 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplex Autoencoders
Paper and Code
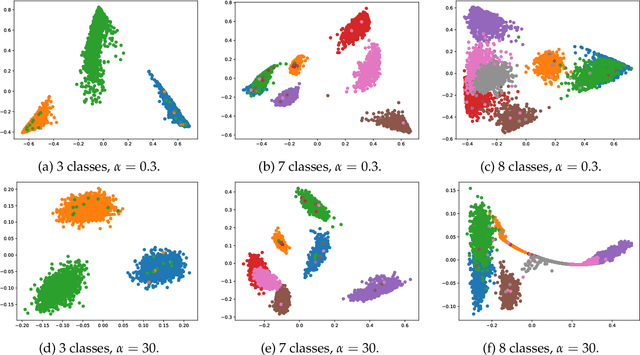
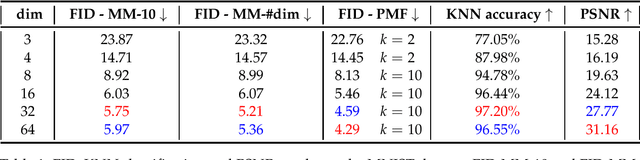
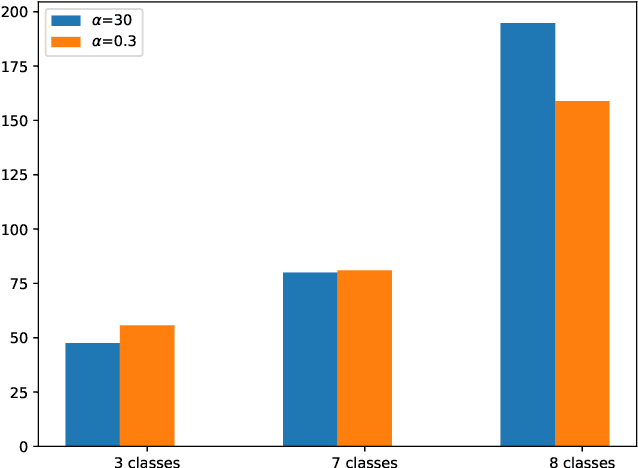
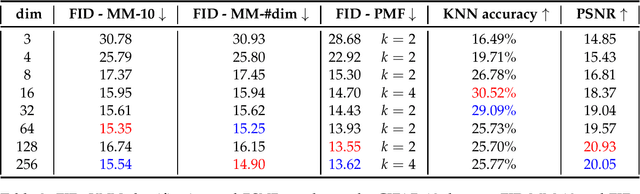
Synthetic data generation is increasingly important due to privacy concerns. While Autoencoder-based approaches have been widely used for this purpose, sampling from their latent spaces can be challenging. Mixture models are currently the most efficient way to sample from these spaces. In this work, we propose a new approach that models the latent space of an Autoencoder as a simplex, allowing for a novel heuristic for determining the number of components in the mixture model. This heuristic is independent of the number of classes and produces comparable results. We also introduce a sampling method based on probability mass functions, taking advantage of the compactness of the latent space. We evaluate our approaches on a synthetic dataset and demonstrate their performance on three benchmark datasets: MNIST, CIFAR-10, and Celeba. Our approach achieves an image generation FID of 4.29, 13.55, and 11.90 on the MNIST, CIFAR-10, and Celeba datasets, respectively. The best AE FID results to date on those datasets are respectively 6.3, 85.3 and 35.6 we hence substantially improve those figures (the lower is the FID the better). However, AEs are not the best performing algorithms on the concerned datasets and all FID records are currently held by GANs. While we do not perform better than GANs on CIFAR and Celeba we do manage to squeeze-out a non-negligible improvement (of 0.21) over the current GAN-held record for the MNIST dataset.