 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPID: An Aggregation Method for Federated Learning
Nov 04, 2024This paper presents FedPID, our submission to the Federated Tumor Segmentation Challenge 2024 (FETS24). Inspired by FedCostWAvg and FedPIDAvg, our winning contributions to FETS21 and FETS2022, we propose an improved aggregation strategy for federated and collaborative learning. FedCostWAvg is a method that averages results by considering both the number of training samples in each group and how much the cost function decreased in the last round of training. This is similar to how the derivative part of a PID controller works. In FedPIDAvg, we also included the integral part that was missing. Another challenge we faced were vastly differing dataset sizes at each center. We solved this by assuming the sizes follow a Poisson distribution and adjusting the training iterations for each center accordingly. Essentially, this part of the method controls that outliers that require too much training time are less frequently used. Based on these contributions we now adapted FedPIDAvg by changing how the integral part is computed. Instead of integrating the loss function we measure the global drop in cost since the first round.
CNN Explainability with Multivector Tucker Saliency Maps for Self-Supervised Models
Oct 30, 2024Interpreting the decisions of Convolutional Neural Networks (CNNs) is essential for understanding their behavior, yet explainability remains a significant challenge, particularly for self-supervised models. Most existing methods for generating saliency maps rely on ground truth labels, restricting their use to supervised tasks. EigenCAM is the only notable label-independent alternative, leveraging Singular Value Decomposition to generate saliency maps applicable across CNN models, but it does not fully exploit the tensorial structure of feature maps. In this work, we introduce the Tucker Saliency Map (TSM) method, which applies Tucker tensor decomposition to better capture the inherent structure of feature maps, producing more accurate singular vectors and values. These are used to generate high-fidelity saliency maps, effectively highlighting objects of interest in the input. We further extend EigenCAM and TSM into multivector variants -Multivec-EigenCAM and Multivector Tucker Saliency Maps (MTSM)- which utilize all singular vectors and values, further improving saliency map quality. Quantitative evaluations on supervised classification models demonstrate that TSM, Multivec-EigenCAM, and MTSM achieve competitive performance with label-dependent methods. Moreover, TSM enhances explainability by approximately 50% over EigenCAM for both supervised and self-supervised models. Multivec-EigenCAM and MTSM further advance state-of-the-art explainability performance on self-supervised models, with MTSM achieving the best results.
Sampling From Autoencoders' Latent Space via Quantization And Probability Mass Function Concepts
Aug 21, 2023In this study, we focus on sampling from the latent space of generative models built upon autoencoders so as the reconstructed samples are lifelike images. To do to, we introduce a novel post-training sampling algorithm rooted in the concept of probability mass functions, coupled with a quantization process. Our proposed algorithm establishes a vicinity around each latent vector from the input data and then proceeds to draw samples from these defined neighborhoods. This strategic approach ensures that the sampled latent vectors predominantly inhabit high-probability regions, which, in turn, can be effectively transformed into authentic real-world images. A noteworthy point of comparison for our sampling algorithm is the sampling technique based on Gaussian mixture models (GMM), owing to its inherent capability to represent clusters. Remarkably, we manage to improve the time complexity from the previous $\mathcal{O}(n\times d \times k \times i)$ associated with GMM sampling to a much more streamlined $\mathcal{O}(n\times d)$, thereby resulting in substantial speedup during runtime. Moreover, our experimental results, gauged through the Fr\'echet inception distance (FID) for image generation, underscore the superior performance of our sampling algorithm across a diverse range of models and datasets. On the MNIST benchmark dataset, our approach outperforms GMM sampling by yielding a noteworthy improvement of up to $0.89$ in FID value. Furthermore, when it comes to generating images of faces and ocular images, our approach showcases substantial enhancements with FID improvements of $1.69$ and $0.87$ respectively, as compared to GMM sampling, as evidenced on the CelebA and MOBIUS datasets. Lastly, we substantiate our methodology's efficacy in estimating latent space distributions in contrast to GMM sampling, particularly through the lens of the Wasserstein distance.
Simplex Autoencoders
Jan 16, 2023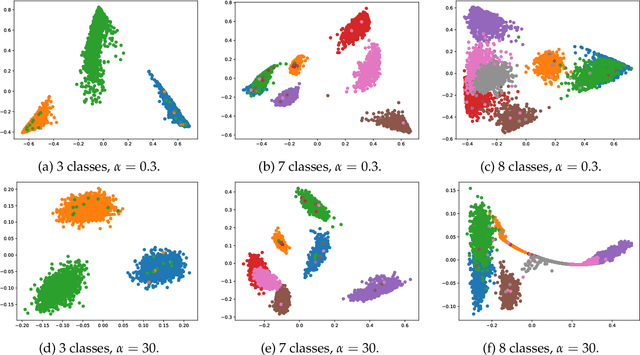
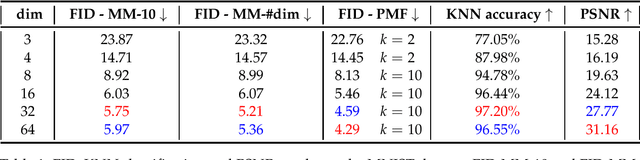
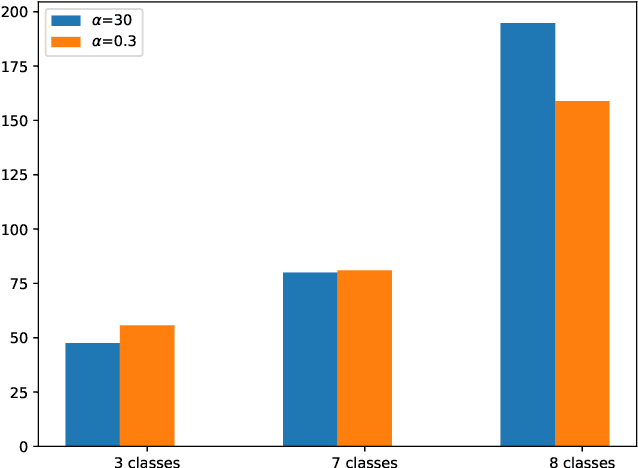
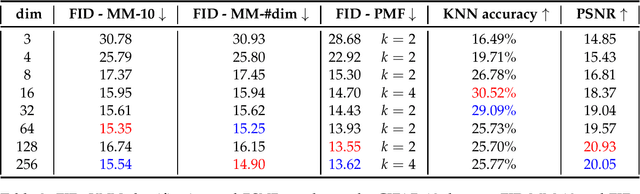
Synthetic data generation is increasingly important due to privacy concerns. While Autoencoder-based approaches have been widely used for this purpose, sampling from their latent spaces can be challenging. Mixture models are currently the most efficient way to sample from these spaces. In this work, we propose a new approach that models the latent space of an Autoencoder as a simplex, allowing for a novel heuristic for determining the number of components in the mixture model. This heuristic is independent of the number of classes and produces comparable results. We also introduce a sampling method based on probability mass functions, taking advantage of the compactness of the latent space. We evaluate our approaches on a synthetic dataset and demonstrate their performance on three benchmark datasets: MNIST, CIFAR-10, and Celeba. Our approach achieves an image generation FID of 4.29, 13.55, and 11.90 on the MNIST, CIFAR-10, and Celeba datasets, respectively. The best AE FID results to date on those datasets are respectively 6.3, 85.3 and 35.6 we hence substantially improve those figures (the lower is the FID the better). However, AEs are not the best performing algorithms on the concerned datasets and all FID records are currently held by GANs. While we do not perform better than GANs on CIFAR and Celeba we do manage to squeeze-out a non-negligible improvement (of 0.21) over the current GAN-held record for the MNIST dataset.
Pattern Recognition Experiments on Mathematical Expressions
Dec 21, 2022



We provide the results of pattern recognition experiments on mathematical expressions. We give a few examples of conjectured results. None of which was thoroughly checked for novelty. We did not attempt to prove all the relations found and focused on their generation.
A forensic analysis of the Google Home: repairing compressed data without error correction
Sep 30, 2022



This paper provides a detailed explanation of the steps taken to extract and repair a Google Home's internal data. Starting with reverse engineering the hardware of a commercial off-the-shelf Google Home, internal data is then extracted by desoldering and dumping the flash memory. As error correction is performed by the CPU using an undisclosed method, a new alternative method is shown to repair a corrupted SquashFS filesystem, under the assumption of a single or double bitflip per gzip-compressed fragment. Finally, a new method to handle multiple possible repairs using three-valued logic is presented.
* 28 pages, modified version of paper that appeared originally at Forensic Science International: Digital Investigation
FedControl: When Control Theory Meets Federated Learning
May 27, 2022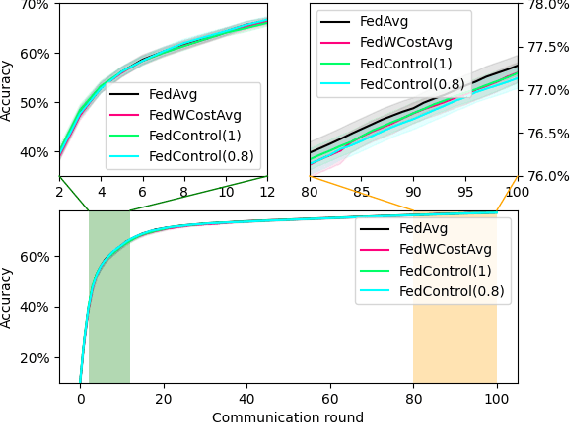
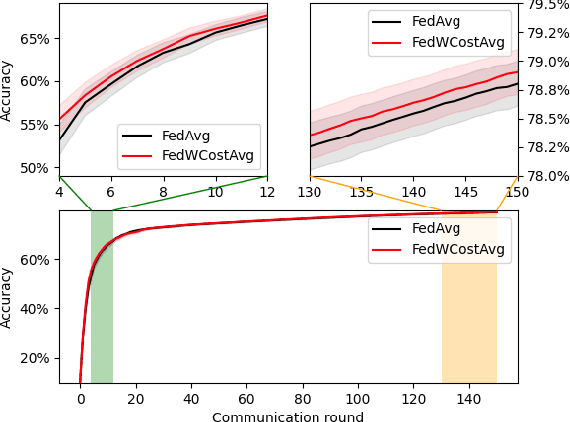
To date, the most popular federated learning algorithms use coordinate-wise averaging of the model parameters. We depart from this approach by differentiating client contributions according to the performance of local learning and its evolution. The technique is inspired from control theory and its classification performance is evaluated extensively in IID framework and compared with FedAvg.
Federated Learning Aggregation: New Robust Algorithms with Guarantees
May 22, 2022

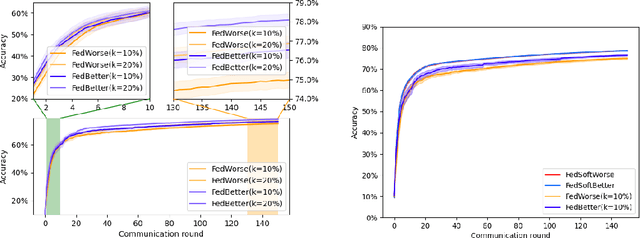
Federated Learning has been recently proposed for distributed model training at the edge. The principle of this approach is to aggregate models learned on distributed clients to obtain a new more general "average" model (FedAvg). The resulting model is then redistributed to clients for further training. To date, the most popular federated learning algorithm uses coordinate-wise averaging of the model parameters for aggregation. In this paper, we carry out a complete general mathematical convergence analysis to evaluate aggregation strategies in a federated learning framework. From this, we derive novel aggregation algorithms which are able to modify their model architecture by differentiating client contributions according to the value of their losses. Moreover, we go beyond the assumptions introduced in theory, by evaluating the performance of these strategies and by comparing them with the one of FedAvg in classification tasks in both the IID and the Non-IID framework without additional hypothesis.
Noise-Resilient Ensemble Learning using Evidence Accumulation Clustering
Oct 18, 2021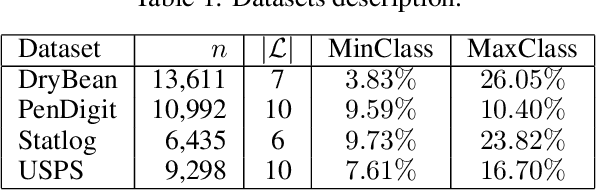
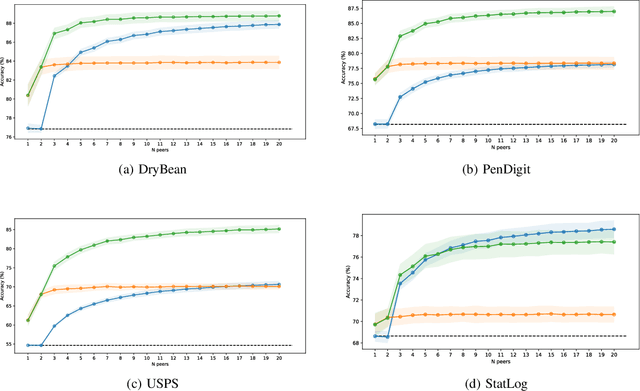
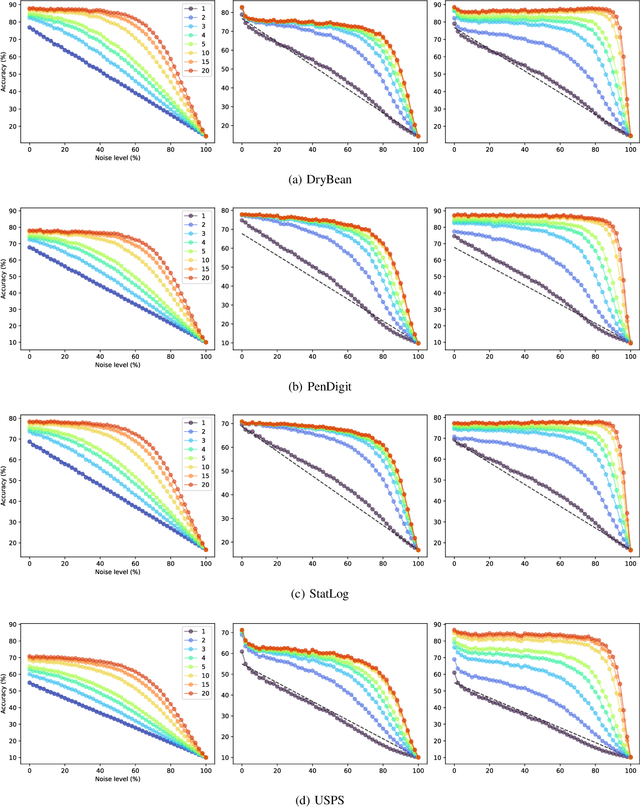
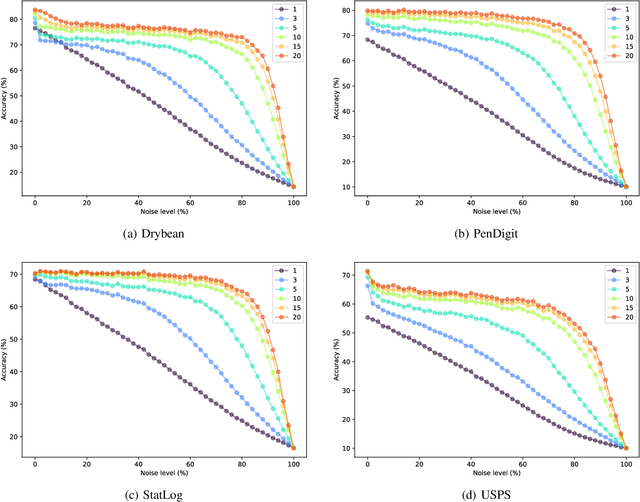
Ensemble Learning methods combine multiple algorithms performing the same task to build a group with superior quality. These systems are well adapted to the distributed setup, where each peer or machine of the network hosts one algorithm and communicate its results to its peers. Ensemble learning methods are naturally resilient to the absence of several peers thanks to the ensemble redundancy. However, the network can be corrupted, altering the prediction accuracy of a peer, which has a deleterious effect on the ensemble quality. In this paper, we propose a noise-resilient ensemble classification method, which helps to improve accuracy and correct random errors. The approach is inspired by Evidence Accumulation Clustering , adapted to classification ensembles. We compared it to the naive voter model over four multi-class datasets. Our model showed a greater resilience, allowing us to recover prediction under a very high noise level. In addition as the method is based on the evidence accumulation clustering, our method is highly flexible as it can combines classifiers with different label definitions.
Tagged Documents Co-Clustering
Oct 14, 2021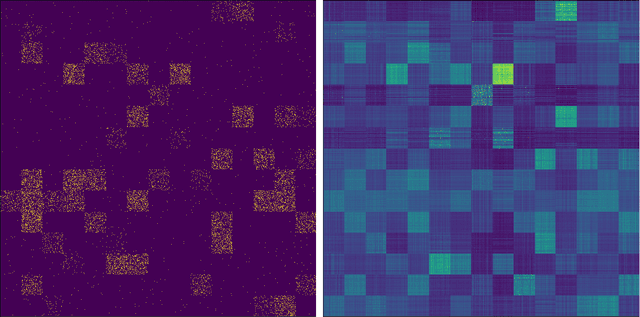
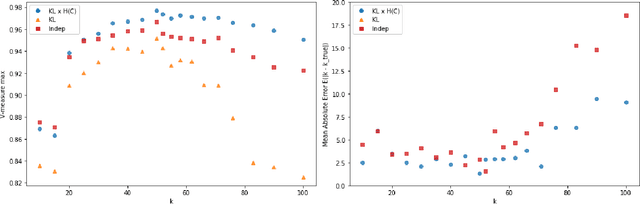
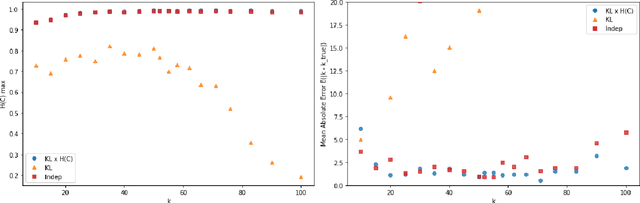

Tags are short sequences of words allowing to describe textual and non-texual resources such as as music, image or book. Tags could be used by machine information retrieval systems to access quickly a document. These tags can be used to build recommender systems to suggest similar items to a user. However, the number of tags per document is limited, and often distributed according to a Zipf law. In this paper, we propose a methodology to cluster tags into conceptual groups. Data are preprocessed to remove power-law effects and enhance the context of low-frequency words. Then, a hierarchical agglomerative co-clustering algorithm is proposed to group together the most related tags into clusters. The capabilities were evaluated on a sparse synthetic dataset and a real-world tag collection associated with scientific papers. The task being unsupervised, we propose some stopping criterion for selectecting an optimal partitioning.