are estimated on-the-fly with the current network. The propagated knowledge can then be ensembled to form a better soft target for distillation. In this way, our BAKE framework achieves online knowledge ensembling across multiple samples with only a single network. It requires minimal computational and memory overhead compared to existing knowledge ensembling methods. Extensive experiments demonstrate that the lightweight yet effective BAKE consistently boosts the classification performance of various architectures on multiple datasets, e.g., a significant +1.2% gain of ResNet-50 on ImageNet with only +3.7% computational overhead and zero additional parameters. BAKE does not only improve the vanilla baselines, but also surpasses the single-network state-of-the-arts on all the benchmarks.