 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Embedding: Discovering Communities on Bipartite Graphs through Projection
Paper and Code
Sep 30, 2021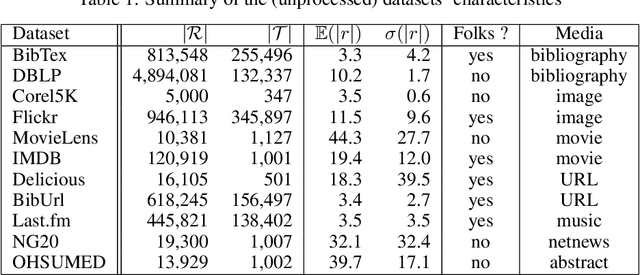
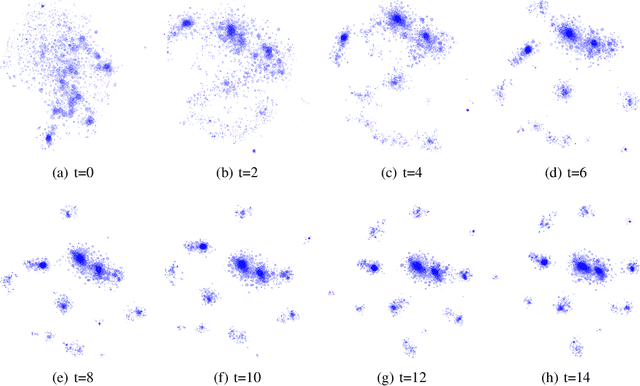
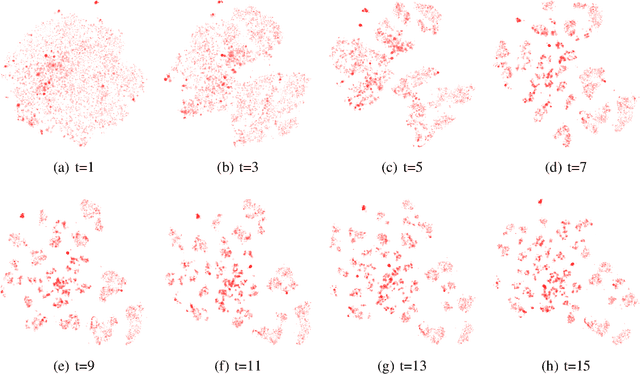
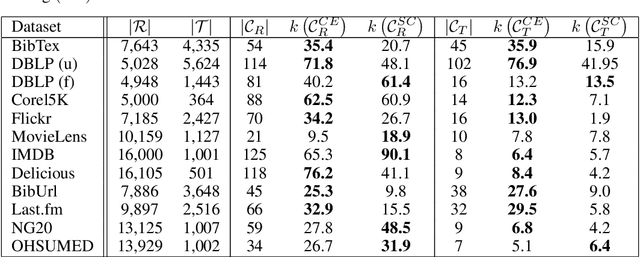
Many datasets take the form of a bipartite graph where two types of nodes are connected by relationships, like the movies watched by a user or the tags associated with a file. The partitioning of the bipartite graph could be used to fasten recommender systems, or reduce the information retrieval system's index size, by identifying groups of items with similar properties. This type of graph is often processed by algorithms using the Vector Space Model representation, where a binary vector represents an item with 0 and 1. The main problem with this representation is the dimension relatedness, like words' synonymity, which is not considered. This article proposes a co-clustering algorithm using items projection, allowing the measurement of features similarity. We evaluated our algorithm on a cluster retrieval task. Over various datasets, our algorithm produced well balanced clusters with coherent items in, leading to high retrieval scores on this task..