 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear time Evidence Accumulation Clustering with KMeans
Nov 15, 2023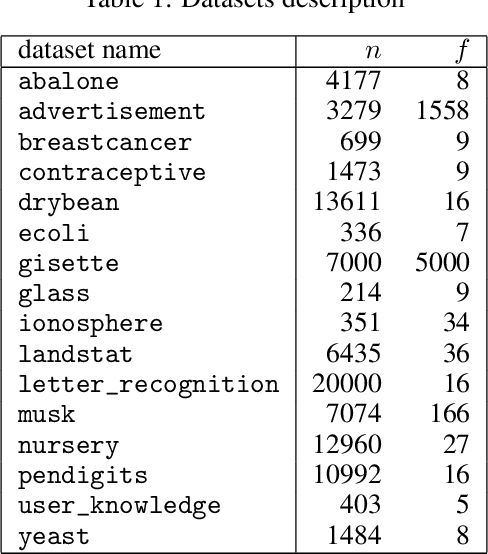

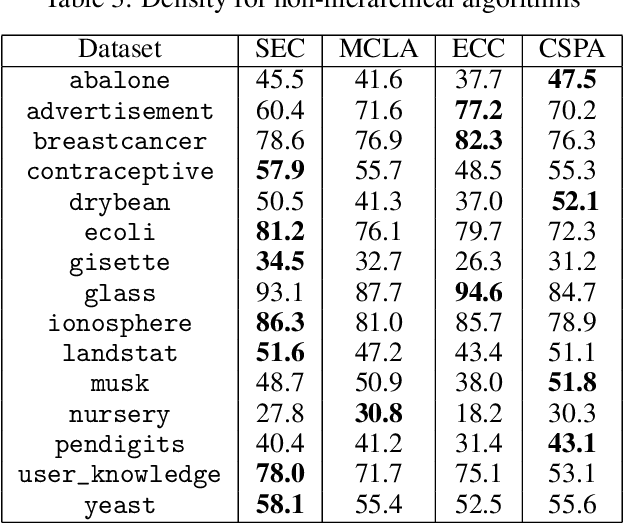
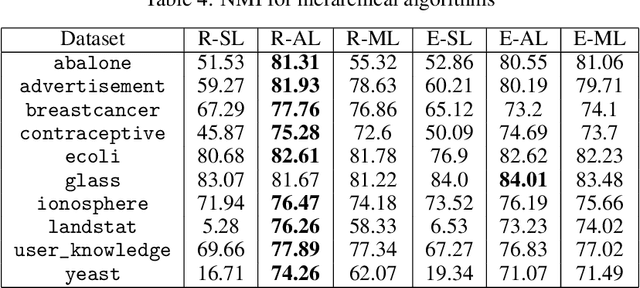
Among ensemble clustering methods, Evidence Accumulation Clustering is one of the simplest technics. In this approach, a co-association (CA) matrix representing the co-clustering frequency is built and then clustered to extract consensus clusters. Compared to other approaches, this one is simple as there is no need to find matches between clusters obtained from two different partitionings. Nevertheless, this method suffers from computational issues, as it requires to compute and store a matrix of size n x n, where n is the number of items. Due to the quadratic cost, this approach is reserved for small datasets. This work describes a trick which mimic the behavior of average linkage clustering. We found a way of computing efficiently the density of a partitioning, reducing the cost from a quadratic to linear complexity. Additionally, we proved that the k-means maximizes naturally the density. We performed experiments on several benchmark datasets where we compared the k-means and the bisecting version to other state-of-the-art consensus algorithms. The k-means results are comparable to the best state of the art in terms of NMI while keeping the computational cost low. Additionally, the k-means led to the best results in terms of density. These results provide evidence that consensus clustering can be solved with simple algorithms.
Noise-Resilient Ensemble Learning using Evidence Accumulation Clustering
Oct 18, 2021
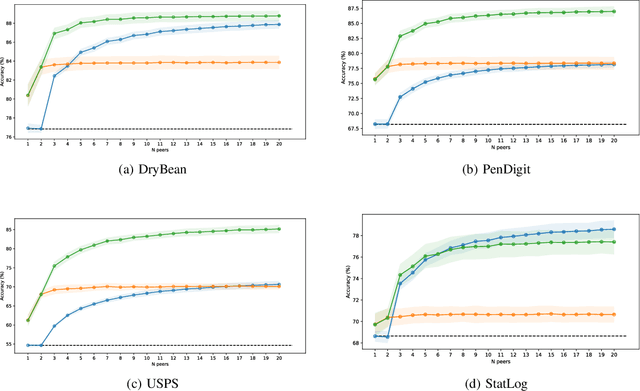
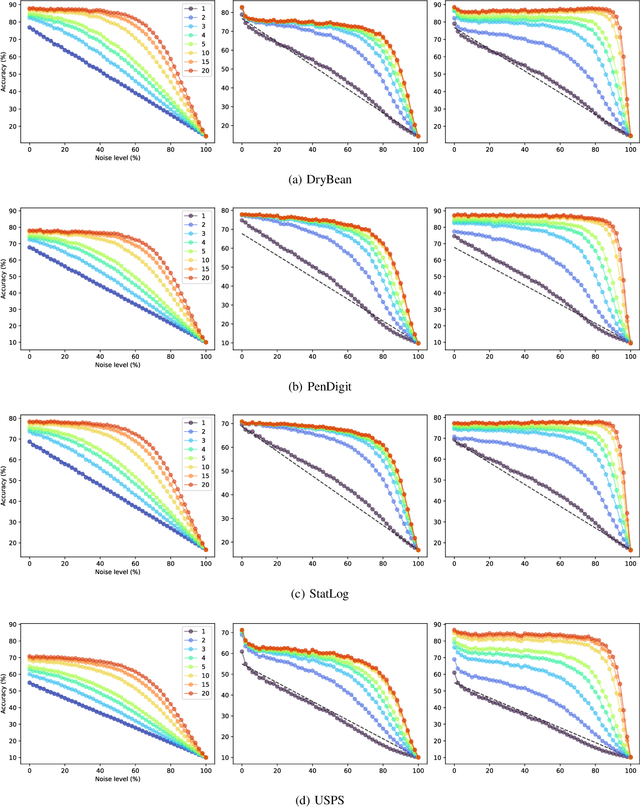
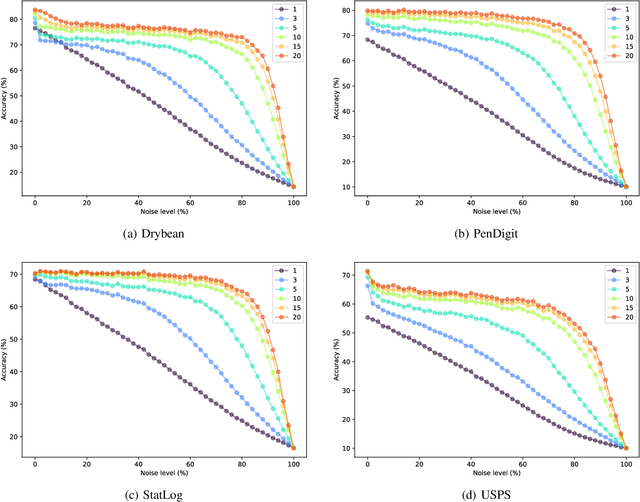
Ensemble Learning methods combine multiple algorithms performing the same task to build a group with superior quality. These systems are well adapted to the distributed setup, where each peer or machine of the network hosts one algorithm and communicate its results to its peers. Ensemble learning methods are naturally resilient to the absence of several peers thanks to the ensemble redundancy. However, the network can be corrupted, altering the prediction accuracy of a peer, which has a deleterious effect on the ensemble quality. In this paper, we propose a noise-resilient ensemble classification method, which helps to improve accuracy and correct random errors. The approach is inspired by Evidence Accumulation Clustering , adapted to classification ensembles. We compared it to the naive voter model over four multi-class datasets. Our model showed a greater resilience, allowing us to recover prediction under a very high noise level. In addition as the method is based on the evidence accumulation clustering, our method is highly flexible as it can combines classifiers with different label definitions.
Tagged Documents Co-Clustering
Oct 14, 2021
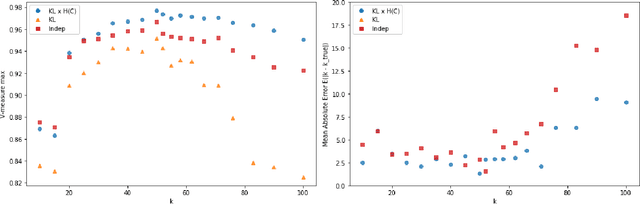
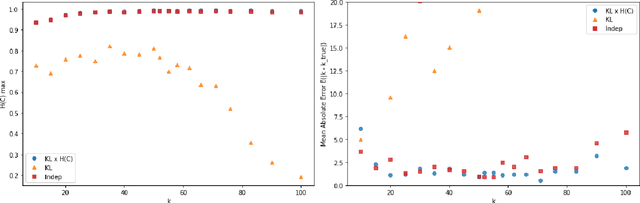

Tags are short sequences of words allowing to describe textual and non-texual resources such as as music, image or book. Tags could be used by machine information retrieval systems to access quickly a document. These tags can be used to build recommender systems to suggest similar items to a user. However, the number of tags per document is limited, and often distributed according to a Zipf law. In this paper, we propose a methodology to cluster tags into conceptual groups. Data are preprocessed to remove power-law effects and enhance the context of low-frequency words. Then, a hierarchical agglomerative co-clustering algorithm is proposed to group together the most related tags into clusters. The capabilities were evaluated on a sparse synthetic dataset and a real-world tag collection associated with scientific papers. The task being unsupervised, we propose some stopping criterion for selectecting an optimal partitioning.
Co-Embedding: Discovering Communities on Bipartite Graphs through Projection
Sep 30, 2021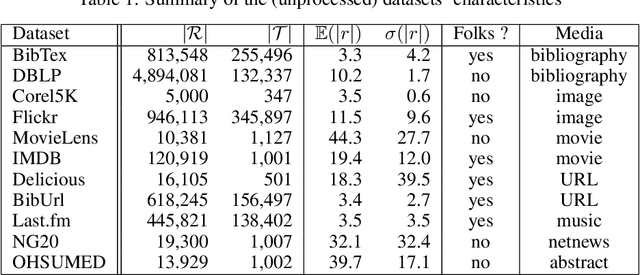
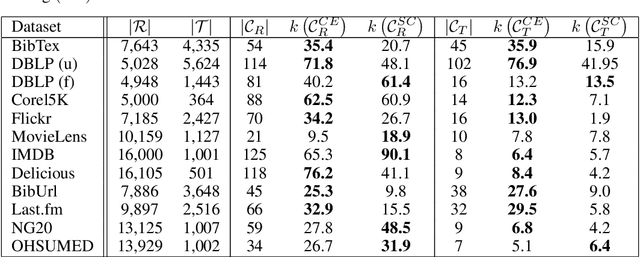
Many datasets take the form of a bipartite graph where two types of nodes are connected by relationships, like the movies watched by a user or the tags associated with a file. The partitioning of the bipartite graph could be used to fasten recommender systems, or reduce the information retrieval system's index size, by identifying groups of items with similar properties. This type of graph is often processed by algorithms using the Vector Space Model representation, where a binary vector represents an item with 0 and 1. The main problem with this representation is the dimension relatedness, like words' synonymity, which is not considered. This article proposes a co-clustering algorithm using items projection, allowing the measurement of features similarity. We evaluated our algorithm on a cluster retrieval task. Over various datasets, our algorithm produced well balanced clusters with coherent items in, leading to high retrieval scores on this task..
Index $t$-SNE: Tracking Dynamics of High-Dimensional Datasets with Coherent Embeddings
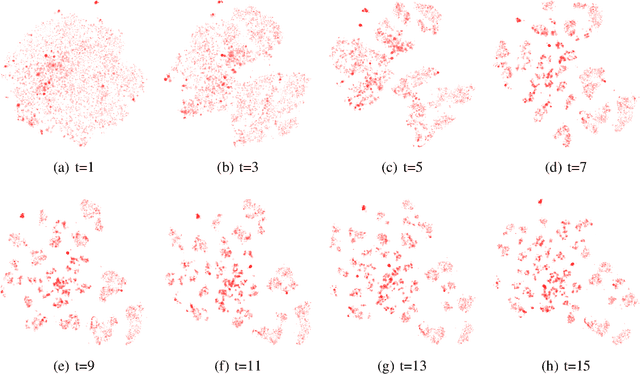
Sep 22, 2021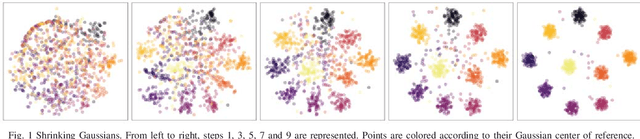


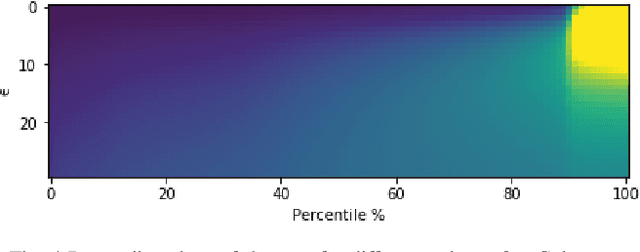
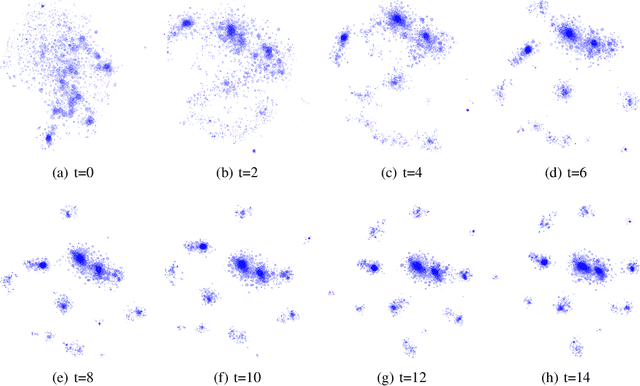
$t$-SNE is an embedding method that the data science community has widely Two interesting characteristics of t-SNE are the structure preservation property and the answer to the crowding problem, where all neighbors in high dimensional space cannot be represented correctly in low dimensional space. $t$-SNE preserves the local neighborhood, and similar items are nicely spaced by adjusting to the local density. These two characteristics produce a meaningful representation, where the cluster area is proportional to its size in number, and relationships between clusters are materialized by closeness on the embedding. This algorithm is non-parametric, therefore two initializations of the algorithm would lead to two different embedding. In a forensic approach, analysts would like to compare two or more datasets using their embedding. An approach would be to learn a parametric model over an embedding built with a subset of data. While this approach is highly scalable, points could be mapped at the same exact position, making them indistinguishable. This type of model would be unable to adapt to new outliers nor concept drift. This paper presents a methodology to reuse an embedding to create a new one, where cluster positions are preserved. The optimization process minimizes two costs, one relative to the embedding shape and the second relative to the support embedding' match. The proposed algorithm has the same complexity than the original $t$-SNE to embed new items, and a lower one when considering the embedding of a dataset sliced into sub-pieces. The method showed promising results on a real-world dataset, allowing to observe the birth, evolution and death of clusters. The proposed approach facilitates identifying significant trends and changes, which empowers the monitoring high dimensional datasets' dynamics.
* International Conference on Big Data Visual Analytics (ICBDVA), Venice, Italy, August 12-13 2021 https://publications.waset.org/pdf/10012177 Best paper award
Generating Local Maps of Science using Deep Bibliographic Coupling
Sep 21, 2021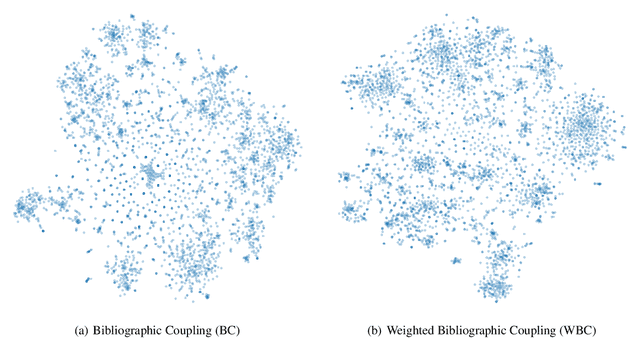
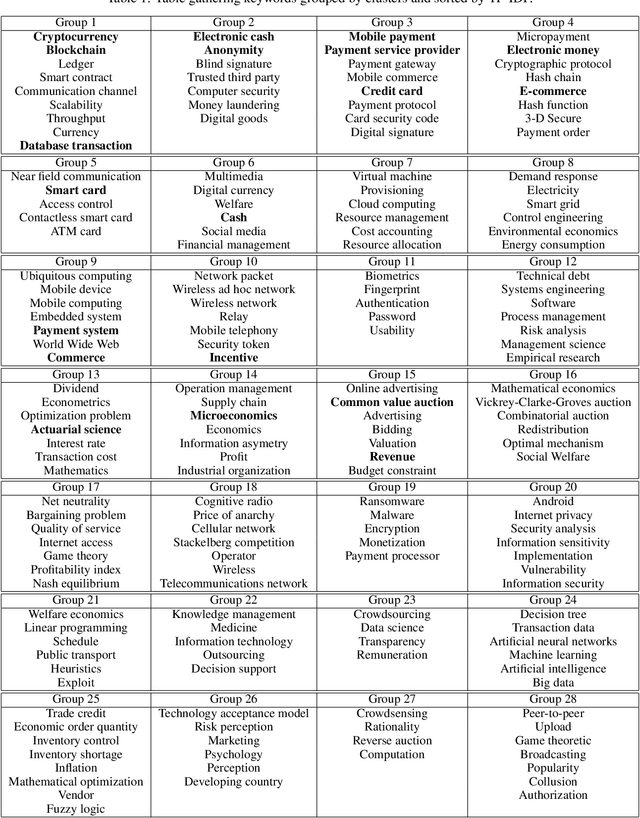
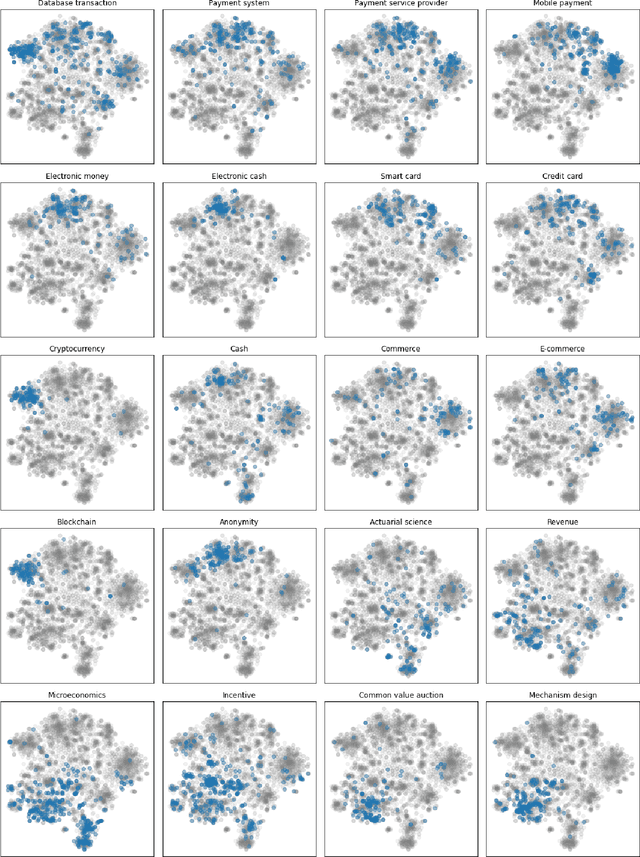
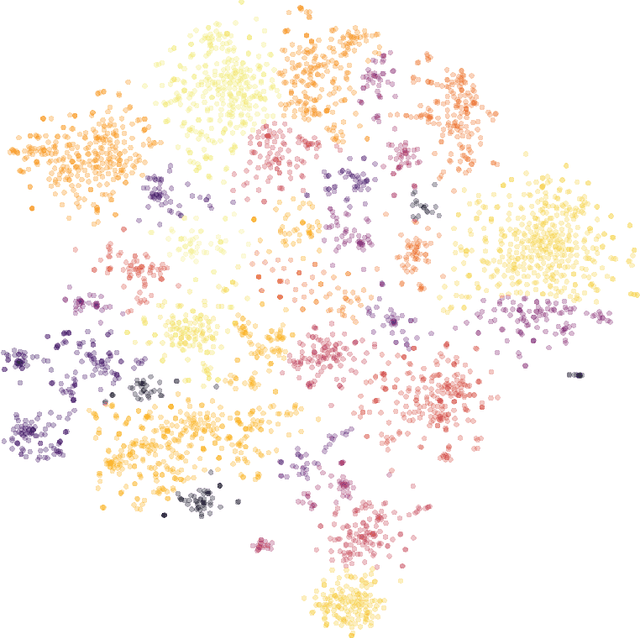
Bibliographic and co-citation coupling are two analytical methods widely used to measure the degree of similarity between scientific papers. These approaches are intuitive, easy to put into practice, and computationally cheap. Moreover, they have been used to generate a map of science, allowing visualizing research field interactions. Nonetheless, these methods do not work unless two papers share a standard reference, limiting the two papers usability with no direct connection. In this work, we propose to extend bibliographic coupling to the deep neighborhood, by using graph diffusion methods. This method allows defining similarity between any two papers, making it possible to generate a local map of science, highlighting field organization.
* Submitted to the International Conference on Scientometrics and Informetrics. Accepted as a poster. Here, long version