 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Fully Interpretable and More Scalable RSA Model for Metaphor Understanding
Apr 03, 2024The Rational Speech Act (RSA) model provides a flexible framework to model pragmatic reasoning in computational terms. However, state-of-the-art RSA models are still fairly distant from modern machine learning techniques and present a number of limitations related to their interpretability and scalability. Here, we introduce a new RSA framework for metaphor understanding that addresses these limitations by providing an explicit formula - based on the mutually shared information between the speaker and the listener - for the estimation of the communicative goal and by learning the rationality parameter using gradient-based methods. The model was tested against 24 metaphors, not limited to the conventional $\textit{John-is-a-shark}$ type. Results suggest an overall strong positive correlation between the distributions generated by the model and the interpretations obtained from the human behavioral data, which increased when the intended meaning capitalized on properties that were inherent to the vehicle concept. Overall, findings suggest that metaphor processing is well captured by a typicality-based Bayesian model, even when more scalable and interpretable, opening up possible applications to other pragmatic phenomena and novel uses for increasing Large Language Models interpretability. Yet, results highlight that the more creative nuances of metaphorical meaning, not strictly encoded in the lexical concepts, are a challenging aspect for machines.
Tackling Computational Heterogeneity in FL: A Few Theoretical Insights
Jul 12, 2023



The future of machine learning lies in moving data collection along with training to the edge. Federated Learning, for short FL, has been recently proposed to achieve this goal. The principle of this approach is to aggregate models learned over a large number of distributed clients, i.e., resource-constrained mobile devices that collect data from their environment, to obtain a new more general model. The latter is subsequently redistributed to clients for further training. A key feature that distinguishes federated learning from data-center-based distributed training is the inherent heterogeneity. In this work, we introduce and analyse a novel aggregation framework that allows for formalizing and tackling computational heterogeneity in federated optimization, in terms of both heterogeneous data and local updates. Proposed aggregation algorithms are extensively analyzed from a theoretical, and an experimental prospective.
Adversarial Path Planning for Optimal Camera Positioning
Feb 26, 2023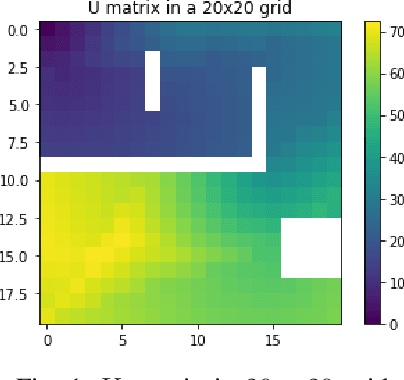

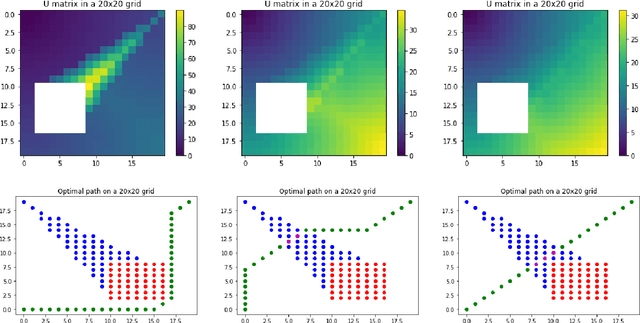

The use of visual sensors is flourishing, driven among others by the several applications in detection and prevention of crimes or dangerous events. While the problem of optimal camera placement for total coverage has been solved for a decade or so, that of the arrangement of cameras maximizing the recognition of objects "in-transit" is still open. The objective of this paper is to attack this problem by providing an adversarial method of proven optimality based on the resolution of Hamilton-Jacobi equations. The problem is attacked by first assuming the perspective of an adversary, i.e. computing explicitly the path minimizing the probability of detection and the quality of reconstruction. Building on this result, we introduce an optimality measure for camera configurations and perform a simulated annealing algorithm to find the optimal camera placement.
FedControl: When Control Theory Meets Federated Learning
May 27, 2022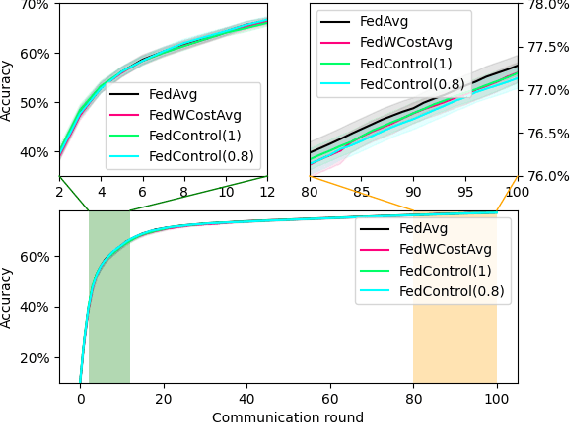
To date, the most popular federated learning algorithms use coordinate-wise averaging of the model parameters. We depart from this approach by differentiating client contributions according to the performance of local learning and its evolution. The technique is inspired from control theory and its classification performance is evaluated extensively in IID framework and compared with FedAvg.
Federated Learning Aggregation: New Robust Algorithms with Guarantees
May 22, 2022

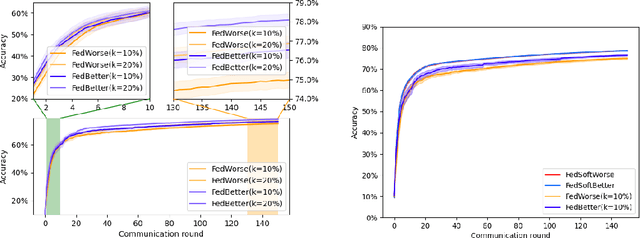
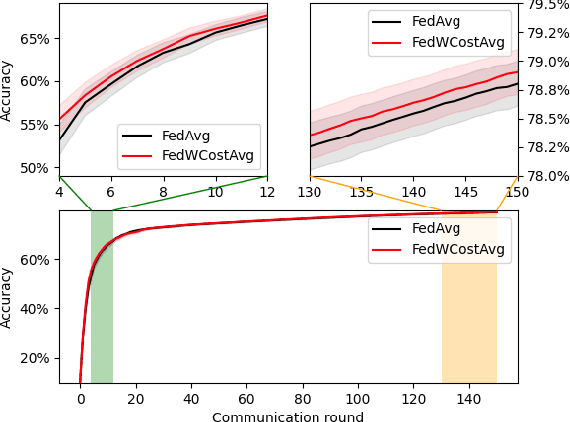
Federated Learning has been recently proposed for distributed model training at the edge. The principle of this approach is to aggregate models learned on distributed clients to obtain a new more general "average" model (FedAvg). The resulting model is then redistributed to clients for further training. To date, the most popular federated learning algorithm uses coordinate-wise averaging of the model parameters for aggregation. In this paper, we carry out a complete general mathematical convergence analysis to evaluate aggregation strategies in a federated learning framework. From this, we derive novel aggregation algorithms which are able to modify their model architecture by differentiating client contributions according to the value of their losses. Moreover, we go beyond the assumptions introduced in theory, by evaluating the performance of these strategies and by comparing them with the one of FedAvg in classification tasks in both the IID and the Non-IID framework without additional hypothesis.