 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling Computational Heterogeneity in FL: A Few Theoretical Insights
Jul 12, 2023



The future of machine learning lies in moving data collection along with training to the edge. Federated Learning, for short FL, has been recently proposed to achieve this goal. The principle of this approach is to aggregate models learned over a large number of distributed clients, i.e., resource-constrained mobile devices that collect data from their environment, to obtain a new more general model. The latter is subsequently redistributed to clients for further training. A key feature that distinguishes federated learning from data-center-based distributed training is the inherent heterogeneity. In this work, we introduce and analyse a novel aggregation framework that allows for formalizing and tackling computational heterogeneity in federated optimization, in terms of both heterogeneous data and local updates. Proposed aggregation algorithms are extensively analyzed from a theoretical, and an experimental prospective.
FedControl: When Control Theory Meets Federated Learning
May 27, 2022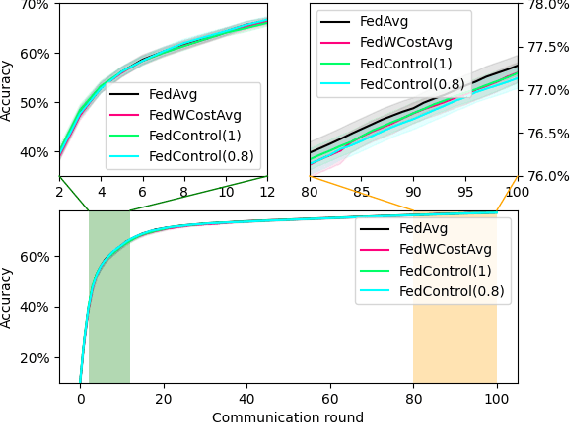
To date, the most popular federated learning algorithms use coordinate-wise averaging of the model parameters. We depart from this approach by differentiating client contributions according to the performance of local learning and its evolution. The technique is inspired from control theory and its classification performance is evaluated extensively in IID framework and compared with FedAvg.
Federated Learning Aggregation: New Robust Algorithms with Guarantees
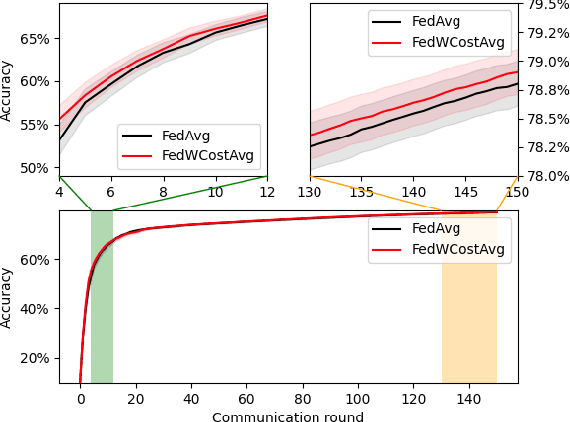
May 22, 2022

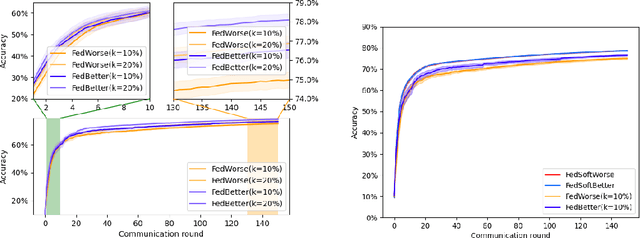
Federated Learning has been recently proposed for distributed model training at the edge. The principle of this approach is to aggregate models learned on distributed clients to obtain a new more general "average" model (FedAvg). The resulting model is then redistributed to clients for further training. To date, the most popular federated learning algorithm uses coordinate-wise averaging of the model parameters for aggregation. In this paper, we carry out a complete general mathematical convergence analysis to evaluate aggregation strategies in a federated learning framework. From this, we derive novel aggregation algorithms which are able to modify their model architecture by differentiating client contributions according to the value of their losses. Moreover, we go beyond the assumptions introduced in theory, by evaluating the performance of these strategies and by comparing them with the one of FedAvg in classification tasks in both the IID and the Non-IID framework without additional hypothesis.