 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Auto-Encoders' self-supervised image classification using pseudo-labelling via data augmentation and the perceptual loss
Paper and Code
Dec 06, 2020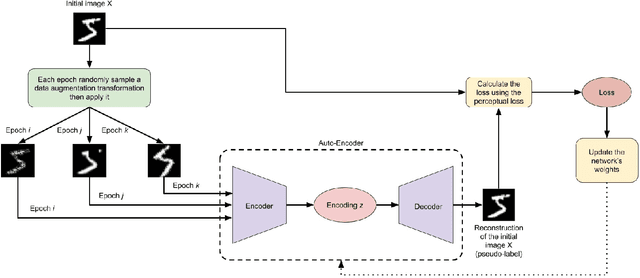

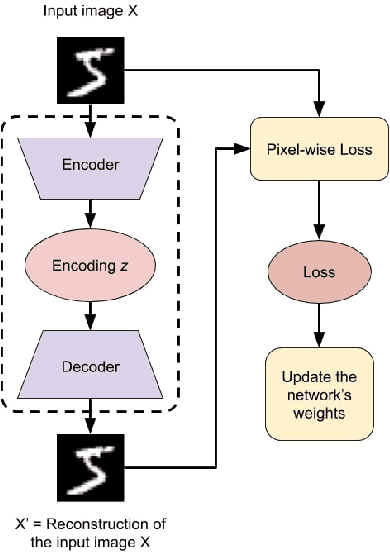
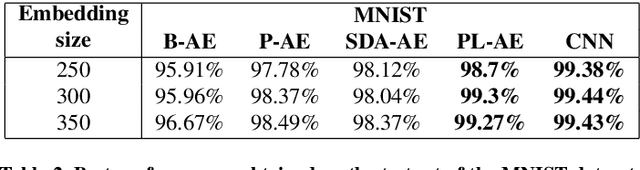
In this paper, we introduce a novel method to pseudo-label unlabelled images and train an Auto-Encoder to classify them in a self-supervised manner that allows for a high accuracy and consistency across several datasets. The proposed method consists of first applying a randomly sampled set of data augmentation transformations to each training image. As a result, each initial image can be considered as a pseudo-label to its corresponding augmented ones. Then, an Auto-Encoder is used to learn the mapping between each set of the augmented images and its corresponding pseudo-label. Furthermore, the perceptual loss is employed to take into consideration the existing dependencies between the pixels in the same neighbourhood of an image. This combination encourages the encoder to output richer encodings that are highly informative of the input's class. Consequently, the Auto-Encoder's performance on unsupervised image classification is improved both in termes of stability and accuracy becoming more uniform and more consistent across all tested datasets. Previous state-of-the-art accuracy on the MNIST, CIFAR-10 and SVHN datasets is improved by 0.3\%, 3.11\% and 9.21\% respectively.