 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear time Evidence Accumulation Clustering with KMeans
Paper and Code
Nov 15, 2023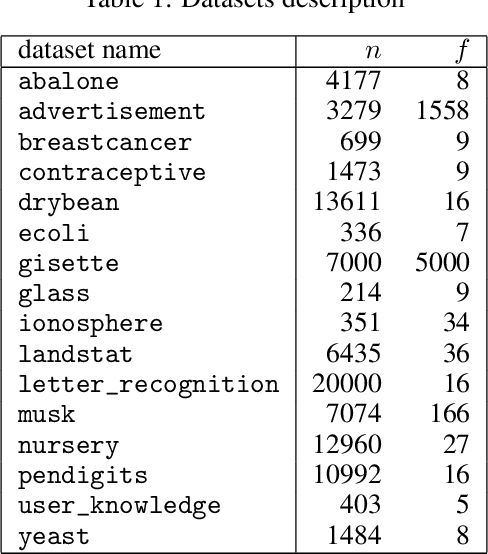

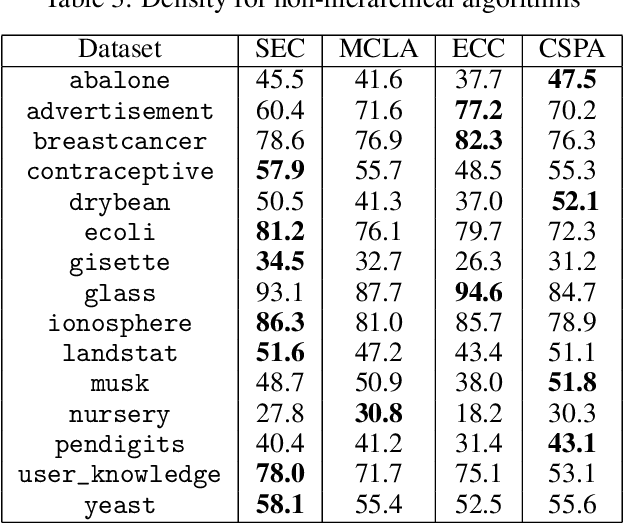
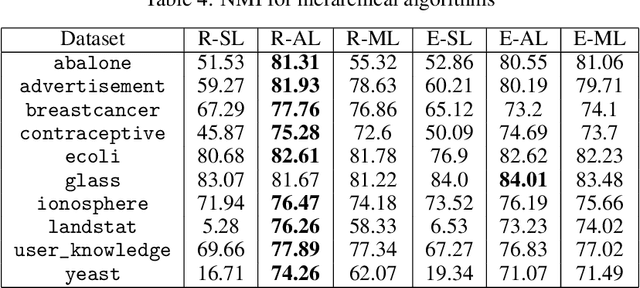
Among ensemble clustering methods, Evidence Accumulation Clustering is one of the simplest technics. In this approach, a co-association (CA) matrix representing the co-clustering frequency is built and then clustered to extract consensus clusters. Compared to other approaches, this one is simple as there is no need to find matches between clusters obtained from two different partitionings. Nevertheless, this method suffers from computational issues, as it requires to compute and store a matrix of size n x n, where n is the number of items. Due to the quadratic cost, this approach is reserved for small datasets. This work describes a trick which mimic the behavior of average linkage clustering. We found a way of computing efficiently the density of a partitioning, reducing the cost from a quadratic to linear complexity. Additionally, we proved that the k-means maximizes naturally the density. We performed experiments on several benchmark datasets where we compared the k-means and the bisecting version to other state-of-the-art consensus algorithms. The k-means results are comparable to the best state of the art in terms of NMI while keeping the computational cost low. Additionally, the k-means led to the best results in terms of density. These results provide evidence that consensus clustering can be solved with simple algorithms.