 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN Explainability with Multivector Tucker Saliency Maps for Self-Supervised Models
Oct 30, 2024



Interpreting the decisions of Convolutional Neural Networks (CNNs) is essential for understanding their behavior, yet explainability remains a significant challenge, particularly for self-supervised models. Most existing methods for generating saliency maps rely on ground truth labels, restricting their use to supervised tasks. EigenCAM is the only notable label-independent alternative, leveraging Singular Value Decomposition to generate saliency maps applicable across CNN models, but it does not fully exploit the tensorial structure of feature maps. In this work, we introduce the Tucker Saliency Map (TSM) method, which applies Tucker tensor decomposition to better capture the inherent structure of feature maps, producing more accurate singular vectors and values. These are used to generate high-fidelity saliency maps, effectively highlighting objects of interest in the input. We further extend EigenCAM and TSM into multivector variants -Multivec-EigenCAM and Multivector Tucker Saliency Maps (MTSM)- which utilize all singular vectors and values, further improving saliency map quality. Quantitative evaluations on supervised classification models demonstrate that TSM, Multivec-EigenCAM, and MTSM achieve competitive performance with label-dependent methods. Moreover, TSM enhances explainability by approximately 50% over EigenCAM for both supervised and self-supervised models. Multivec-EigenCAM and MTSM further advance state-of-the-art explainability performance on self-supervised models, with MTSM achieving the best results.
Sampling From Autoencoders' Latent Space via Quantization And Probability Mass Function Concepts
Aug 21, 2023

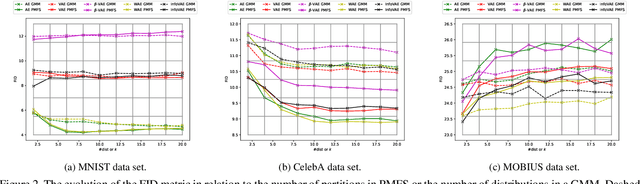

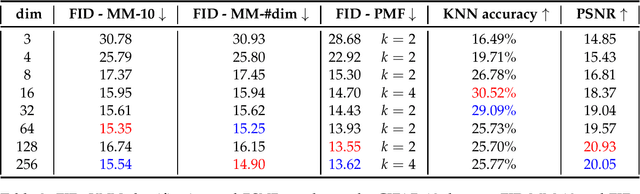
In this study, we focus on sampling from the latent space of generative models built upon autoencoders so as the reconstructed samples are lifelike images. To do to, we introduce a novel post-training sampling algorithm rooted in the concept of probability mass functions, coupled with a quantization process. Our proposed algorithm establishes a vicinity around each latent vector from the input data and then proceeds to draw samples from these defined neighborhoods. This strategic approach ensures that the sampled latent vectors predominantly inhabit high-probability regions, which, in turn, can be effectively transformed into authentic real-world images. A noteworthy point of comparison for our sampling algorithm is the sampling technique based on Gaussian mixture models (GMM), owing to its inherent capability to represent clusters. Remarkably, we manage to improve the time complexity from the previous $\mathcal{O}(n\times d \times k \times i)$ associated with GMM sampling to a much more streamlined $\mathcal{O}(n\times d)$, thereby resulting in substantial speedup during runtime. Moreover, our experimental results, gauged through the Fr\'echet inception distance (FID) for image generation, underscore the superior performance of our sampling algorithm across a diverse range of models and datasets. On the MNIST benchmark dataset, our approach outperforms GMM sampling by yielding a noteworthy improvement of up to $0.89$ in FID value. Furthermore, when it comes to generating images of faces and ocular images, our approach showcases substantial enhancements with FID improvements of $1.69$ and $0.87$ respectively, as compared to GMM sampling, as evidenced on the CelebA and MOBIUS datasets. Lastly, we substantiate our methodology's efficacy in estimating latent space distributions in contrast to GMM sampling, particularly through the lens of the Wasserstein distance.
Simplex Autoencoders
Jan 16, 2023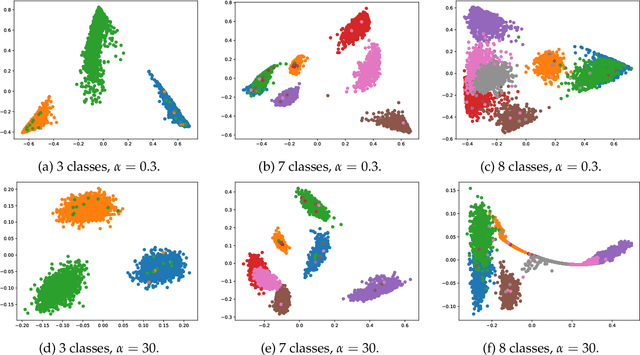
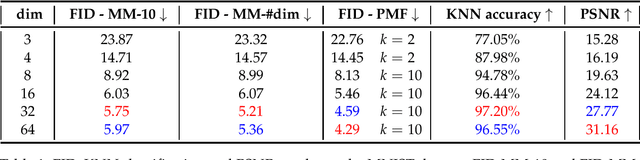
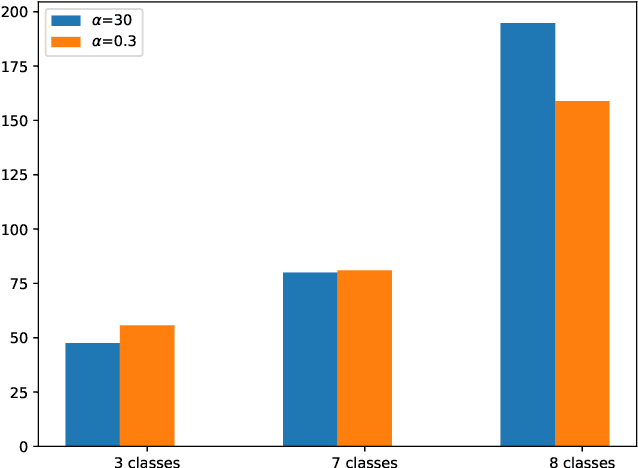
Synthetic data generation is increasingly important due to privacy concerns. While Autoencoder-based approaches have been widely used for this purpose, sampling from their latent spaces can be challenging. Mixture models are currently the most efficient way to sample from these spaces. In this work, we propose a new approach that models the latent space of an Autoencoder as a simplex, allowing for a novel heuristic for determining the number of components in the mixture model. This heuristic is independent of the number of classes and produces comparable results. We also introduce a sampling method based on probability mass functions, taking advantage of the compactness of the latent space. We evaluate our approaches on a synthetic dataset and demonstrate their performance on three benchmark datasets: MNIST, CIFAR-10, and Celeba. Our approach achieves an image generation FID of 4.29, 13.55, and 11.90 on the MNIST, CIFAR-10, and Celeba datasets, respectively. The best AE FID results to date on those datasets are respectively 6.3, 85.3 and 35.6 we hence substantially improve those figures (the lower is the FID the better). However, AEs are not the best performing algorithms on the concerned datasets and all FID records are currently held by GANs. While we do not perform better than GANs on CIFAR and Celeba we do manage to squeeze-out a non-negligible improvement (of 0.21) over the current GAN-held record for the MNIST dataset.
Improving Auto-Encoders' self-supervised image classification using pseudo-labelling via data augmentation and the perceptual loss
Dec 06, 2020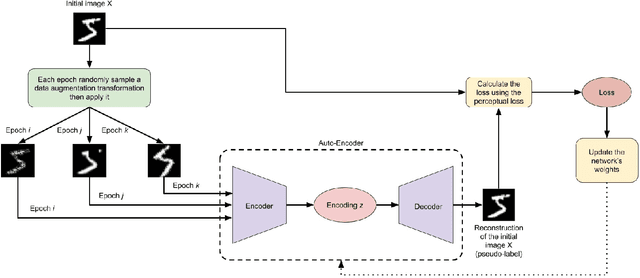

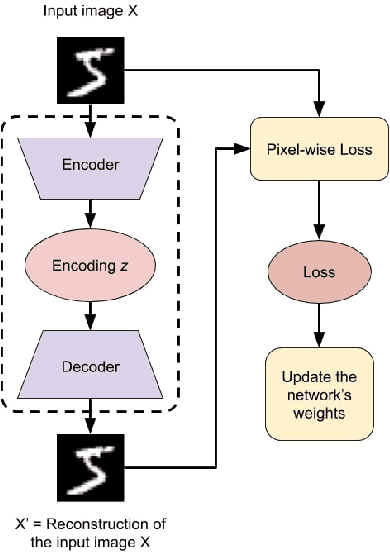
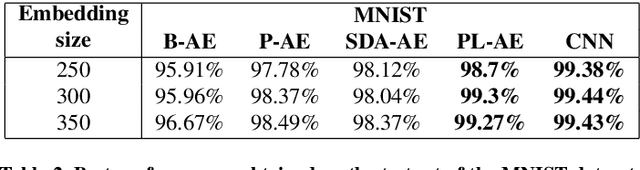
In this paper, we introduce a novel method to pseudo-label unlabelled images and train an Auto-Encoder to classify them in a self-supervised manner that allows for a high accuracy and consistency across several datasets. The proposed method consists of first applying a randomly sampled set of data augmentation transformations to each training image. As a result, each initial image can be considered as a pseudo-label to its corresponding augmented ones. Then, an Auto-Encoder is used to learn the mapping between each set of the augmented images and its corresponding pseudo-label. Furthermore, the perceptual loss is employed to take into consideration the existing dependencies between the pixels in the same neighbourhood of an image. This combination encourages the encoder to output richer encodings that are highly informative of the input's class. Consequently, the Auto-Encoder's performance on unsupervised image classification is improved both in termes of stability and accuracy becoming more uniform and more consistent across all tested datasets. Previous state-of-the-art accuracy on the MNIST, CIFAR-10 and SVHN datasets is improved by 0.3\%, 3.11\% and 9.21\% respectively.